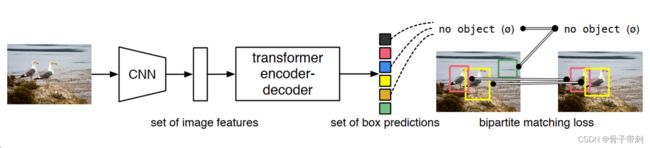
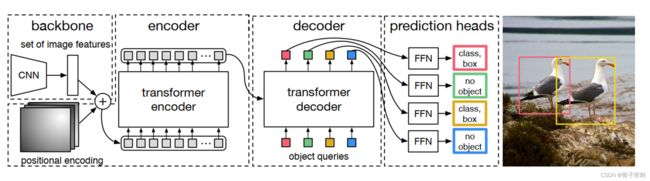
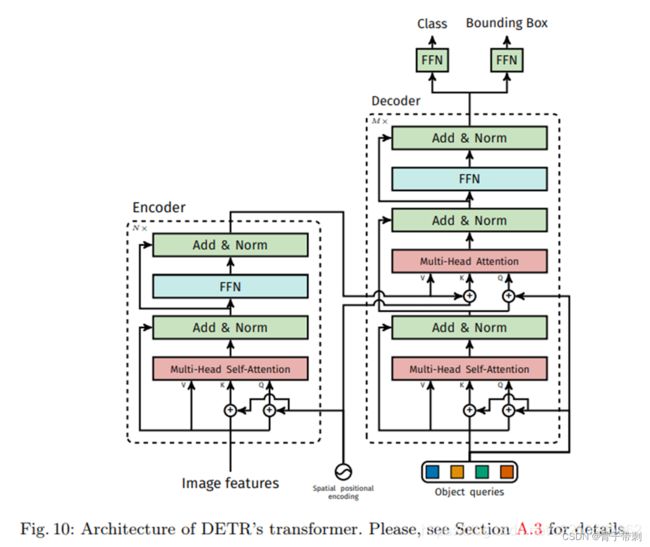
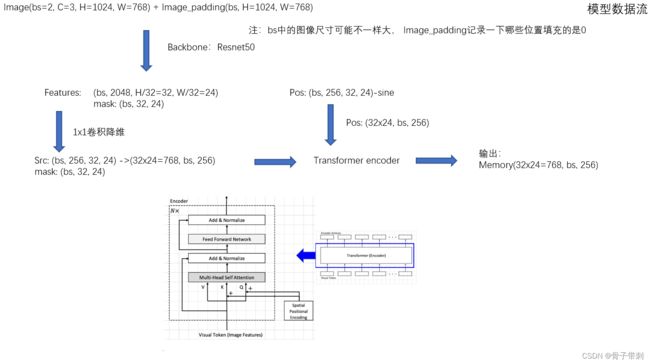
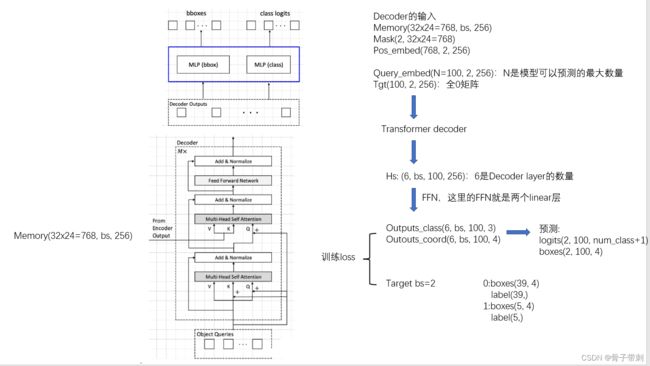
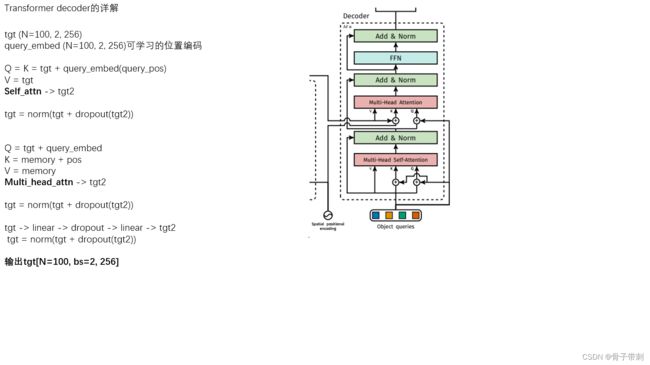
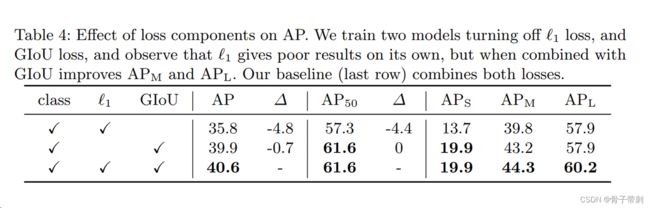
一、什么是宏函数?通过宏定义的函数是宏函数。如下,编译器在预处理阶段会将Add(x,y)替换为((x)*(y))#defineAdd(x,y)((x)*(y))#defineAdd(x,y)((x)*(y))intmain(){inta=10;intb=20;intd=10;intc=Add(a+d,b)*2;cout<
地推话术,如何应对地推过程中家长的拒绝
校师学
相信校长们在做地推的时候经常遇到这种情况:市场专员反馈家长不接单,咨询师反馈难以邀约这些家长上门,校区地推疲软,招生难。为什么?仅从地推层面分析,一方面因为家长受到的信息轰炸越来越多,对信息越来越“免疫”;而另一方面地推人员的专业能力和营销话术没有提高,无法应对家长的拒绝,对有意向的家长也不知如何跟进,眼睁睁看着家长走远;对于家长的疑问,更不知道如何有技巧地回答,机会白白流失。由于回答没技巧和专业
谢谢你们,爱你们!
