SOLOv2: Dynamic and Fast Instance Segmentation
简介
这是实例分割的方法。实例分割一般有两种做法,一种是top-down,既先检测 bbox,后在每个bbox中进行mask的分割,例如Mask R-CNN。第二种为bottom-up做法,先分割出每一个像素,再进行归类,我觉得solov2就是这种做法。
数据的输入输出
训练
输入:
Image (bs, H, W, C)
label:
bboxes(bs, N, 4)
classes(bs, N)
masks(bs, N, H, W)
输出:
cate_pred (bs*3872, 80)
注:80是类别数量,3872是grids的面积和(40^2,36^2,24^2,16^2,12^2)
ins_pred (n, 240, 176)
注:240x176是原图1/4尺度的特征图大小
推理
输入:
Image (bs, H, W, C)
输出:
classes: (bs, n)
masks (bs, n, h, w)
网络架构与数据在模型中的流动

注意下几个设置
strides[8, 8, 16, 32, 32]
scale_ranges[(1, 96), (48, 192), (96, 384), (192, 768), (384, 2048)]
num_grids[40, 36, 24, 16, 12]
在模型中会计算bboxes的面积,判断面积在哪个范围,就使用对应的网格
(1, 96)->40
(48, 192)->36
(96, 384)->24
(192, 768)->16
(384, 2048)->12
Image经过预处理,变成[bs, 960, 704],经过backbone:resnet+FPN提取特征,FPN特征P2-P5以1/4尺度合成单个输出[bs, 256, 240, 176]。下图是网上找了一个resnet50+FPN的流程图,流程是一样的。
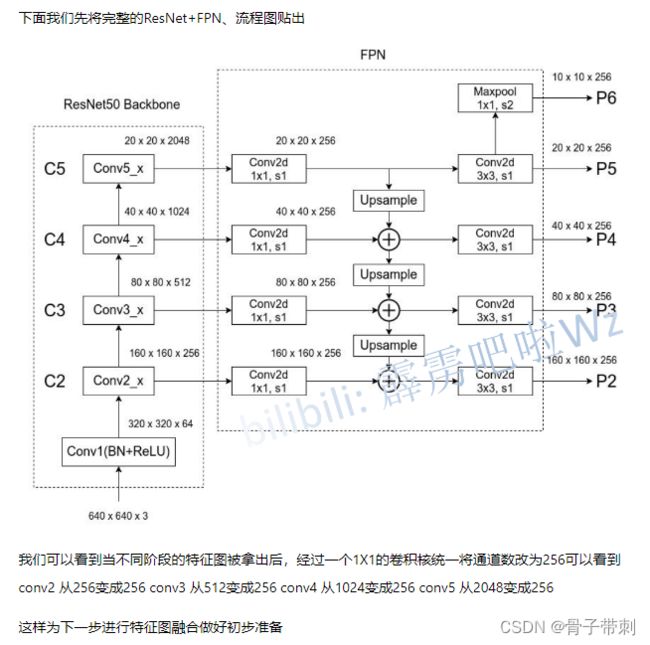
下图是FPN特征P2-P5以1/4尺度合成单个输出[bs, 256, 240, 176]的过程。
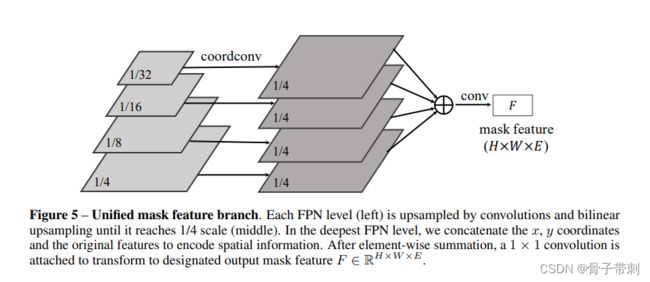
来说一下ground truth是怎么处理的?
label:
bboxes(bs, N, 4)
classes(bs, N)
masks(bs, N, H, W)
在模型中会计算bboxes的面积,判断面积在哪个范围,就使用对应的网格
(1, 96)->40
(48, 192)->36
(96, 384)->24
(192, 768)->16
(384, 2048)->12
之后求出mask的质心,center_w,center_h
top_bbox/grids = (center_h - half_h)/原图高
down_bbox/grids = (center_h + half_h)/原图高
left_bbox/grids = (center_w - half_w)/原图宽
right_bbox/grids = (center_w + half_w)/原图宽
得到bbox在grids内对应的框(top_bbox, down_bbox, left_bbox, right_bbox)
grids里面bbox内每一个像素点都打上gt-label对应类别的标签
ins_ind_label(1600, )中对应的像素点置为true,假设grids是40的话
grid_order记录遍历的像素点 int(i*grid + j)
gt_masks scale到特征图大小(240, 176),赋值给ins_label
生成对应的计算loss的几个变量
ins_label_list[bs, N, 240, 176]
cate_label_list[bs, 40, 40], [bs, 36, 36], [bs, 24, 24], [bs, 16, 16], [bs, 12, 12]---->[bs*3872, ]
ins_ind_label_list[bs, 1600], [bs, 1296], [bs, 576], [bs, 256], [bs, 144]
grid_order_list[bs, N] (跟kernel_preds有关)
怎么求出prediction的相关变量?
特征图大小:[bs, 256, 240, 176]
cate_preds [bs, 80, 40, 40], [bs, 80, 36, 36], [bs, 80, 24, 24], [bs, 80, 16, 16], [bs, 80, 12, 12]---->[bs*3872, 80]
注:80是类别的数量
kernel_preds [bs, 256, 40, 40], [bs, 256, 36, 36], [bs, 256, 24, 24], [bs, 256, 16, 16], [bs, 256, 12, 12]
mask_feat_pred [bs, 256, 240, 176]
注:每个grid,根据grid_order_list知道i、j,然后知道kernel G_(i,j),kernel G_(i,j)和mask_feat_pred卷积---->
---->ins_pred [bs, N, 240, 176]
loss部分
分成两个部分:
-
分类部分:Focal loss
cate_label_list:[bs3872, ]
cate_preds :[bs3872, 80] -
mask部分:dice loss
ins_label_list:[bs, N, 240, 176]
ins_pred [bs, N, 240, 176]
评估结果
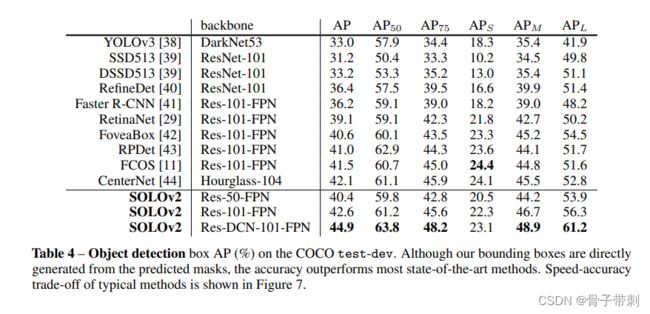
疑问
cate_preds [bs, 80, 40, 40], [bs, 80, 36, 36], [bs, 80, 24, 24], [bs, 80, 16, 16], [bs, 80, 12, 12]---->[bs*3872, 80]
kernel_preds [bs, 256, 40, 40], [bs, 256, 36, 36], [bs, 256, 24, 24], [bs, 256, 16, 16], [bs, 256, 12, 12]
mask_feat_pred [bs, 256, 240, 176]
是怎么得到的?