GPGPU-SIM(原码阅读)(流多处理器部分完成)
GPGPU-SIM(原码阅读)1.0
顶层设计
GPGPU-Sim的模拟是由单指令多线程(SIMT)内核组成,这些内核通过片上互接网络连接到与图形GDDR DRAM接口的内存分区。
SIMT核心模拟了高度多线程流水的SIMD处理器,大致相当于NVIDIA称之为流式多处理器(SM)或AMD称为计算单元(CU)的处理器。 SIMT核心的组织如下面的图1所示。
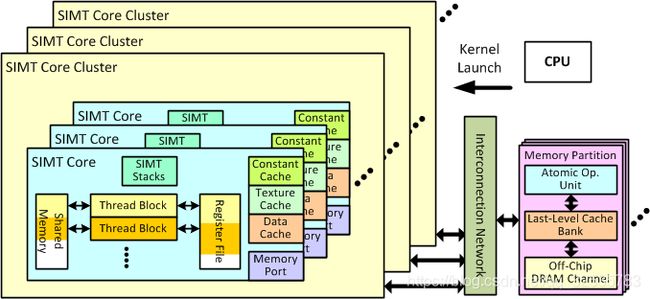
SIMT核心集群
SIMT核心组织为为SIMT核心集群。SIMT核心集群中的SIMT核心共享一个连接到互连网络的公共端口,如图2所示。

如图2所示,每个SIMT核心集群都有一个响应FIFO队列,用于保存从互连网络中弹出的数据包。 数据包被定向送到SIMT Core的指令高速缓存(如果它是服务于取指令未命中的存储器响应)或其存储器流水(LDST单元)。数据包以FIFO方式流出。如果内核无法接受FIFO头部的数据包,则响应FIFO将停止。为了在LDST单元处生成存储器请求,每个SIMT核心具有其到互连网络中Injection Port。 但是,Injection Port缓冲区由集群中的所有SIMT核共享。
SIMT核心
下面的图3说明了GPGPU-Sim 3.x模拟的SIMT核心微体系结构。 SIMT内核模拟高度多线程流水的SIMD处理器,大致相当于:
- NVIDIA称之为流式多处理器(SM)
(http://developer.nvidia.com/nvidia-gpu-computing-documentation) - AMD称之为计算单元(CU)
(http://developer.amd.com/gpu_assets/GPU Computing Past Present and Future with ATI Stream Technology.pdf) - 流处理器(SP)
- CUDA核将对应于SIMT核中的ALU流水线内的通道

这个微体系结构模型包含许多早期版本的GPGPUSim中没有的细节。 主要区别包括:
- 一个新的前端,它模拟指令缓存并将warp调度(问题)阶段与获取和解码阶段分开
- 记分板逻辑允许来自单个warp的多个指令同时在流水线中
- 操作数收集器的详细模型,用于调度对单端口寄存器文件库的操作数访问(用于减少寄存器文件的区域和功率)
- 灵活的模型,支持多个SIMD功能单元。 这允许存储器指令和ALU指令在不同的流水线中操作
以下小节通过遍历管道的每个阶段来描述图3中的细节
前端
如下所述,前端的主要阶段包括指令高速缓存访问和指令缓冲逻辑,记分板和调度逻辑,SIMT栈。
1. 取址和译码
图3中的指令缓冲区(I-Buffer)块用于在从指令高速缓存中取出指令后对指令进行缓冲。 它是静态分区的,因此在SIMT内核上运行的所有warp都有专用存储来放置指令。在当前模型中,每个warp都有两个I-Buffer条目。每个I-Buffer条目都有一个有效位,就绪位和用于该warp的单个解码指令。 条目的有效位表示在I-Buffer中的该条目内存在未流入流水线的解码指令。 就绪位表示该warp的解码指令已准备好流入到执行流水线。 从概念上讲,使用记分板逻辑和硬件资源的可用性在计划和发布阶段设置就绪位(在模拟器软件中,而不是实际设置就绪位,执行就绪检查)。I-Buffer最初为空,所有有效位和就绪位均被置为无效。
如果在IBuffer中没有任何有效指令,则warp有资格获取指令。 符合条件的warp计划以循环顺序访问指令缓存。 一旦被选中,读取请求就被发送到指令高速缓存,其具有当前调度的warp中的下一指令的地址。 默认情况下,提取两个连续的指令。 一旦为取指令调度了warp,就会激活I-Buffer中的有效位,直到该warp的所有读取指令都被发送到执行流水线。