鹿游儿
昨天家人去泡温泉,二个孩子也带着去,出发前一晚,匆匆下班,赶回家和孩子一起收拾。饭后,我拿出笔和本子(上次去澳门时做手帐的本子)写下了1\2\3\4\5\6\7\8\9,让后让小壹去思考,带什么出发去旅游呢?她在对应的数字旁边画上了,泳衣、泳圈、肖恩、内衣内裤、tapuy、拖鞋……画完后,就让她自己对着这个本子,将要带的,一一带上,没想到这次带的书还是这本《便便工厂》(晚上姑婆发照片过来,妹妹累得
C语言如何定义宏函数?
小九格物
c语言
在C语言中,宏函数是通过预处理器定义的,它在编译之前替换代码中的宏调用。宏函数可以模拟函数的行为,但它们不是真正的函数,因为它们在编译时不会进行类型检查,也不会分配存储空间。宏函数的定义通常使用#define指令,后面跟着宏的名称和参数列表,以及宏展开后的代码。宏函数的定义方式:1.基本宏函数:这是最简单的宏函数形式,它直接定义一个表达式。#defineSQUARE(x)((x)*(x))2.带参
微服务下功能权限与数据权限的设计与实现
nbsaas-boot
微服务java架构
在微服务架构下,系统的功能权限和数据权限控制显得尤为重要。随着系统规模的扩大和微服务数量的增加,如何保证不同用户和服务之间的访问权限准确、细粒度地控制,成为设计安全策略的关键。本文将讨论如何在微服务体系中设计和实现功能权限与数据权限控制。1.功能权限与数据权限的定义功能权限:指用户或系统角色对特定功能的访问权限。通常是某个用户角色能否执行某个操作,比如查看订单、创建订单、修改用户资料等。数据权限:
理解Gunicorn:Python WSGI服务器的基石
范范0825
ipythonlinux运维
理解Gunicorn:PythonWSGI服务器的基石介绍Gunicorn,全称GreenUnicorn,是一个为PythonWSGI(WebServerGatewayInterface)应用设计的高效、轻量级HTTP服务器。作为PythonWeb应用部署的常用工具,Gunicorn以其高性能和易用性著称。本文将介绍Gunicorn的基本概念、安装和配置,帮助初学者快速上手。1.什么是Gunico
小丽成长记(四十三)
玲玲54321
小丽发现,即使她好不容易调整好自己的心态下一秒总会有不确定的伤脑筋的事出现,一个接一个的问题,人生就没有停下的时候,小问题不断出现。不过她今天看的书,她接受了人生就是不确定的,厉害的人就是不断创造确定性,在Ta的领域比别人多的确定性就能让自己脱颖而出,显示价值从而获得的比别人多的利益。正是这样的原因,因为从前修炼自己太少,使得她现在在人生道路上打怪起来困难重重,她似乎永远摆脱不了那种无力感,有种习
学点心理知识,呵护孩子健康
静候花开_7090
昨天听了华中师范大学教育管理学系副教授张玲老师的《哪里才是学生心理健康的最后庇护所,超越教育与技术的思考》的讲座。今天又重新学习了一遍,收获匪浅。张玲博士也注意到了当今社会上的孩子由于心理问题导致的自残、自杀及伤害他人等恶性事件。她向我们普及了一个重要的命题,她说心理健康的一些基本命题,我们与我们通常的一些教育命题是不同的,她还举了几个例子,让我们明白我们原来以为的健康并非心理学上的健康。比如如果
2021年12月19日,春蕾教育集团团建活动感受——黄晓丹
黄错错加油
感受:1.从陌生到熟悉的过程。游戏环节让我们在轻松的氛围中得到了锻炼,也增长了不少知识。2.游戏过程中,我们贡献的是个人力量,展现的是团队的力量。它磨合的往往不止是工作的熟悉,更是观念上契合度的贴近。3.这和工作是一样的道理。在各自的岗位上,每个人摆正自己的位置、各司其职充分发挥才能,并团结一致劲往一处使,才能实现最大的成功。新知:1.团队精神需要不断地创新。过去,人们把创新看作是冒风险,现在人们
Cell Insight | 单细胞测序技术又一新发现,可用于HIV-1和Mtb共感染个体诊断
尐尐呅
结核病是艾滋病合并其他疾病中导致患者死亡的主要原因。其中结核病由结核分枝杆菌(Mycobacteriumtuberculosis,Mtb)感染引起,获得性免疫缺陷综合症(艾滋病)由人免疫缺陷病毒(Humanimmunodeficiencyvirustype1,HIV-1)感染引起。国家感染性疾病临床医学研究中心/深圳市第三人民医院张国良团队携手深圳华大生命科学研究院吴靓团队,共同研究得出单细胞测序
