基于C#.NET的高端智能化网络爬虫
前两天朋友发给我了一篇文章,是携程网反爬虫组的技术经理写的,大概讲的是如何用他的超高智商通过(挑衅、怜悯、嘲讽、猥琐)的方式来完美碾压爬虫开发者。今天我就先带大家开发一个最简单低端的爬虫,突破携程网超高智商的反爬虫技术。
 一、什么是爬虫?
一、什么是爬虫?
很多人说我们这些搞软件的人,总喜欢把虚拟世界里的事物跟现实中的东西扯上关系。这点我真不否认,脱离了现实,我们伟大的创举还有何意义?
“爬虫”就是个例子,它对于我们开发人员而言,就是一段用来自动化采集网站数据的程序,结果跟现实中的虫子扯上了关系。听说是Google工程师提出来的,有质疑请联系Larry Page。

二、为什么需要开发爬虫?
在这个数据横流的互联网时代,创业型公司如雨后春笋般的崛起,而大数据则可以帮他们迅速生产垂直化数据资料库,提供给用户使用。同时也让老板们更容易看清未来的方向,制定发展策略。
这些大数据从哪儿能弄来呢?当然是从每个行业里的龙头老大那里,做老大就是这么不容易。这图里一部分是行业老大,有些我也没听说过,仅供参考:

京东的价格、携程的评论、亚马逊的书、淘宝的信用、支付宝的订单等。这些数据采集下来都很庞大,那究竟要这些数据有什么用呢?
直接用于机器学习,分析用户的兴趣爱好和行为。
获取淘宝店铺信用,直接用于新平台的用户信用及身份验证。
获取各个商城物品价格,为用户提供市场场最低价。
获取酒店、图书的(价格、简介、评论),做垂直化平台的基础数据库。

请原谅我用携程举例:设想我们要做一个高端的垂直化酒店平台,就拿北京来说,酒店接近10000家。要是全部都手动筛选、录入这些信息,需要花费的人力、时间是极其恐怖的事。当然最难的应该是将人工搜集的数据标准化。怎样才能把携程网的酒店数据弄下来作为我们的基础资料库呢?
 如果利用爬虫技术,事情就有了很好解决方案。我们只需要编写一个7*24小时运行的分布式爬虫,自动化采集携程网酒店数据,将国内外所有高端酒店(图片、简介、评分、用户评论)全部抓取下来。再通过数据清洗,使内容标准化,让这些数据成为我们的基础资料库就行了。看到这里内心是不是已经有点小激动?
如果利用爬虫技术,事情就有了很好解决方案。我们只需要编写一个7*24小时运行的分布式爬虫,自动化采集携程网酒店数据,将国内外所有高端酒店(图片、简介、评分、用户评论)全部抓取下来。再通过数据清洗,使内容标准化,让这些数据成为我们的基础资料库就行了。看到这里内心是不是已经有点小激动?
三、开发爬虫需要哪些技术?
由此可见,爬虫技术已经成为我们每个开发人员最基本的技能,同时也是步入中高级开发不得不涉足的内容。为什么这么说呢?因为开发一个像样的爬虫,需要你了解的东西还真不少:
学习任意一门开发语言:C#、NodeJs、Python、Java、C++。
学习网页前端脚本语言:Javascript、HTML、CSS。
学习HTTP协议、正则表达式、数据库、代理切换等相关知识。
学习多线程并发抓取、任务调度、消息队列、分布式爬虫、图像识别、模拟键鼠、NoSql。

我仿佛看到了你一脸懵懂的表情!你真的没有看错,这些技术只是冰山一角。不过也不用担心,初中级的爬虫只需要学会前三点就可以了。要想开发出更高级的爬虫,第四点是必须会的,同时为了追求极致的性能,还需要研究开源浏览器内核的相关项目,此处暂省略十万字。
四、开发一个最简单的爬虫
下面我用C#.NET来写一个非常简单的爬虫,我们的爬虫之所以被封杀,肯定是因为对方找到了运行特征。因此只需要修改爬虫的运行方式及特征,让其操作与普通用户的相似就可以了。一般爬虫会有哪些特征和运行方式呢?
User-Agent:主要用来将我们的爬虫伪装成浏览器。
Cookie:主要用来保存爬虫的登录状态。
连接数:主要用来限制单台机器与服务端的连接数量。
代理IP:主要用来伪装请求地址,提高单机并发数量。

通常来说,只要我们控制好了上面这4个东西,反爬虫组那边就较难找到我们的运行特征。还是拿携程网来举个例子,抓取他们的酒店数据,因为这些酒店信息本身属于公开的内容,我们也不用于商业运作的目的,只是为了想见识一下他们反爬虫经理所描述的猥琐程度。
爬虫工作的方式可以归纳为两种:深度优先、广度优先。
深度优先就是一个连接一个连接的向内爬,处理完成后再换一下一个连接,这种方式对于我们来说缺点很明显。广度优先就是一层一层的处理,非常适合利用多线程并发技术来高效处理,因此我们也用广度优先的抓取方式。
首先我们用Visual Studio 2015创建一个控制台程序,定义一个简单的SimpleCrawler类,里面只包含几个简单的事件:

接着我们创建一个OnStart的事件对象:

然后我们创建一个OnCompleted事件对象:

最后我们再给它增加一个异步方法,通过User-Agent将爬虫伪装成了Chrome浏览器,代码中每行我基本都加了注释,学过.NET的朋友一看就明白,这里就不再重复解释了:

就如你所见,一个支持并发执行、可伪装成Chrome浏览器、支持Cookie状态保存、支持代理切换的简单爬虫就完成了。
为了加快爬虫的速度,我又增加了Gzip解压缩的功能,由于不太便于截图,大家可以在源代码里查看。现在我们用这个爬虫抓取一下携程网的酒店数据,看看效果如何。
携程的酒店是按城市归类的,从每个城市又链接到了下属所有酒店,国内的城市大约有300多个,仅北京一个市的酒店数据就有9000多个,所以我要先抓下边这页面里的城市名称及城市URL地址。

在控制台里写下爬虫的抓取代码:
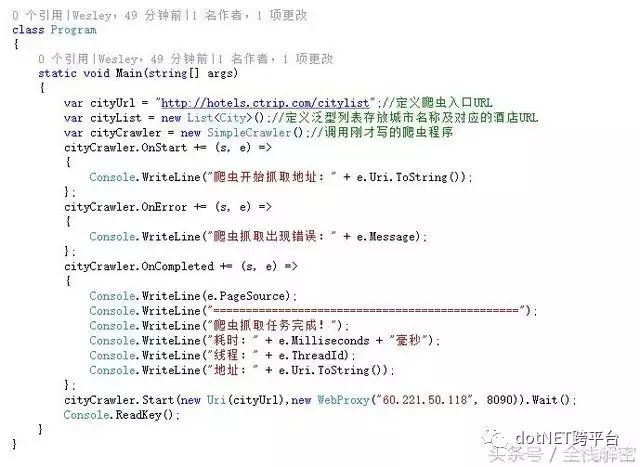
代码都很简单,眼睛犀利的朋友肯定看到了我在cityCrawler.Start()方法中使用了代理服务器,那个参数是可选的。经测试代理IP的速度还不错,唯一不足的地方可能就是偶尔会出现连接超时,并发量少时并不需要开代理,这里只是为了测试的需要。来看看执行情况:
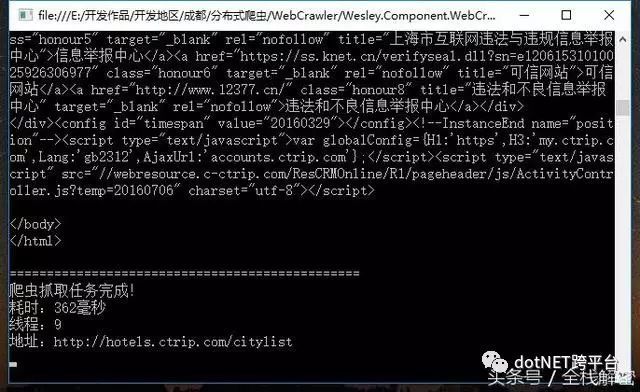
由上图可见,我们抓到了城市列表页面的源代码,但这并不是我们需要的数据,我们只想要规规矩矩的城市名称和URL地址。
怎么办呢?现在请出《正则表达式》—又简洁又高效的神器,就是学起来比较费劲。我写了个提取城市名称及URL的正则表达式,直接提取源代码中所有符合规则的数据:
在控制台程序中增加正则表达式过滤数据:
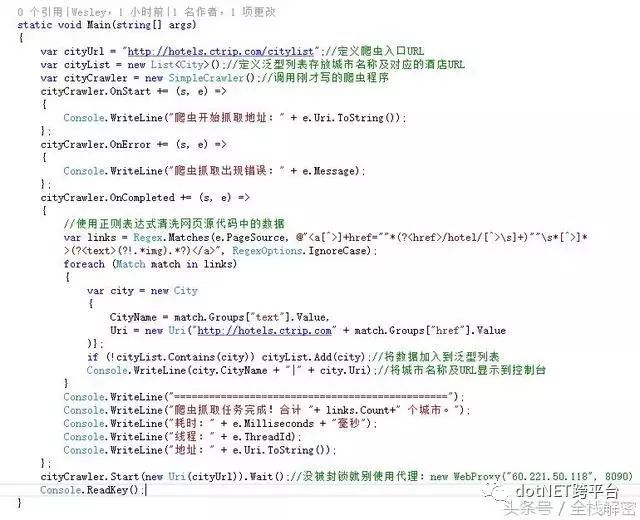
再次运行爬虫看看是否是我们需要的内容:

运行状态良好,成功拿到了城市名称及城市URL地址,每个城市的URL中都包含了该城市的所有酒店,现在我们就根据城市URL抓取下属的酒店列表,就拿最后一个城市来试试吧,我就不贴代码了,同样是先抓取源代码,再使用正则表达式清洗数据:
">
请原谅我写出这无比糟糕的正则表达式,看看它的运行结果:
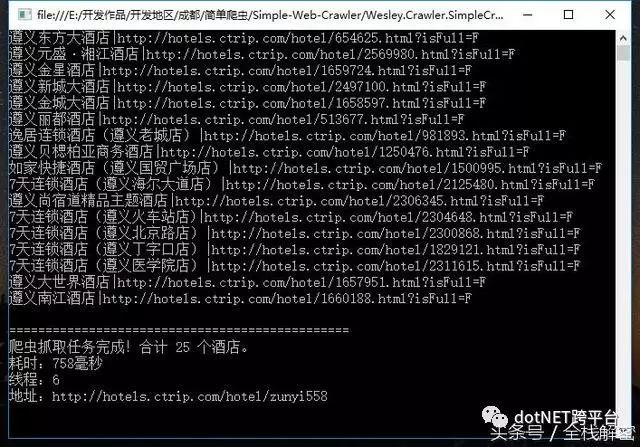
这里我发现一个有趣的地方,携程网酒店列表页中的连接,在点击后会发生变化,会自动拼接上一个当天的日期,应该是用javascript写的事件。我测试了下这些URL都能正确的连接到酒店介绍页,如果这算是他们的反爬虫手段,大家也可以在下一篇高级爬虫知识里找到解决方案。
下面写个多爬虫并发抓取的例子,代码也非常简单,随便写两个酒店URL地址,通过Parallel实现2个爬虫的并发抓取。
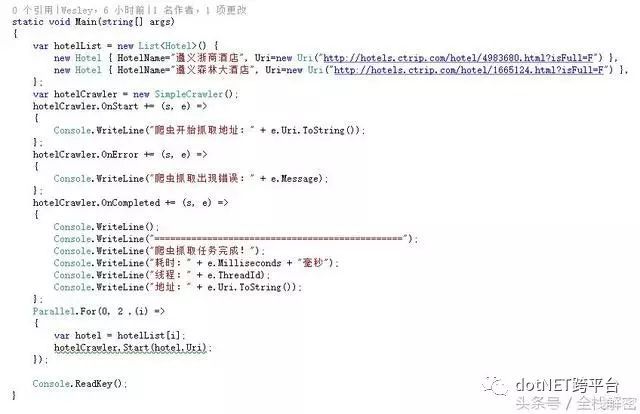
注意:单个IP并发数量不要设置太多,短时间内发送大量的爬虫请求,很容易被反爬虫组轻易的识别出来,因为普通用户不可能在一秒内有那么多的请求和连接。
我们想要提高并发数量怎么办呢?当然是使用代理IP和VPN,假设反爬虫组限制单台IP连接数不能超过50,那我们增加一个代理IP就相当于可以多并发50个爬虫出去,在带宽足够的情况下,10个有效的代理IP就可以让爬虫的性能提到一个新的高度,有没有感觉到大数据已经在向你招手?

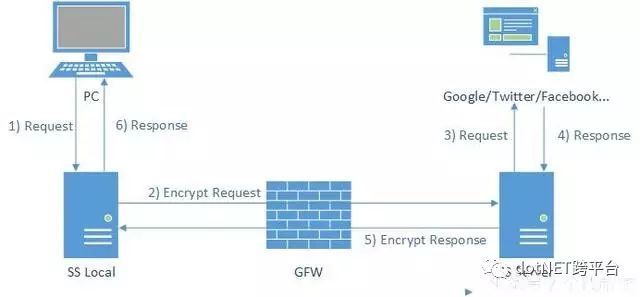
有人说代理也可以被检测出来,那是因为你还不太了解代理,代理服务器有很多种,而且真有不能被检测出来的代理,比如自己搭建的 s ,这块内容较多,将在下一篇高级爬虫的文章详细讲解,它的运行方式如下:
现在大家就可以利用这个简单的爬虫自由发挥了,试试从酒店列表里抓取每个酒店的(评分、名称、图片),不要太难为自己,毕竟这只是一个最简单的爬虫,抓取都是同样的原理,我就不再多说。
明天发下一篇(绝对干货):基于C#.NET的高端智能化网络爬虫(二),主要讲:如何开发浏览器内核的高级爬虫、如何执行Javascript、如何操作Dom结构、如何搞定加密代理、如何实现分布式等功能。
然后我们通过这个高级爬虫,实现对携程网Ajax评论数据的抓取,这次我们就抓取他们的酒店评论。希望大家订阅“全栈解密”,千万不要错过哦!
全部源代码下载:https://github.com/coldicelion/Simple-Web-Crawler
原文地址:http://www.toutiao.com/a6304503113106555138/
.NET社区新闻,深度好文,微信中搜索dotNET跨平台或扫描二维码关注
