基于梯度的优化问题中不可导操作的处理方法总结
本文目录
- 1 引言
- 2 函数光滑化的方法
-
- 2.1 概念定义
- 2.2 人工选取光滑近似
-
- 2.2.1 m a x ( x 1 , x 2 , . . . , x n ) ≈ ln ( ∑ i = 1 n e x i ) max(x_1,x_2,...,x_n) \approx \ln(\sum_{i=1}^n e^{x_i}) max(x1,x2,...,xn)≈ln(∑i=1nexi)
- 2.2.2 o n e h o t ( arg max ( x 1 , x 2 , . . . , x n ) ) ≈ s o f t m a x ( x 1 , x 2 , . . . , x n ) onehot(\argmax(x_1,x_2,...,x_n) )\approx softmax(x_1,x_2,...,x_n) onehot(argmax(x1,x2,...,xn))≈softmax(x1,x2,...,xn)
- 2.2.3 a r g m a x ( x ) ≈ ∑ i = 1 n i × s o f t m a x ( x ) i argmax(x) \approx \sum_{i=1}^n i \times softmax(x)_i argmax(x)≈∑i=1ni×softmax(x)i
- 2.2.4 accuracy ≈ 1 S ∑ x ∈ S < 1 y ( x ) , p ( x ) > \text {accuracy} \approx \frac{1}{S} \sum_{x \in S} <1_y(x), p(x)> accuracy≈S1∑x∈S<1y(x),p(x)>
- 2.2.5 F1-score ≈ 2 ∑ x ∈ S p ( x ) y ( x ) ∑ x ∈ S p ( x ) + y ( x ) \text {F1-score} \approx \frac{2\sum_{x\in S} p(x) y(x)}{\sum_{x\in S} p(x) + y(x)} F1-score≈∑x∈Sp(x)+y(x)2∑x∈Sp(x)y(x)
- 2.3 使用冲激函数近似
- 3 不可导点的次梯度方法
- 4 采样的重参数化方法
-
- 4.1 对连续分布采样的重参数化
- 4.2 对离散分布采样的重参数化(Gumbel-softmax)
- 5 参考资料
1 引言
一些不可导的场景:
- 深度学习中大规模参数的优化方法都是基于梯度的,因此要求模型中的操作都是可导的。然而机器学习模型中经常存在非全空间可导的函数或操作,比如常用的ReLU激活函数、argmax操作、卷积中的Max Pooling操作等。
- 许多机器学习任务的评价指标是离散的,如分类任务的评价指标是准确率;而常见的损失函数是连续的,如分类任务使用交叉熵损失。损失函数的降低和评价指标的提升并不是完全的单调关系,但不能直接使用评价指标作为损失函数,因为评价指标是不可导的。
- 在强化学习任务中,假设网络输出的三维向量的分量代表三个动作(比如前进、停留、后退)在下一步的收益,那么下一步我们就会选择收益最大的动作继续执行。选择收益最大的动作作为输出动作,在神经网络中这种取法有个问题是不能计算梯度,也就不能更新网络。
- 在最优化问题中,求函数极值需要求导,有时目标函数是不可导的,比如函数中存在最大值函数 m a x ( x ) max(x) max(x),希望将这些不可导函数用可导函数近似。
基于以上场景,需要寻求对不可导函数近似为可导函数的方法或者其梯度的近似方法。
2 函数光滑化的方法
2.1 概念定义
光滑函数(smooth function)是指在其定义域内无穷阶数连续可导的函数。
函数的光滑化是指对于一个非光滑函数 f f f,寻找一个光滑函数 f μ f_\mu fμ, 使得 f μ f_\mu fμ是 f f f的光滑逼近。一个非光滑函数是否可光滑化(smoothable)定义如下:
给定一个凸函数 f f f,如果存在一个凸函数 f μ f_\mu fμ,使得满足:
(1) f μ f_\mu fμ是 α μ \frac{\alpha}{\mu} μα光滑的;
(2) f μ ( x ) ≤ f ( x ) ≤ f μ + β μ f_\mu(x) \leq f(x) \leq f_\mu + \beta\mu fμ(x)≤f(x)≤fμ+βμ;
我们称其为 ( α , β ) − smoothable (\alpha , \beta)-\text{smoothable} (α,β)−smoothable,并且称 f μ f_\mu fμ为 f f f在参数 ( α , β ) (\alpha , \beta) (α,β)下的 1 μ \frac{1}{\mu} μ1光滑逼近。