c++ 的iostream 和 c++的stdio的区别和联系
黄卷青灯77
c++算法开发语言iostreamstdio
在C++中,iostream和C语言的stdio.h都是用于处理输入输出的库,但它们在设计、用法和功能上有许多不同。以下是两者的区别和联系:区别1.编程风格iostream(C++风格):C++标准库中的输入输出流类库,支持面向对象的输入输出操作。典型用法是cin(输入)和cout(输出),使用>操作符来处理数据。更加类型安全,支持用户自定义类型的输入输出。#includeintmain(){in
瑶池防线
谜影梦蝶
冥华虽然逃过了影梦的军队,但他是一个忠臣,他选择上报战况。败给影梦后成逃兵,高层亡尔还活着,七重天失守......随便一条,即可处死冥华。冥华自然是知道以仙界高层的习性此信一发自己必死无疑,但他还选择上报实情,因为责任。同样此信送到仙宫后,知道此事的人,大多数人都认定冥华要完了,所以上到仙界高层,下到扫大街的,包括冥华自己,全都准备好迎接冥华之死。如果仙界现在还属于两方之争的话,冥华必死无疑。然而
爬山后遗症
璃绛
爬山,攀登,一步一步走向制高点,是一种挑战。成功抵达是一种无法言语的快乐,在山顶吹吹风,看看风景,这是从未有过的体验。然而,爬山一时爽,下山腿打颤,颠簸的路,一路向下走,腿部力量不够,走起来抖到不行,停不下来了!第二天必定腿疼,浑身酸痛,坐立难安!
[黑洞与暗粒子]没有光的世界
comsci
无论是相对论还是其它现代物理学,都显然有个缺陷,那就是必须有光才能够计算
但是,我相信,在我们的世界和宇宙平面中,肯定存在没有光的世界....
那么,在没有光的世界,光子和其它粒子的规律无法被应用和考察,那么以光速为核心的
&nbs
jQuery Lazy Load 图片延迟加载
aijuans
jquery
基于 jQuery 的图片延迟加载插件,在用户滚动页面到图片之后才进行加载。
对于有较多的图片的网页,使用图片延迟加载,能有效的提高页面加载速度。
版本:
jQuery v1.4.4+
jQuery Lazy Load v1.7.2
注意事项:
需要真正实现图片延迟加载,必须将真实图片地址写在 data-original 属性中。若 src
使用Jodd的优点
Kai_Ge
jodd
1. 简化和统一 controller ,抛弃 extends SimpleFormController ,统一使用 implements Controller 的方式。
2. 简化 JSP 页面的 bind, 不需要一个字段一个字段的绑定。
3. 对 bean 没有任何要求,可以使用任意的 bean 做为 formBean。
使用方法简介
jpa Query转hibernate Query
120153216
Hibernate
public List<Map> getMapList(String hql,
Map map) {
org.hibernate.Query jpaQuery = entityManager.createQuery(hql);
if (null != map) {
for (String parameter : map.keySet()) {
jp
Django_Python3添加MySQL/MariaDB支持
2002wmj
mariaDB
现状
首先,
[email protected] 中默认的引擎为 django.db.backends.mysql 。但是在Python3中如果这样写的话,会发现 django.db.backends.mysql 依赖 MySQLdb[5] ,而 MySQLdb 又不兼容 Python3 于是要找一种新的方式来继续使用MySQL。 MySQL官方的方案
首先据MySQL文档[3]说,自从MySQL
返回做IO数目最多的50条语句以及它们的执行计划。
select top 50
(total_logical_reads/execution_count) as avg_logical_reads,
(total_logical_writes/execution_count) as avg_logical_writes,
(tot
spring UnChecked 异常 官方定义!
