API的过去,现在与未来主体内容参考翻译自Future of APIs。

API的过去,现在与未来
随着微服务架构的流行,貌似我们已经聊了很多关于现在的API的设计与规范,不过能够畅想的未来的API又是怎样的模式呢?首先,我们需要回顾下API的过去与现在。
过去
土耳其机器人:The Turk
我们可以追溯到1770年匈牙利帝国时代的哈普斯堡王朝,匈牙利作家兼发明家沃尔夫冈·冯·肯佩伦(Wolfgang von Kempelen)建造了土耳其机器人(The Turk),它由一个枫木箱子跟箱子后面伸出来的人形傀儡组成,傀儡穿着宽大的外衣,并戴着穆斯林的头巾。这个机器人可以下国际象棋,发明家打算让他的机器人与当时最优秀的国际象棋选手一较高下。在机器人完成之后,Kempelen带着他的机器人来到了玛丽亚·特蕾西亚的宫殿,一时之间这个能自动下国际象棋的机器人风靡欧洲上流社会,包括波拿马拿破仑与本杰明富兰克林等在内的人士都见证了机器人战胜知名对手的对弈。不过当时可没有什么人工智能与机器学习技术,而是有一个实实在在的象棋大师被隐藏在盒子中,这个机器人不过是Kempelen的一个小把戏而已。就像魔术师一样欺骗那些观众,让他们误以为是一台真正的机器在下棋,最终在1850年这个把戏被揭穿。
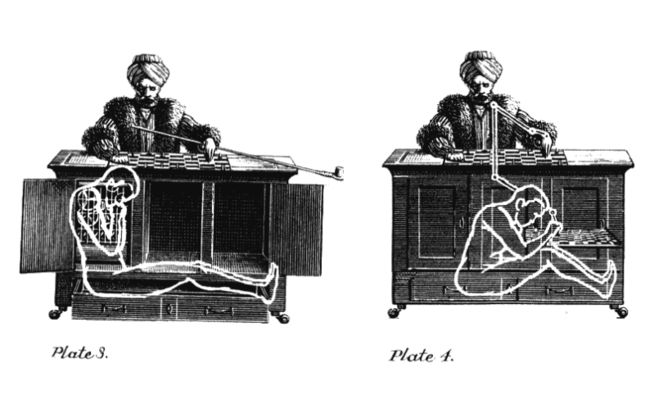
不过这个小把戏也为我们留下了一句俗语,从此之后人们会使用Mechanical Turk来指代那些貌似完全自动化运行,不过还是逃不开人类介入的系统。
Aliens
时间又来到了1963年,美国心理学家与计算机科学家J.C.R Licklider着手编写星系网络间的成员信息沟通备忘录一文。Licklider为计算机科学的发展做出了突出的贡献,他推进了现代界面交互程序的发展与ARPANET以及因特网的出现。Licklider在他的书中提到了一个问题:应该如何与其他智慧生物建立通信?假设现在有数个横跨星际的超大型网络,那么当这些网络连接时,他们应该如何进行交流呢?答案很简单:每个网络本身都必须指明自己的协议标准,来让其他网络接入。就像2016年的电影Arrival中所描述的,不同的智慧生物之间需要首先观察,记录下相互的反应以建立常用词典,然后基于这些词典去开始有意义的会话。
Deep Blue
时间的齿轮又慢慢转过了33年,来到了1996,这一年IBM的超级计算机Deep Blue在首次对战中成功战胜了国际象棋大师Garry Kasparov,虽然后面的几局里Garry Kasparov扳回劣势,一城未失。不过之后的一年中IBM继续完善Deep Blue,并且最终赢得了比赛的胜利,成为首个战胜世界级大师的机器。此时距离Von Kempelen 提出 Turk 已经过去了227年,当初的小把戏没想到最终成为了现实。
现在
Deep Blue出现的三年之后,也就是2000年时,Roy Fielding发布了影响深远的著名论文:Architectural Styles and the Design of Network-based Software Architectures。也就是后来广为人知的REST API架构风格,为广大的开发者规划出了基于HTTP协议的Web APIs蓝图。同年,Salesforce 发布了他们Web API的首个版本,允许第三方通过这些Web API自动化管理交易流程。随后,包括eBay、Google等在内的科技巨头纷纷发布了他们的Web API。

看起来已经进入了信息互联互通的盛世,机器与机器之间通过Web APIs进行信息交互,不过总感觉怪怪的。我们理想的情况是某个机器暴露部分接口,其他机器发现并且使用这些接口,然后现实还是很残酷的。

在现实环境中,某个服务发布一系列接口,然后相关的开发人员编写接口规范文档然后四处播散。而另外部分的开发人员首先需要阅读文档,然后根据文档规范编写相应的程序指示机器去访问这些接口。
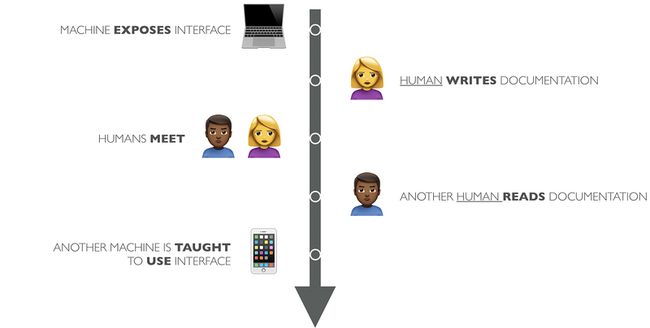
