计算机视觉发展和应用浅谈
计算机视觉(Computer Vision)又称为机器视觉,顾名思义就是一门”教“计算机如何”看懂“世界的学科。计算机视觉从传统的计算机视觉技术发展到如今以深度学习技术为主线的视觉技术,本文将首先介绍传统计算机视觉中的特征提取方法、分类器的设计以及基于深度学习技术的自动特征提取及分类或回归技术,其次介绍一些典型的视觉应用及其使用的技术方案,然后介绍了视觉领域一些典型的工具(开发)库和的数据集,最后分析了计算机视觉领域面临的挑战以及对其未来进行展望。
对于传统(如传统机器学习)的方法都需要手动设计特征和选择分类器(如SVM、BP ANN等),人工设计依赖经验和领域知识,其难度大并具有主观性,人工设计的特征并非最优的以及往往不能很好地描述问题的本质。传统的分类器其能力有限,往往不能够满足大规模数据集或复杂的数据集的需求,因此传统的方法具有很大的局限性,难以胜任日趋复杂以及更高的应用需求。幸运的是,随着近年来大数据的诞生、快速发展的高性能高并行的GP-GPU(以及其它的AI加速器)设备以及深度神经网络技术的迅猛发展,深度学习在视觉领域取得了突破性的进展,比如行人检测、人脸识别、车辆车牌识别、交通流量预测、姿态估计、行为识别、视频内容理解等。相较于传统的技术方法,深度学习往往一种简洁的端到端的方式解决问题,其自动提取特征并且进行分类,能够学习到与问题相关的更抽象、泛化能力更强的层次化特征,已经在诸多视觉领域取得了令人瞩目的成就。
计算视觉领域解决问题的一般流程:问题分析->特征提取->分类(回归)。
一、传统特征提取方法
颜色(灰度)直方图、SIFT(尺度不变特征)、HOG(方向梯度直方图)、SURF、ORB、LBP、HAAR
二、传统分类器
线性回归、逻辑回归、朴素贝叶斯、贝叶斯网络、(隐)马尔科夫、决策树、神经网络(ANN-BP)、K近邻、K-Means、SVM(支持向量机)、ANN(人工神经网络)、决策树、随机森林、集成模型(RF/GDBT等)。
集成学习,其训练多个模型,然后将这多个模型进行融合,综合做出最终的决策。RF典型的代表是bgging,GDBT其典型代表是boosting。
三、深度学习特征提取及分类
传统的机器学习需要人工设计特征和选择合适的分类器,其效率低,特征比较单一,鲁棒性不强,效果不是很好,但是其优点是可解释性强,符合人的直观逻辑思维。而深度学习利用深度神经网络自动进行特征提取并且进行分类,其提取的特征更抽象,特征描述能力更强,但是往往缺乏可解释性。
1DCNN(一维卷积)可以捕捉时序数据的时序特征,其通过堆叠多个卷积操作和池化操作实现对时序数据的整体特征进行提取。
2DCNN(二维卷积)可以很好的捕捉二维空间的数据特征,比如使用2DCNN来提取图像的空域特征,近些年2D卷积操作已经在图像识别、目标检测、图像分割、实列分割等领域取得了辉煌的成就。
3DCNN(三维卷积)可以很好地捕捉三维空间的数据特征,视觉领域中的视频片段就是典型的3维数据,视频片段具有时序特征和空间特征,具体的说就是视频在时间维度具有时序特征性,而在每一个时刻(即每一视频帧)又具有二维空间特征。视觉动作识别、行为识别、事件识别等往往可以采用3DCNN网络来解决,可以取得不错的效果。
1DCNN和2DCNN容易实现并行,使用NVIDIA的cudnn加速库可以取得很不错的加速比,但是3DCNN的并行度却不如前两者,同时3DCNN的参数量和计算量较前两者也大的多,因此更难训练并且需要更长的时间才能训练好。