7454103
spring
如果你接触过spring的 事物管理!那么你必须明白 spring的 非捕获异常! 即 unchecked 异常! 因为 spring 默认这类异常事物自动回滚!!
public static boolean isCheckedException(Throwable ex)
{
return !(ex instanceof RuntimeExcep
mongoDB 入门指南、示例
adminjun
javamongodb操作
一、准备工作
1、 下载mongoDB
下载地址:http://www.mongodb.org/downloads
选择合适你的版本
相关文档:http://www.mongodb.org/display/DOCS/Tutorial
2、 安装mongoDB
A、 不解压模式:
将下载下来的mongoDB-xxx.zip打开,找到bin目录,运行mongod.exe就可以启动服务,默
CUDA 5 Release Candidate Now Available
aijuans
CUDA
The CUDA 5 Release Candidate is now available at http://developer.nvidia.com/<wbr></wbr>cuda/cuda-pre-production. Now applicable to a broader set of algorithms, CUDA 5 has advanced fe
Essential Studio for WinRT网格控件测评
Axiba
JavaScripthtml5
Essential Studio for WinRT界面控件包含了商业平板应用程序开发中所需的所有控件,如市场上运行速度最快的grid 和chart、地图、RDL报表查看器、丰富的文本查看器及图表等等。同时,该控件还包含了一组独特的库,用于从WinRT应用程序中生成Excel、Word以及PDF格式的文件。此文将对其另外一个强大的控件——网格控件进行专门的测评详述。
网格控件功能
1、
java 获取windows系统安装的证书或证书链
bewithme
windows
有时需要获取windows系统安装的证书或证书链,比如说你要通过证书来创建java的密钥库 。
有关证书链的解释可以查看此处 。
public static void main(String[] args) {
SunMSCAPI providerMSCAPI = new SunMSCAPI();
S
NoSQL数据库之Redis数据库管理(set类型和zset类型)
bijian1013
redis数据库NoSQL
4.sets类型
Set是集合,它是string类型的无序集合。set是通过hash table实现的,添加、删除和查找的复杂度都是O(1)。对集合我们可以取并集、交集、差集。通过这些操作我们可以实现sns中的好友推荐和blog的tag功能。
sadd:向名称为key的set中添加元
异常捕获何时用Exception,何时用Throwable
bingyingao
用Exception的情况
try {
//可能发生空指针、数组溢出等异常
} catch (Exception e) {
【Kafka四】Kakfa伪分布式安装
bit1129
kafka
在http://bit1129.iteye.com/blog/2174791一文中,实现了单Kafka服务器的安装,在Kafka中,每个Kafka服务器称为一个broker。本文简单介绍下,在单机环境下Kafka的伪分布式安装和测试验证 1. 安装步骤
Kafka伪分布式安装的思路跟Zookeeper的伪分布式安装思路完全一样,不过比Zookeeper稍微简单些(不
Project Euler
bookjovi
haskell
Project Euler是个数学问题求解网站,网站设计的很有意思,有很多problem,在未提交正确答案前不能查看problem的overview,也不能查看关于problem的discussion thread,只能看到现在problem已经被多少人解决了,人数越多往往代表问题越容易。
看看problem 1吧:
Add all the natural num
Java-Collections Framework学习与总结-ArrayDeque
BrokenDreams
Collections
表、栈和队列是三种基本的数据结构,前面总结的ArrayList和LinkedList可以作为任意一种数据结构来使用,当然由于实现方式的不同,操作的效率也会不同。
这篇要看一下java.util.ArrayDeque。从命名上看
读《研磨设计模式》-代码笔记-装饰模式-Decorator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.io.BufferedOutputStream;
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.Fi
Maven学习(一)
chenyu19891124
Maven私服
学习一门技术和工具总得花费一段时间,5月底6月初自己学习了一些工具,maven+Hudson+nexus的搭建,对于maven以前只是听说,顺便再自己的电脑上搭建了一个maven环境,但是完全不了解maven这一强大的构建工具,还有ant也是一个构建工具,但ant就没有maven那么的简单方便,其实简单点说maven是一个运用命令行就能完成构建,测试,打包,发布一系列功
