基于Seatunnel连通Hive数仓和ClickHouse的实战
背景
目前公司的分析数据基本存储在 Hive 数仓中,使用 Presto 完成 OLAP 分析,但是随着业务实时性增强,对查询性能的要求不断升高,同时许多数据应用产生,比如对接 BI 进行分析等,Presto不能满足需求,在这个阶段我们引入了ClickHouse,用来建设性能更强悍,响应时间更短的数据分析平台,以满足实时性要求,但如何连通 Hive 数仓和ClickHouse呢?
没错,当然是 Seatunnel 啦!
新版seatunnel2.1.0文章
01 环境准备
官方推荐的 seatunnel1.5.7+spark2.4.8+scala2.11
百度网盘自取:
链接: https://pan.baidu.com/s/1BZ8-oNXhRjmrqd3hW-KxXA 提取码: hevt
全部解压安装到/u/module下即可
[hadoop@hadoop101 module]$ unzip /u/software/19.Seatunnel/seatunnel-1.5.7.zip -d /u/module/
[hadoop@hadoop101 module]$ tar -zxvf /u/software/19.Seatunnel/spark-2.4.8-bin-hadoop2.7.tgz -C /u/module
[hadoop@hadoop101 module]$ tar -zxvf /u/software/19.Seatunnel/scala-2.11.8.tgz -C /u/module
将 hive-site.xml 复制到 spark2/conf 目录下,这里取的是从 hive 复制到 Hadoop 配置目录下的
[hadoop@hadoop101 module]$ cp $HADOOP_CONF/hive-site.xml /u/module/spark-2.4.8-bin-hadoop2.7/conf
注意:如果你跟我一样,原来 Hive 默认使用Spark3,那么需要设置一个 Spark2 的环境变量
[hadoop@hadoop101 module]$ sudo vim /etc/profile
# SPARK_HOME
export SPARK_HOME=/u/module/spark
export PATH=$PATH:$SPARK_HOME/bin
# SPARK_END
# 多版本共存Spark,for waterdrop and Hive
export SPARK2_HOME=/u/module/spark-2.4.8-bin-hadoop2.7
#Scala Env
export SCALA_HOME=/u/module/scala-2.11.8/
export PATH=$PATH:$SCALA_HOME/bin
[hadoop@hadoop101 module]$ source /etc/profile
创建jobs目录存放执行conf文件
[hadoop@hadoop101 module]$ mkdir /u/module/seatunnel-1.5.7/jobs
02 数据准备
Hive:
drop table if exists prod_info;
create table prod_info
(
prod_sn string comment 'sn',
create_time string comment '创建时间'
)COMMENT '产品信息表'
PARTITIONED BY (`dt` string)
STORED AS PARQUET
TBLPROPERTIES ("parquet.compression" = "lzo");
插入数据:
insert into prod_info values ('F0001','2022-01-18 00:00:00.0','2022-01-18');
insert into prod_info values ('F00012','2022-01-19 00:00:00.0','2022-01-19');
ClickHouse:
drop table if exists prod_info;
create table prod_info
(
prod_sn String,
create_time DateTime
)engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (prod_sn)
ORDER BY (prod_sn)
03 多表全量or增量数据导入CK
使用cat <
关键点:
1️⃣ 将输入参数封装成一个方法,方便一个脚本操作多个数仓表;
2️⃣ 加入CK远程执行命令,插入前清除分区,以免导入双倍数据;
3️⃣ 加入批量执行条件;
[hadoop@hadoop101 module]$ touch ~/bin/mytest.sh && chmod u+x ~/bin/mytest.sh && vim ~/bin/mytest.sh
注意:
- 这边 hive 中表压缩格式是 parquet+lzo ,读取出来没问题,插入时报错,我直接将之前搭建 Hadoop集群时$HADOOP_HOME/share/hadoop/common/hadoop-lzo-0.4.20.jar放到/u/module/spark-2.4.8-bin-hadoop2.7/jars(spark 目录下的 jars )下,即可解决,百度网盘也有 jar 包
- 若 hive 表中有做分区,则需指定 spark.sql.hive.manageFilesourcePartitions=false
#!/bin/bash
# 环境变量
unset SPARK_HOME
export SPARK_HOME=$SPARK2_HOME
SEATUNNEL_HOME=/u/module/seatunnel-1.5.7
CLICKHOUSE_CLIENT=/usr/bin/clickhouse-client
# 接收两个参数,第一个为要抽取的表,第二个为抽取时间
# 若输入的第一个值为first,不输入第二参数则直接退出脚本
if [[ $1 = first ]]; then
if [ -n "$2" ] ;then
do_date=$2
else
echo "请传入日期参数"
exit
fi
# 若输入的第一个值为all,不输入第二参数则取前一天
elif [[ $1 = all ]]; then
# 判断非空,如果不传时间默认取前一天数据,传时间就取设定,主要是用于手动传参
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
else
if [ -n "$2" ] ;then
do_date=$2
else
echo "请传入日期参数"
exit
fi
fi
echo "日期:$do_date"
import_conf(){
# 打印数据传输脚本并赋值
cat>$SEATUNNEL_HOME/jobs/hive2ck_test.conf<<!EOF
spark {
spark.sql.catalogImplementation = "hive"
spark.app.name = "hive2clickhouse"
spark.executor.instances = 4
spark.executor.cores = 4
spark.executor.memory = "4g"