RNN(递归神经网络、循环神经网络),其可以捕捉时序特征。但是对于长时间序列,RNN面临梯度消失和梯度爆炸的问题,并且对长时间序列建模效果不理想。
LSTM相比RNN可以较好地提取长时间序列数据的特征,同时大大缓解了梯度消失和爆炸问题。GRU是LSTM的改进版本,具有更好的性能和效果。
TCN(时间卷积),其相当于1DCNN的变体,也可以较好的捕捉时序特征。1DCNN捕捉的时序长度比较有限,为了捕捉较长的时序特征,需要堆叠较多的卷积层,这导致参数两和计算量剧增,容易出现过拟合等问题,模型难以训练。但是1DCNN只需要堆叠较少的卷积层就可以捕捉长时间序列数据的时序特征,而且更容易训练,效果也较好,目前在诸多时间序列应用上取得了与LSTM等相当的成绩,并且1DCNN易于并行,训练的速度比LSTM快得多。
ConLSTM(卷积LSTM)可以同时捕获时序特征和空间特征,可以用于视觉动作识别、行为识别、事件识别(检测)、视频未来帧(事件)预测等方面,其与3DCNN比较相似。ConLSTM在三维数据的特征提取方面相对于3DCNN也是有区别的,虽然有时候它们的作用很相似,二者都可以较好地捕捉到二维的空间特征,但是在时序特征提取方面,前者可以捕捉长时间依赖关系,而后者往往不能。处理同样的问题,后者的计算量和参数量更大,更难于训练。
Attention机制:
- 紧接在1DCNN、RNN、LSTM、GRU等返回序列数据的层的后面。
- 在视觉领域,注意力又分为通道注意力机制和空域注意力机制,经典的通道注意力机制如SeNet。
- Self-Attention,每一个位置的数据(特征)都与其它位置的数据计算相似性,然后对相似性进行归一化,之和再对所有位置的数据进行加权求和,用其代替该位置的数据(特征)。Self-Attention其实对时序(位置)不敏感,为此有改进版的,将位置特征考虑进去,这样就可以较好的捕捉时序特征了,其比不带注意力机制的RNN等时序模型可能有更好的效果。
- Multi-Head Attention,本质上还是Selt-Attention,只不过采用了多个self-attention,提取的特征更丰富,对原始序列中各元素的先后位置关系不敏感。
- Transformer、Bert等,Bert的基础就是Transformer,由多个Transformer按照一定结构堆叠而成,Transformer中对原始数据的序列位置进行了编码,使得模型能够更好地表征序列数据的时序关系。网络相关资源很多,讲的很详细。
Bert---->Transformer--->Multi-Head Attention--->Self-Attention
四、视觉应用及技术方案
- 图像识别:CNN
- 目标检测:CNN
- 图像分割:CNN
- 实例分割:CNN
- 动作识别、行为识别、事件检测:3DCNN、ConLSTM、LSTM、Two-Stream,一般需要同时捕捉空域特征(1D或2D空间)和时域特征(必须)、GCN+时序模型。
- 人脸识别:CNN
五、计算机视觉开发库(工具)
OpenCV就可以了,是目前学术界和工业界最流行的开源计算机视觉库,主要由Intel计算机视觉小组进行开发和维护,个人也可以贡献技术和代码。
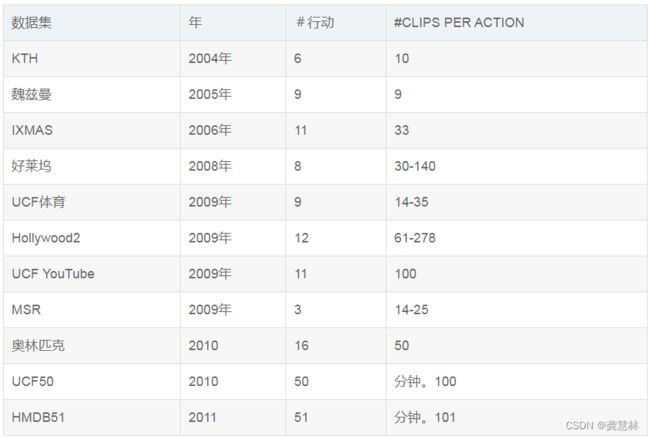
六、视觉领域数据集