指令高速缓存是一个只读,非阻塞的组关联高速缓存,可以使用on-miss或on-fill分配策略对FIFO和LRU替换策略建模。 对指令高速缓存的请求导致命中,未命中或保留失败。 如果未命中状态保持寄存器(MSHR)已满或高速缓存集中没有可替换块,则会导致保留失败,因为所有块都是由先前的待处理请求保留的。 在命中和未命中的两种情况下,循环获取调度程序移动到下一个warp。 在命中的情况下,所获取的指令被发送到解码阶段。 在未命中的情况下,指令高速缓存将生成请求。 当接收到未命中响应时,块被填充到指令高速缓存中,并且warp将再次需要访问指令高速缓存。 当未命中时,warp不访问指令高速缓存。
如果所有线程都已完成执行而没有任何未完成的存储或对本地寄存器的挂起写入,则warp将完成执行并且不再被fetch调度程序考虑。 一旦线程块中的所有warp完成并且没有挂起操作,则认为该块已完成。 一旦在内核启动完成后调度所有线程块,就会认为此内核已完成。
在解码阶段,最近获取的指令被解码并存储在等待进入流水线的I-Buffer中的相应条目中。
此阶段的模拟器软件设计在取址和译码中描述。
2.指令发布
第二轮循环仲裁器选择从I-Buffer向管道的其余部分发出warp。 该循环仲裁器与用于调度指令高速缓存访问的循环仲裁器分离。 问题调度程序可以配置为每个周期从相同的warp发出多个指令。 如果(1)其warp没有在栅栏处等待,则当前检查的warp中的每个有效指令(即已解码且未发出)都有资格发出,(2)它在其I-Buffer条目中有有效指令(有效位设置) ),(3)记分板检查通过(更多细节见记分板部分),以及(4)指令管道的操作数访问阶段没有停止。
内存指令(加载,存储或内存屏障)发布到内存流水线。 对于其他指令,它始终优先使用SP管道来执行可以同时使用SP和SFU管道的操作。 但是,如果检测到控制危险,则刷新与该经线相对应的I-Buffer中的指令。 warp的下一个pc被更新为指向下一条指令(假设所有分支都未被采用)。 有关处理控制流的更多信息,请参阅SIMT堆栈。
在发布阶段,执行屏障操作。 此外,更新SIMT堆栈(有关更多详细信息,请参阅SIMT堆栈)并跟踪寄存器依赖关系(有关详细信息,请参阅记分板)。 Warp在问题阶段等待障碍("__syncthreads()")。
3.SIMT堆栈
每个warp SIMT堆栈用于处理单指令,多线程(SIMT)架构上的分支发散的执行。 由于分歧会降低这些架构的效率,因此可以采用不同的技术来降低这种影响。 最简单的技术之一是后支配者基于堆栈的重新收敛机制。 该技术在最早保证的再收敛点处同步发散分支,以便提高SIMT架构的效率。 与以前版本的GPGPU-Sim一样,GPGPU-Sim 3.x采用这种机制。
SIMT堆栈的条目表示不同的分歧级别。 在每个分歧分支处,新条目被推到堆栈的顶部。 当warp达到其重新收敛点时,将弹出堆栈顶部条目。 每个条目存储新分支的目标PC,即时支配者重新收敛PC以及分支到该分支的线程的活动掩码。 在我们的模型中,每个warp的SIMT堆栈在每次指令发出此warp后更新。 在没有分歧的情况下,目标PC通常更新到下一个PC。 然而,在出现分歧的情况下,新条目被推送到具有新目标PC的堆栈,该活动掩码对应于分散到该PC的线程以及它们的即时重新收敛点PC。 因此,如果SIMT堆栈顶部入口处的下一个PC不等于当前正在检查的指令的PC,则检测到控制危险。
请注意,众所周知,NVIDIA和AMD实际上使用特殊指令修改了它们的发散堆栈的内容。 这些发散堆栈指令不在PTX中公开,但在实际硬件SASS指令集中可见(使用decuda或NVIDIA的cuobjdump可见)。 当当前版本的GPGPU-Sim 3.x配置为通过PTXPlus执行SASS时(参见PTX与PTXPlus),它忽略这些低级指令,而是创建一个可比较的控制流图来识别直接后支配者。 我们计划在GPGPU-Sim 3.x的未来版本中支持执行低级分支指令。
4.计分板
记分板算法检查WAW和RAW相关危险。 如上所述,由warp写入的寄存器在发布阶段被保留。 记分板算法由warp ID索引。 它将所需的寄存器编号存储在与warp ID对应的条目中。 保留的寄存器在写回阶段被释放。
如上所述,在记分板指示不存在WAW或RAW危险之前,不会安排解码的warp指令。 记分板通过跟踪已发出但尚未将其结果写回寄存器文件的指令写入哪些寄存器来检测WAW和RAW危险。