# 此参数为调用Hive分区必带!
spark.sql.hive.manageFilesourcePartitions=false
}
input {
hive {
pre_sql = "$1"
table_name = "$2"
}
}
filter {}
output {
clickhouse {
host = "$3"
database = "$4"
table = "$5"
fields = $6
username = "default"
password = ""
}
}
!EOF
$SEATUNNEL_HOME/bin/start-seatunnel.sh --config $SEATUNNEL_HOME/jobs/hive2ck_test.conf -e client -m 'local[4]'
}
# 全量数据导入
import_prod_info_first(){
$CLICKHOUSE_CLIENT --host hadoop101 --database test --query="truncate table test.prod_info"
import_conf "select prod_sn,substring(create_time,1,19) as create_time from default.prod_info" "prod_info" "hadoop101:8123" "test" "prod_info" "[\"prod_sn\",\"create_time\"]"
}
# 增量数据导入
import_prod_info(){
do_date_2=`echo $do_date |sed 's/-//g'`
# 为避免重复导入,导入前先清除分区,这是在建立表分区的前提下
$CLICKHOUSE_CLIENT --host hadoop101 --database test --query="alter table test.prod_info drop partition '${do_date_2}'"
import_conf "select prod_sn,substring(create_time,1,19) as create_time from default.prod_info where dt='${do_date}'" "prod_info" "hadoop101:8123" "test" "prod_info" "[\"prod_sn\",\"create_time\"]"
}
case $1 in
"prod_info_first"){
import_prod_info_first
};;
"prod_info"){
import_prod_info
};;
"first"){
import_prod_info_first
};;
"all"){
import_prod_info
};;
"tmp"){
import_prod_info
};;
esac
03.1首日全量导入
执行首日全量导入,后面的 2022-01-19 是为了配合数仓流程加入的
[hadoop@hadoop101 bin]$ mytest.sh first 2022-01-19
ClickHouse中查看是否导入:
查看CK的当前分区:
select * from system.parts p where table = 'prod_info' order by partition desc ;

可见数据导入无误~
03.2每日增量导入
hive中新增记录测试增量更新:
hive> insert into prod_info values ('F000123','2022-01-20 00:00:00.0','2022-01-20');
[hadoop@hadoop101 bin]$ mytest.sh all 2022-01-20
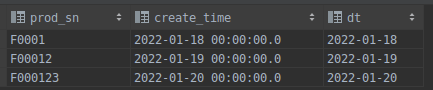
可见增量更新脚本也无误!
调试时可以修改 tmp 条件里的内容,进行测试。
生产环境可以配合调度工具如 Dolphin Scheduler、Azkaban 控制整个数据链路,监控多个脚本的分步执行情况,如出现问题可以及时定位解决。
04 总结
本文主要分享了一个基于 Seatunnel 的生产力脚本,介绍了如何连通 Hive 数仓与 ClickHouse ,将 ClickHouse 无缝加入离线数仓流程,并进行流程测试。实际生产使用时,数据传输速度飞快!