条件(1)要求 f μ f_\mu fμ是光滑的,并指定光滑系数 α μ \frac{\alpha}{\mu} μα(越小越光滑)。条件(2)要求 f μ f_\mu fμ从下方逼近 f f f,并且制定逼近的最大差异 β μ \beta\mu βμ。参数 μ \mu μ越大,则函数 f μ f_\mu fμ越光滑,但与 f f f的差异也就越大。
2.2 人工选取光滑近似
2.2.1 m a x ( x 1 , x 2 , . . . , x n ) ≈ ln ( ∑ i = 1 n e x i ) max(x_1,x_2,...,x_n) \approx \ln(\sum_{i=1}^n e^{x_i}) max(x1,x2,...,xn)≈ln(∑i=1nexi)
推导过程
以max(x, y)为例。
当 x ≥ 0 , y ≥ 0 x\geq 0,y \geq 0 x≥0,y≥0时,有最大值函数的近似公式:
max ( x , y ) = 1 2 ( ∣ x + y ∣ + ∣ x − y ∣ ) \max(x, y) = \frac{1}{2}(|x+y| + |x-y|) max(x,y)=21(∣x+y∣+∣x−y∣)
因此问题转化为寻找绝对值函数 f ( x ) = ∣ x ∣ f(x) = |x| f(x)=∣x∣的光滑近似,该函数可以的导数可以用单位阶跃函数 θ ( x ) \theta(x) θ(x)表示,即:
f ′ ( x ) = 2 θ ( x ) − 1 f'(x) = 2\theta(x)-1 f′(x)=2θ(x)−1
单位阶跃函数 θ ( x ) \theta(x) θ(x)具有近似函数 θ ( x ) = lim k → ∞ 1 1 + e − k x \theta(x)=\lim_{k \rarr \infin} \frac{1}{1+e^{-kx}} θ(x)=limk→∞1+e−kx1,因此:
f ( x ) = ∫ [ 2 θ ( x ) − 1 ] d x = ∫ [ 2 1 1 + e − k x − 1 ] d x = 2 k ln ( 1 + e k x ) − x = 2 k ln ( 1 + e k x ) − 2 k ln e k x 2 = 1 k ln ( e k x + e − k x + 2 ) \begin{alignat}{2} f(x) &= \int [2\theta(x)-1]dx \\ &= \int [2 \frac{1}{1+e^{-kx}}-1]dx \\ &= \frac{2}{k} \ln (1+e^{kx}) - x \\ &= \frac{2}{k} \ln (1+e^{kx}) - \frac{2}{k} \ln e^{\frac{kx}{2}} \\ &= \frac{1}{k} \ln (e^{kx} + e^{-kx} + 2) \end{alignat} f(x)=∫[2θ(x)−1]dx=∫[21+e−kx1−1]dx=k2ln(1+ekx)−x=k2ln(1+ekx)−k2lne2kx=k1ln(ekx+e−kx+2)
当k足够大时,常数2可以省略。因此 ∣ x ∣ = lim k → ∞ 1 k ln ( e k x + e − k x ) |x|= \lim_{k \rarr \infin} \frac{1}{k} \ln (e^{kx} + e^{-kx}) ∣x∣=limk→∞k1ln(ekx+e−kx),进一步推得:
max ( x , y ) = 1 2 ( ∣ x + y ∣ + ∣ x − y ∣ ) = lim k → ∞ 1 2 k ln ( e 2 k x + e 2 k y + e − 2 k x + e − 2 k y ) = lim k → ∞ 1 k ln ( e k x + e k y + e − k x + e − k y ) \begin{alignat}{2} \max(x, y) &= \frac{1}{2}(|x+y| + |x-y|) \\ &= \lim_{k \rarr \infin} \frac{1}{2k} \ln (e^{2kx} + e^{2ky} + e^{-2kx} + e^{-2ky}) \\ &= \lim_{k \rarr \infin} \frac{1}{k} \ln (e^{kx} + e^{ky} + e^{-kx} + e^{-ky}) \end{alignat} max(x,y)=21(∣x+y∣+∣x−y∣)=k→∞lim2k1ln(e2kx+e2ky+e−2kx+e−2ky)=k→∞limk1ln(ekx+eky+e−kx+e−ky)
注意前提条件时 x ≥ 0 , y ≥ 0 x\geq 0,y \geq 0 x≥0,y≥0,因此 e − k x + e − k y e^{-kx} + e^{-ky} e−kx+e−ky可丢弃。最终max函数近似为:
max ( x , y ) = lim k → ∞ 1 k ln ( e k x + e k y ) \max(x, y)= \lim_{k \rarr \infin} \frac{1}{k} \ln (e^{kx} + e^{ky} ) max(x,y)=k→∞limk1ln(ekx+eky)
注意该式子在x,y取负数时仍成立,因此可以推广到多个变量的最大值函数:
max ( x 1 , x 2 , . . . , x n ) = lim k → ∞ 1 k ln ( ∑ i = 1 n e k x i ) \max(x_1, x_2,...,x_n)= \lim_{k \rarr \infin} \frac{1}{k} \ln (\sum_{i=1}^n e^{kx_i} ) max(x1,x2,...,xn)=k→∞limk1ln(i=1∑nekxi)
通常设置k=1, 则有:
max ( x 1 , x 2 , . . . , x n ) ≈ ln ( ∑ i = 1 n e k x i ) \max(x_1, x_2,...,x_n)\approx \ln (\sum_{i=1}^n e^{kx_i} ) max(x1,x2,...,xn)≈ln(i=1∑nekxi)
2.2.2 o n e h o t ( arg max ( x 1 , x 2 , . . . , x n ) ) ≈ s o f t m a x ( x 1 , x 2 , . . . , x n ) onehot(\argmax(x_1,x_2,...,x_n) )\approx softmax(x_1,x_2,...,x_n) onehot(argmax(x1,x2,...,xn))≈softmax(x1,x2,...,xn)
推导过程
o n e h o t ( a r g m a x ( x ) ) onehot(argmax(x)) onehot(argmax(x))表示求序列 x = [ x 1 , x 2 , . . . , x n ] x=[x_1,x_2,...,x_n] x=[x1,x2,...,xn]中最大值所在的位置的onehot编码。考虑向量:
x ′ = [ x 1 , x 2 , . . . , x n ] − max ( x 1 , x 2 , . . . , x n ) x'=[x_1,x_2,...,x_n] - \max (x_1,x_2,...,x_n) x′=[x1,x2,...,xn]−max(x1,x2,...,xn)
其最大值对应的位置值为0,其余位置值为负数,继而考虑
e x ′ = [ e x 1 − max ( x 1 , x 2 , . . . , x n ) , e x 2 − max ( x 1 , x 2 , . . . , x n ) , . . . , e x n − max ( x 1 , x 2 , . . . , x n ) ] e^{x'}=[e^{x_1- \max (x_1,x_2,...,x_n)}, e^{x_2- \max (x_1,x_2,...,x_n)},..., e^{x_n- \max (x_1,x_2,...,x_n)}] ex′=[ex1−max(x1,x2,...,xn),ex2−max(x1,x2,...,xn),...,exn−max(x1,x2,...,xn)]
作为 o n e h o t ( arg max ( x 1 , x 2 , . . . , x n ) ) onehot(\argmax(x_1,x_2,...,x_n) ) onehot(argmax(x1,x2,...,xn))的近似。上式最大值处取值为 e 0 = 1 e^0=1 e0=1,其余值处接近0。根据前述结论 m a x ( x 1 , x 2 , . . . , x n ) ≈ ln ( ∑ i = 1 n e x i ) max(x_1,x_2,...,x_n) \approx \ln(\sum_{i=1}^n e^{x_i}) max(x1,x2,...,xn)≈ln(∑i=1nexi),有:
o n e h o t ( arg max ( x 1 , x 2 , . . . , x n ) ) ≈ e x ′ = [ e x 1 − max ( x 1 , x 2 , . . . , x n ) , e x 2 − max ( x 1 , x 2 , . . . , x n ) , . . . , e x n − max ( x 1 , x 2 , . . . , x n ) ] = [ e x 1 − ln ( ∑ i = 1 n e x i ) , e x 2 − ln ( ∑ i = 1 n e x i ) , . . . , e x n − ln ( ∑ i = 1 n e x i ) ] = [ e x 1 ∑ i = 1 n e x i , e x 2 ∑ i = 1 n e x i , . . . , e x n ∑ i = 1 n e x i ] = s o