在这种情况下,开发者不可避免的以中间媒介的方式介入了这种机器与机器的沟通中,就好像我们上文提到的Mechanical Turl类似,都有人藏在盒中操纵这些机器。因此,现阶段的API,更应该叫做API Turks。
我们的视线再转回Web APIs本身,现在可谓进入了Web APIs的黄金时代,随着World Wide Web的迅猛发展与巨大成功,Web APIs的数量也极速爆发。
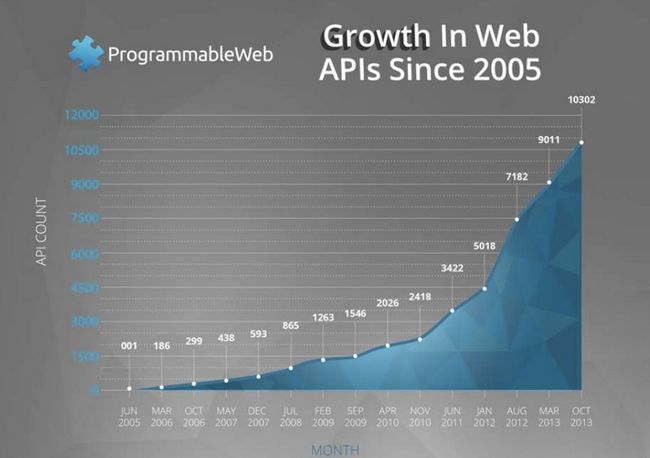
随着API数量与访问量的指数级的增长,因为人为大规模的介入API的开发与访问也带来了越来越多的问题。基本上每个API都会存在以下问题:
Synchronicity:同步性
现有模式下,在两台机器互联互通之前我们需要编写与分享API说明文档,即使我们忽略了因为人为沟通而导致的误解,如果APIs的规范发生了变化很多开发者还是会照着旧的文档编写API消费程序,最终导致驴头不对马嘴。在工程实践中,想要保持文档与API的实时一致性非常困难,需要大量的人力物力,另一方面,想要保持所有的客户端与API保持一致更是痴人说梦。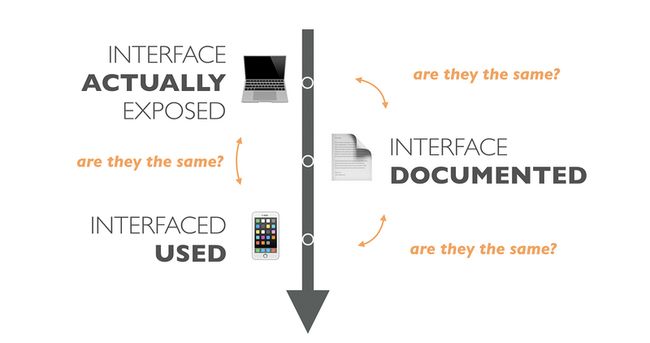
Versioning:版本控制
上面提及的接口同步问题也随之带来了版本控制的问题,鉴于实际上大部分的接口并没有严格遵循Fielding的REST准则,很多的API客户端都与这些接口强耦合。这种强耦合最终会导致一个非常脆弱、鲁棒性非常低的系统,任何API的变化都有可能导致客户端的崩溃。同时,API客户端的升级也是完全依赖于开发者,这一点的代价也非常昂贵且缓慢,并且还要考虑到大量的已经部署的无法轻易升级的老版本API客户端。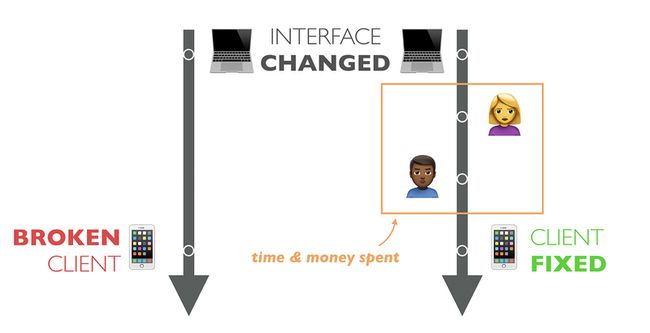
这林林总总的问题让我们畏惧改变,每次对代码的修改都好似埋下未知的炸弹。我们不敢去修改已存在的接口,而是不断地编写新的接口,最终导致代码库日益庞杂。我们需要投入更多的人力物力,背负更多的技术负债,以及无休止的讨论来解决版本难题。
Scaling:可扩展性
既然在API的发布过程中不可避免的有人类的参与,那么我们需要雇佣更多的开发者来扩展API。人非圣贤,孰能无过,更多的开发者也就意味着更高的错误出现概率。并且大量的开发者参与进来的确可以提升编写或者阅读文档的速度,而更快地构建更多的APIs,但是这并不意味着你就可以解决上文提及的API变化响应速度。总而言之,如果我们以添加人员的方式来扩展API,那么会无限制地扩充我们的专属名词库,也增加了错误的可能性。譬如某个消费者希望得到的是Title,另一个消费者希望得到的是博客的Heading,其实是同一属性的不同语义表述,这样就会使得消费者陷入迷惑,或者导致数据的冗余。
Discovery:API发现
最后,我们要来聊聊API共享与发现这个问题(API Discovery)。我们应该如何去寻找合适的API,特别是当我们构建一个大型系统的时候,我们不希望重复地造大量的轮子,我们就迫切的希望能找到合适的API来辅助开发。另一个方面,API的提供者也不知道如何进行市场营销,很有可能存在着比Google Places API优秀的多的地理位置服务商,不过我们也无从找起。
未来
在过去的数十年中,我们尝试了使用不同的程序与工具来解决上文中提及的数个问题。API Workflow、API Style Guide、API Documentation Best Practices,以及其他企业级的保持同步性、避免大规模变化与避免人为错误的标准都是我们披荆斩棘一路走来的成果。我们使用了Swagger这样优秀的文档生成器来尽可能保证文档与代码的一致性,我们规定了复杂的测试流程、雇佣更多的开发者来维护庞杂的API系统。某个大公司雇佣专门的团队来辅助API文档的编写与更新也是见怪不怪的事情。我把这个过程重新组织下就是:我们雇佣开发者来负责为其他开发者编写可读的API文档,从而辅助他们理解某个机器接口,并且编写合适的消费程序来使用这些接口。我的一个朋友是这么说的:
Programmers tend to solve programming problems by more programming.
而现在的API分享与发现,对于幸运的几个不差钱的公司他们可以花钱进行市场推广与营销,而其他可怜兮兮的小公司只能默默地在Hacker News上进行推广。
Human role in M2M Communication
让我们再来回顾下前面抛出的问题,为什么我们一定需要人类参与到API Turks中呢?人类在机器与机器的通信中又占据了怎么不可或缺的角色?实际上人类最关键的作用在于API的发现与理解,我们在找到合适的服务之后需要来理解是否能用它达成预定目标以及到底应该怎么做。
Autonomous APIs
既然人类的介入导致了昂贵、缓慢且错误频发的后果,那是否有方法来避免这种情况?我们是否能够创建完全自动化的接口呢?首先,我们需要一个渠道来开发并且共享专用名词(Vocabularies),然后在API上线之后通过某个统一的API Discovery进行注册发布。整个自动化的没有人类介入的流程描述如下:
某个机器在发布接口的同时提供接口的描述文档与专属的词汇库,然后自动地在某个API发现服务中完成注册。
然后某个需要服务支持的API消费者在发现服务中利用关键字进行搜索,如果找到某个匹配的服务之后则将其描述文档推送给抓取程序。
指定的API客户端能够根据请求到的词汇库自动训练与调试,这样开发者就能够利用这些API进行上层开发。
这些客户端更多地能够以声明式的方式完成特定的工作,而不会强耦合于某个特定的服务接口。以某个具体的程序为例,如果我们希望查询巴黎的天气:
# Using a terms from schema.org dictionary,
# find services that offers WeatherForecast.
services = apiRegistry.find(WeatherForecast, { vocabulary: "http://schema.org"})
# Query a service for WeatherForecast at GeoCoordinates.
forecast = service.retrieve(WeatherForecast, { GeoCoordinates: … })
# Display Temperature
print forecast(Temperature)这样的使用方式不仅能够保证API消费者弹性地应对API变化,还能保证多个API之间的代码复用性。譬如,你不再需要为某个单独的地区需求开发特定的天气应用,你可以开发某个通用的客户端,它知道如何呈现天气预报,也能自动地使用譬如AccuWeather、Weather Underground或者任何其他特定地区的天气服务提供商来获取特定地区的天气信息。

总结来看,自动化API的构建会包含以下几块:
Vocabulary Registry
运行时解析
API Discovery Service
面向Vocabulary而不是数据结构的编程
即将到来的2017
上面描述的理想状态可能离我们还非常远,不过在2017里我们已经发现很多的进展。譬如HATEOAS允许我们以超媒体语义的方式进行运行时解析。JSON-LD格式也被越来越多的API提供商接受,而类似于Google、Microsoft、Yahoo以及Yandex等API提供商也逐渐接受Schema.org中的专属词汇。而类似于ALPS这样的格式也允许我们为接口的数据与使用情景提供语义化支持,与此同时,GraphQL Schema也允许我们在运行时发现GraphQL接口的使用方式。最后,类似于HitchHQ或Rapid API也为统一的API发布与注册提供了便捷支持。
延伸阅读
来自于PayPal的RESTful API标准
来自微软的接口设计指南