寄存器访问和操作数收集器
各种NVIDIA专利描述了一种称为“操作数收集器”的结构。 操作数收集器是一组缓冲器和仲裁逻辑,用于使用多组单端口RAM提供多端口寄存器文件的外观。 整体布置节省了能量和面积,这对提高产量很重要。 请注意,AMD也使用库存寄存器文件,但编译器负责确保访问这些文件,以免发生库冲突。
图4提供了GPGPU-Sim 3.x为操作数收集器建模的详细方式的说明。

在解码指令之后,分配buffer给称为收集器单元的硬件单元的指令的源操作数。
收集器单元不是用于通过寄存器重命名来消除名称相关性,而是用作空间寄存器操作数访问的方式,以便在单个周期中对一个存储区进行不超过一次的访问。 在图中所示的组织中,四个收集器单元中的每一个包含三个操作数条目。 每个操作数条目有四个字段:有效位,寄存器标识符,就绪位和操作数数据。 每个操作数数据字段可以保存由32个四字节元素组成的单个128字节源操作数(warp中每个标量线程的一个四字节值)。 另外,收集器单元包含指示指令属于哪个warp的标识符。 仲裁程序包含每个银行的读取请求队列,用于保存访问请求,直到它们被授予为止。
当从解码级接收到指令并且收集器单元可用时,将其分配给指令,并设置操作数,warp,寄存器标识符和有效位。 此外,源操作数读取请求在仲裁器中排队。 为简化设计,执行单元写回的数据始终优先于读取请求。 仲裁器选择一组最多四个非冲突访问以发送到寄存器文件。 为了减少交叉开关和收集器单元区域,进行选择以使每个收集器单元每循环仅接收一个操作数。
当每个操作数从寄存器文件中读出并放入相应的收集器单元时,设置“就绪位”。 最后,当所有操作数都准备好时,将指令发送到SIMD执行单元。
在GPGPU-SIM的模型中,每个后端管道(SP,SFU,MEM)都有一组专用的收集器单元,它们共享一个通用收集器单元池。 每个管道可用的单元数和一般单元池的容量是可配置的。
ALU 流水线
GPGPU-Sim v3.x模拟两种类型的ALU功能单元。
- SP单元执行除transcendentals之外的所有类型的ALU指令。
- SFU单元执行超越指令(正弦,余弦,对数…等)
两种类型的单元都是流水线和SIMD化的。 SP单元通常每个周期执行一个warp指令,而SFU单元每隔几个周期只能执行一个新的warp指令,具体取决于指令类型。 例如,SFU单元可以每4个周期执行一次正弦指令或每2个周期执行一次倒数指令。 不同类型的指令也具有不同的执行延迟。
每个SIMT核心都有一个SP单元和一个SFU单元。 每个单元都有一个来自操作数收集器的独立发出端口。 两个单元共享相同的输出流水线寄存器,连接到公共写回级。 在操作数收集器的输出端有一个结果总线分配器,以确保单元永远不会因共享写回而停止。 每条指令都需要在发送到任一单元之前在结果总线中分配一个循环槽。 请注意,内存管道具有自己的回写阶段,并且不由此结果总线分配器管理。
软件设计部分包含模型的更多实现细节。
内存流水线(LDST单元)
GPGPU-Sim支持在PTX中可见的CUDA中的各种存储空间。 在我们的模型中,每个SIMT内核都有4个不同的片上1级存储器:共享存储器,数据缓存,常量缓存和Texture缓存。 下表显示哪些片上存储器服务哪种类型的存储器访问:
| 核心内存 | PTX访问 |
|---|---|
| 共享内存(R / W) | CUDA共享内存(OpenCL本地内存)仅访问 |
| 常量缓存(只读) | 恒定的内存和参数内存 |
| Texture 缓存 (只读) | 仅Texture访问 |
| 数据缓存(R / W - 全局内存的evict-on-write,本地内存的回写) | 全局和本地内存访问(本地内存= OpenCL中的私有数据) |
虽然它们被建模为单独的物理结构,但它们都是存储器流水线(LDST单元)的所有组件,因此它们都共享相同的写回阶段。 以下描述了如何为每个空间提供服务:
- Texture存储器 - 纹理存储器的访问缓存在L1纹理缓存(仅用于纹理访问)和L2缓存(如果启用)中。L1纹理缓存是1998年论文中描述的特殊设计。GPU上的线程无法写入纹理内存空间,因此L1纹理缓存是只读的。(http://wwwgraphics.stanford.edu/papers/texture_prefetch/)