f t m a x ( x 1 , x 2 , . . . , x n ) \begin{alignat} {2} onehot(\argmax(x_1,x_2,...,x_n) ) &\approx e^{x'} \\ &=[e^{x_1- \max (x_1,x_2,...,x_n)}, e^{x_2- \max (x_1,x_2,...,x_n)},..., e^{x_n- \max (x_1,x_2,...,x_n)}] \\ &=[e^{x_1-\ln(\sum_{i=1}^n e^{x_i})}, e^{x_2- \ln(\sum_{i=1}^n e^{x_i})},..., e^{x_n- \ln(\sum_{i=1}^n e^{x_i})}] \\ &=[\frac{e^{x_1}}{\sum_{i=1}^n e^{x_i}}, \frac{e^{x_2}}{\sum_{i=1}^n e^{x_i}},...,\frac{e^{x_n}}{\sum_{i=1}^n e^{x_i}}] \\ &=softmax(x_1,x_2,...,x_n) \end{alignat} onehot(argmax(x1,x2,...,xn))≈ex′=[ex1−max(x1,x2,...,xn),ex2−max(x1,x2,...,xn),...,exn−max(x1,x2,...,xn)]=[ex1−ln(∑i=1nexi),ex2−ln(∑i=1nexi),...,exn−ln(∑i=1nexi)]=[∑i=1nexiex1,∑i=1nexiex2,...,∑i=1nexiexn]=softmax(x1,x2,...,xn)
2.2.3 a r g m a x ( x ) ≈ ∑ i = 1 n i × s o f t m a x ( x ) i argmax(x) \approx \sum_{i=1}^n i \times softmax(x)_i argmax(x)≈∑i=1ni×softmax(x)i
推导过程
a r g m a x ( x ) argmax(x) argmax(x)表示求序列 x = [ x 1 , x 2 , . . . , x n ] x=[x_1,x_2,...,x_n] x=[x1,x2,...,xn]中最大值所在的位置,注意到 a r g m a x ( x ) argmax(x) argmax(x)实际上等于如下內积:
向量 [ 1 , 2 , . . . , n ] ⋅ o n e h o t ( arg max ( x ) ) \text{向量}[1,2,...,n] \cdot onehot(\argmax(x)) 向量[1,2,...,n]⋅onehot(argmax(x))
根据前述结论 o n e h o t ( arg max ( x 1 , x 2 , . . . , x n ) ) ≈ s o f t m a x ( x 1 , x 2 , . . . , x n ) onehot(\argmax(x_1,x_2,...,x_n) )\approx softmax(x_1,x_2,...,x_n) onehot(argmax(x1,x2,...,xn))≈softmax(x1,x2,...,xn),可得:
a r g m a x ( x ) ≈ ∑ i = 1 n i × softmax ( x ) i = ∑ i = 1 n i × e x i ∑ j = 1 n e x j \begin{alignat} {2} argmax(x) &\approx \sum_{i=1}^n i \times \text{softmax}(x)_i \\ & = \sum_{i=1}^n i \times \frac{e^{x_i}}{\sum_{j=1}^n e^{x_j}} \end{alignat} argmax(x)≈i=1∑ni×softmax(x)i=i=1∑ni×∑j=1nexjexi
2.2.4 accuracy ≈ 1 S ∑ x ∈ S < 1 y ( x ) , p ( x ) > \text {accuracy} \approx \frac{1}{S} \sum_{x \in S} <1_y(x), p(x)> accuracy≈S1∑x∈S<1y(x),p(x)>
本节讨论分类任务中正确率 accuracy \text {accuracy} accuracy的光滑近似。
推导过程
给定一个批量样本 S S S,用 1 y ( x ) 1_y(x) 1y(x)表示样本的真实类别 y y y对应的onehot编码, 1 y ′ ( x ) 1_{y^{'}}(x) 1y′(x)表示样本的预测类别 y ′ y^{'} y′对应的onehot编码。统计两个编码对应的内积之和(预测相同内积为1否则为0),表示为 < 1 y ( x ) , 1 y ′ ( x ) > <1_y(x), 1_{y^{'}}(x)> <1y(x),1y′(x)>,即可得到正确率的表达式(预测正确的数量占总数量的比值):