[原创]JWFD工作流引擎设计----节点匹配搜索算法(用于初步解决条件异步汇聚问题) 补充
comsci
算法工作PHP搜索引擎嵌入式
本文主要介绍在JWFD工作流引擎设计中遇到的一个实际问题的解决方案,请参考我的博文"带条件选择的并行汇聚路由问题"中图例A2描述的情况(http://comsci.iteye.com/blog/339756),我现在把我对图例A2的一个解决方案公布出来,请大家多指点
节点匹配搜索算法(用于解决标准对称流程图条件汇聚点运行控制参数的算法)
需要解决的问题:已知分支
Linux中用shell获取昨天、明天或多天前的日期
daizj
linuxshell上几年昨天获取上几个月
在Linux中可以通过date命令获取昨天、明天、上个月、下个月、上一年和下一年
# 获取昨天
date -d 'yesterday' # 或 date -d 'last day'
# 获取明天
date -d 'tomorrow' # 或 date -d 'next day'
# 获取上个月
date -d 'last month'
#
我所理解的云计算
dongwei_6688
云计算
在刚开始接触到一个概念时,人们往往都会去探寻这个概念的含义,以达到对其有一个感性的认知,在Wikipedia上关于“云计算”是这么定义的,它说:
Cloud computing is a phrase used to describe a variety of computing co
YII CMenu配置
dcj3sjt126com
yii
Adding id and class names to CMenu
We use the id and htmlOptions to accomplish this. Watch.
//in your view
$this->widget('zii.widgets.CMenu', array(
'id'=>'myMenu',
'items'=>$this-&g
设计模式之静态代理与动态代理
come_for_dream
设计模式
静态代理与动态代理
代理模式是java开发中用到的相对比较多的设计模式,其中的思想就是主业务和相关业务分离。所谓的代理设计就是指由一个代理主题来操作真实主题,真实主题执行具体的业务操作,而代理主题负责其他相关业务的处理。比如我们在进行删除操作的时候需要检验一下用户是否登陆,我们可以删除看成主业务,而把检验用户是否登陆看成其相关业务
【转】理解Javascript 系列
gcc2ge
JavaScript
理解Javascript_13_执行模型详解
摘要: 在《理解Javascript_12_执行模型浅析》一文中,我们初步的了解了执行上下文与作用域的概念,那么这一篇将深入分析执行上下文的构建过程,了解执行上下文、函数对象、作用域三者之间的关系。函数执行环境简单的代码:当调用say方法时,第一步是创建其执行环境,在创建执行环境的过程中,会按照定义的先后顺序完成一系列操作:1.首先会创建一个
Subsets II
hcx2013
set
Given a collection of integers that might contain duplicates, nums, return all possible subsets.
Note:
Elements in a subset must be in non-descending order.
The solution set must not conta
Spring4.1新特性——Spring缓存框架增强
jinnianshilongnian
spring4
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
shell嵌套expect执行命令
liyonghui160com
一直都想把expect的操作写到bash脚本里,这样就不用我再写两个脚本来执行了,搞了一下午终于有点小成就,给大家看看吧.
系统:centos 5.x
1.先安装expect
yum -y install expect
2.脚本内容:
cat auto_svn.sh
#!/bin/bash
Linux实用命令整理
pda158
linux
0. 基本命令 linux 基本命令整理
1. 压缩 解压 tar -zcvf a.tar.gz a #把a压缩成a.tar.gz tar -zxvf a.tar.gz #把a.tar.gz解压成a
2. vim小结 2.1 vim替换 :m,ns/word_1/word_2/gc
独立开发人员通向成功的29个小贴士
shoothao
独立开发
概述:本文收集了关于独立开发人员通向成功需要注意的一些东西,对于具体的每个贴士的注解有兴趣的朋友可以查看下面标注的原文地址。
明白你从事独立开发的原因和目的。
保持坚持制定计划的好习惯。
万事开头难,第一份订单是关键。
培养多元化业务技能。
提供卓越的服务和品质。
谨小慎微。
营销是必备技能。
学会组织,有条理的工作才是最有效率的。
“独立
JAVA中堆栈和内存分配原理
uule
java
1、栈、堆
1.寄存器:最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制.2. 栈:存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在堆(new 出来的对象)或者常量池中(字符串常量对象存放在常量池中。)3. 堆:存放所有new出来的对象。4. 静态域:存放静态成员(static定义的)5. 常量池:存放字符串常量和基本类型常量(public static f