- 共享内存 - 每个SIMT内核包含可配置数量的共享暂存器内存,可由线程块内的线程共享。 此内存空间不受任何L2的支持,并由程序员明确管理。
- 常量内存 - 常量和参数内存缓存在只读常量缓存中。
- 参数内存 - 见上文
- 本地内存 - 缓存在L1数据缓存中并由L2支持。 以类似于下面的全局存储器的方式处理,除了在驱逐时写回值,因为不能共享本地(私有)数据。
- 全局内存 - 全局和本地访问都由L1数据缓存提供服务。 如CUDA 3.1编程指南中所述,来自相同warp的标量线程的访问以半翘曲的方式合并。 这些访问以每SIMT核心周期2的速率进行处理,使得可以在单个周期中服务完全合并为2次访问(每个半经线一次)的存储器指令。 对于那些产生2次以上访问的指令,这些指令将以每个周期2的速率访问存储器系统。 因此,如果存储器指令产生32次访问(warp中每个通道一次),则至少需要16个SIMT核心周期才能将指令移动到下一个流水线级。
(http://developer.nvidia.com/nvidiagpu-computing-documentation)
下面的小节描述了第一级存储器结构。
L1 数据缓存
L1数据高速缓存是一个私有的,每SIMT核心,非阻塞的第一级高速缓存,用于本地和全局内存访问。 L1高速缓存未存储,并且能够为每个SIMT核心周期服务两个合并的存储器请求。 传入内存请求不得跨越L1数据高速缓存中的两个或多个高速缓存行。 另请注意,L1数据高速缓存不一致。
下表总结了L1数据高速缓存的写策略。
| 本地内存 | 全局内存 | |
|---|---|---|
| 写命中 | Write-back | Write-evict |
| 写缺失 | Write no-allocate | Write no-allocate |
对于本地存储器,L1数据高速缓存充当具有写入无分配的回写高速缓存。 对于全局内存,写入命中会导致块的逐出。 这模仿了PTX ISA规范中概述的全局存储的默认策略。(http://developer.nvidia.com/nvidiagpu-computing-documentation)
在L1数据高速缓存中命中的存储器访问在一个SIMT核心时钟周期中被服务。 错过的访问被插入FIFO未命中队列。 每个SIMT时钟周期的一个填充请求由L1数据高速缓存生成(假设互连注入缓冲器能够接受请求)。
高速缓存使用未命中状态保持寄存器(MSHR)来保持正在进行的未命中状态。 它们被建模为完全关联的数组。 在一个请求在飞行中时发生的对存储器系统的冗余访问在MSHR中合并。 MSHR表具有固定数量的MSHR条目。 每个MSHR条目可以为单个高速缓存行服务固定数量的未命中请求。 每个条目的MSHR条目数和最大请求数是可配置的。
缓存中未命中的内存请求将添加到MSHR表中,如果没有该缓存行的挂起请求,则会生成填充请求。 当在高速缓存处接收到对填充请求的填充响应时,将高速缓存行插入到高速缓存中,并将相应的MSHR条目标记为已填充。 每个周期一个请求生成对填充的MSHR条目的响应。 一旦在填充的MSHR条目处等待的所有请求都被响应并被服务,则释放MSHR条目。
Texture缓存
纹理缓存模型是预取纹理缓存
(http://wwwgraphics.stanford.edu/papers/texture_prefetch/)
纹理存储器访问主要表现出空间局部性,并且已经发现该局部性大部分被大约16KB的存储器捕获
(http://graphics.stanford.edu/papers/texture_cache/)
在逼真的图形使用场景中,许多纹理缓存访问都会丢失访问DRAM中纹理的延迟大约为100个周期。鉴于大内存访问延迟和较小的缓存大小,何时在缓存中分配行的问题变得至关重要。预取纹理高速缓存通过在时间上将高速缓存标签的状态与高速缓存块的状态解耦来解决该问题。标签数组表示当未命中的100个循环被服务时缓存将处于的状态。数据数组表示未命中服务后的状态。使这种去耦工作的关键是使用重新排序缓冲区以确保返回纹理未命中数据按照标记数组看到访问的相同顺序放入数据数组中。有关详细信息,请参阅原始论文(http://wwwgraphics.stanford.edu/papers/texture_prefetch/)