a c c u r a c y = 1 S ∑ x ∈ S < 1 y ( x ) , 1 y ′ ( x ) > accuracy = \frac{1}{S} \sum_{x \in S} <1_y(x), 1_{y^{'}}(x)> accuracy=S1x∈S∑<1y(x),1y′(x)>
网络的预测结果 1 y ′ ( x ) 1_{y^{'}}(x) 1y′(x)是经过softmax的概率分布 p ( x ) p(x) p(x),则正确率的光滑近似为:
a c c u r a c y ≈ 1 S ∑ x ∈ S < 1 y ( x ) , p ( x ) > accuracy \approx \frac{1}{S} \sum_{x \in S} <1_y(x), p(x)> accuracy≈S1x∈S∑<1y(x),p(x)>
2.2.5 F1-score ≈ 2 ∑ x ∈ S p ( x ) y ( x ) ∑ x ∈ S p ( x ) + y ( x ) \text {F1-score} \approx \frac{2\sum_{x\in S} p(x) y(x)}{\sum_{x\in S} p(x) + y(x)} F1-score≈∑x∈Sp(x)+y(x)2∑x∈Sp(x)y(x)
F1-score是分类问题常用的评估指标,计算为查准率和查全率的调和平均。对于二分类问题,若记 p ( x ) p(x) p(x)是预测正类的概率, y ( x ) y(x) y(x)是样本的标签,则对应的混淆矩阵如下:
| 标签\ 预测 | 正例 | 反例 |
|---|---|---|
| 正例 | T P ≈ p ( x ) g ( x ) TP \approx p(x)g(x) TP≈p(x)g(x) | F N ≈ ( 1 − p ( x ) ) g ( x ) FN \approx (1-p(x))g(x) FN≈(1−p(x))g(x) |
| 反例 | F P ≈ p ( x ) ( 1 − g ( x ) ) FP \approx p(x)(1-g(x)) FP≈p(x)(1−g(x)) | T N ≈ ( 1 − p ( x ) ) ( 1 − g ( x ) ) TN \approx (1-p(x))(1-g(x)) TN≈(1−p(x))(1−g(x)) |
则F1-score计算公式为
F1-score = 2 T P 2 T P + F P + F N ≈ 2 ∑ x ∈ S p ( x ) y ( x ) ∑ x ∈ S p ( x ) + y ( x ) \text {F1-score} = \frac{2TP}{2TP+FP+FN} \approx \frac{2\sum_{x\in S} p(x) y(x)}{\sum_{x\in S} p(x) + y(x)} F1-score=2TP+FP+FN2TP≈∑x∈Sp(x)+y(x)2∑x∈Sp(x)y(x)
上述推导的F1-score的光滑近似是可导的,可以将其相反数作为损失函数。但是在采样过程中,上式是F1-score的有偏估计。通常应先用交叉熵训练一段时间,再用上式进行微调。
2.3 使用冲激函数近似
参考paper:
SAU: Smooth activation function using convolution with approximate identities
paper解读:https://0809zheng.github.io/2021/11/05/sau.html
3 不可导点的次梯度方法
比如ReLU激活函数f(x)=max(0, x)在x=0处不可导。
次梯度c定义为:
c ≤ f ( x ) − f ( x 0 ) x − x 0 c \leq \frac{f(x)-f(x_0)}{x - x_0} c≤x−x0f(x)−f(x0)
对于ReLU函数, 当x>0的时候,其导数为1; 当x<0时,其导数为0。 则ReLU函数在x=0的次梯度 c ∈ [ 0 , 1 ] c\in [0,1] c∈[0,1],这里是次梯度有多个,可以取0,1之间的任意值. 工程上为了方便取c=0即可。
4 采样的重参数化方法
重参数化的目的是分离随机变量的不确定性,使得原先无法求导或者梯度传播的中间节点可以求导。
4.1 对连续分布采样的重参数化
一般假设连续分布的变量x服从高斯分布,即 x ∼ N ( μ , σ 2 ) x \sim N(\mu, \sigma^2) x∼N(μ,σ2),从这个分布中采样是不可导的。欲使其可导,我们可以这样做:首先从均值为0,标准差为1的高斯分布中采样一个值 ϵ \epsilon ϵ,再放缩平移得到x。
x = μ + σ ∗ ϵ , ϵ ∼ N ( 0 , 1 ) x=\mu + \sigma * \epsilon, \epsilon \sim \N(0, 1) x=μ+σ∗ϵ,ϵ∼N(0,1)
x的生成只涉及了线性操作(平移缩放),真正的采样操作在神经网络的计算图之外,而 ϵ \epsilon ϵ对于神经网络来说只是一个常数。
4.2 对离散分布采样的重参数化(Gumbel-softmax)
比如文章开头提到的强化学习中离散动作的采样,就是适合应用这个方法的案例。经典的离散分布采样方法就是用softmax函数加上轮盘赌方法(np.random.choice):
def sample_with_softmax(logits, size):
# logits为输入数据
# size为采样数
pro = softmax(logits)
return np.random.choice(len(logits), size, p=pro)
轮盘赌方法就是多项式采样,这个不解释,请自行搜索了解。
要解决轮盘赌方法不可导问题,可以借助Gumbel分布。让我们一步步推到出Gumbel-softmax方法。
推到过程
对于softmax函数输出n维向量的第i维的分量 α i = e x i ∑ j = 1 n e x j \alpha_i = \frac{e^{x_i}}{\sum_{j=1}^n e^{x_j}} αi=∑j=1nexjexi,取对应的变换 l o g ( α i ) log(\alpha_i) log(αi)并加上Gumbel噪声,得到新变量 π i \pi_i πi:
π i = arg max i ( [ l o g ( α 1 ) + G 1 , l o g ( α 2 ) + G 2 , l o g ( α i ) + G i , . . . , l o g ( α n ) + G n ] ) \begin{alignat} {2} \pi_i = \argmax_i([log(\alpha_1)+G_1, log(\alpha_2)+G_2, log(\alpha_i)+G_i,..., log(\alpha_n)+G_n]) \end{alignat} πi=iargmax([log(α1)+G1,log(α2)+G2,log(αi)+Gi,...,log(αn)+Gn])
其中, G i G_i Gi是满足标准Gumbel分布的随机变量,即 G i = − l o g ( − l o g ( U i ) ) G_i = -log(-log(U_i)) Gi=−log(−log(Ui)), U i U_i Ui服从均匀分布 U ( 0 , 1 ) U(0,1) U(0,1);
上述公式(16)也称Gumbel-max方法。
可以证明,Gumbel-max 方法的采样效果等效于前述基于“softmax+轮盘赌“的方式(该结论证明可参考:盘点深度学习中的不可导操作(次梯度和重参数化))。由于 Gumbel 随机数可以预先计算好,采样过程也不需要计算 softmax,因此,某些情况下,gumbel-max 方法相比于 softmax,在采样速度上会有优势。当然,可以看到由于这中间有一个argmax操作,这是不可导的,依旧没法用于计算网络梯度。argmax操作的近似为可导的操作只需要参考前文第2.2.3节的近似公式即可,于是变量 π i \pi_i πi近似处理为:
π i ≈ softmax i ( l o g ( α i ) + G i ) \begin{alignat} {2} \pi_i \approx \text{softmax} _i (log(\alpha_i)+G_i) \end{alignat} πi≈softmaxi(log(αi)+Gi)
实际应用中通常还会加一个温度变量 τ \tau τ,使 π i \pi_i πi变为:
π i ≈ softmax i ( l o g ( α i ) + G i τ ) \begin{alignat} {2} \pi_i \approx \text{softmax} _i (\frac{log(\alpha_i)+G_i}{\tau}) \end{alignat} πi≈softmaxi(τlog(αi)+Gi)
τ \tau τ是大于零的参数,它控制着 softmax 的 soft 程度。温度越高,生成的分布越平滑;温度越低,生成的分布越接近离散的 one-hot 分布。神经网络训练中,可以通过逐渐降低温度,以逐步逼近真实的离散分布。
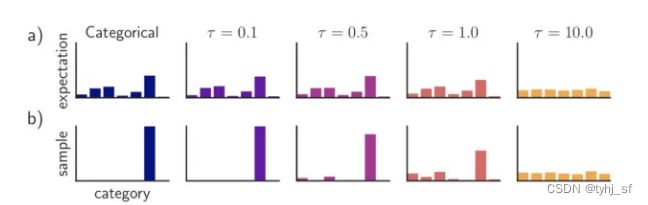
公式(18)即为Gumbel-softmax重参数方法。
5 参考资料
[1]. https://0809zheng.github.io/2021/11/16/mollifier.html
[2]. https://zhuanlan.zhihu.com/p/97465608
[3].The Reparameterization Trick, 2018.4