常量缓存(只读)
对常量和参数内存的访问通过L1常量高速缓存运行。 此缓存使用标记数组实现,类似于L1数据缓存,但无法写入。
线程块/ CTA /工作组调度
CUDA术语中的线程块,协作线程阵列(CTA)或OpenCL术语中的工作组一次一个地发布给SIMT核心。 每个SIMT核心时钟周期,线程块发布机制以循环方式选择并循环通过SIMT核心集群。 对于每个选定的SIMT核心群集,选择SIMT核心并以循环方式循环。 对于每个选定的SIMT Core,如果SIMT Core上有足够的资源,则将从所选内核向核心发出单个线程块。
如果在应用程序中使用多个CUDA Streams或命令队列,则可以在GPGPU-Sim中同时执行多个内核。 可以跨不同的SIMT核执行不同的内核; 单个SIMT Core一次只能从一个内核执行线程块。 如果同时执行多个内核,则选择要发布到每个SIMT Core的内核也是循环的。 “NVIDIA CUDA编程指南”中介绍了CUDA体系结构上的并发内核执行。
(http://developer.nvidia.com/nvidia-gpu-computing-documentation)
GPGPU-Sim的软件设计
要使用GPGPU-Sim 3.x执行大量架构研究,需要修改源代码。 本节介绍了GPGPU-Sim 3.x的高级软件设计,它与2.x版不同。 除了此处的软件说明,您可能会发现查阅GPGPU-Sim 3.x的doxygen生成文档很有帮助。 有关从GPGPU-Sim 3.x源构建doxygen文档的说明,请参阅自述文件。
下面总结了源组织,命令行选项解析器,面向对象的抽象硬件模型,它提供了性能模拟引擎的软件组织和功能模拟引擎的软件组织之间的接口。 最后,我们描述了使用CUDA / OpenCL应用程序的接口的软件设计。
文件列表和简要说明
GPGPU-SIM主要包含三个主要模块(每一个在它的单独的文件夹中):
- cuda-sim执行由NVCC或OpenCL编译器生成的PTX内核的功能模拟器
- gpgpu-sim模拟GPU(或其他许多核心加速器架构)的时序行为的性能模拟器
- IntersimBill Dally的BookSim采用的互连网络模拟器
以下是每个模块中的文件:
1.总体、公共文件
Makefile
构建gpgpu-sim并在cuda-sim和intersim中调用其他Makefile
abstract_hardware_model.h
abstract_hardware_model.cc
提供一组在功能和时序模拟器之间进行接口的类
debug.h
debug.cc
实现交互式调试器模块gpgpusim_enterpoint.c包含与CUDA / OpenCL API存根库接口的函数
option_parser.h
option_parser.cc
实现命令行选项解析器
stream_manager.h
stream_manager.cc
实现流管理器以支持CUDA流tr1_hash_map.hC ++ 11中std :: unordered_map的包装代码。如果编译不支持C ++ 11,则回退到std :: map或GNU hash_map.gdb_init包含通过GDB简化模拟状态的低级可视化的宏
2.cuda-sim
Makefile
cuda-sim的编译文件。由上一级Makefile调用
cuda_device_print.h
cuda_device_print.cc
在CUDA设备函数中支持printf()的实现(即在GPU内核函数中调用printf())。 请注意,设备printf仅适用于CUDA 3.1
cuda-math.h
包含CUDA Math头文件的接口
cuda-sim.h
cuda-sim.cc
实现gpgpu-sim和cuda-sim之间的接口。 它还包含一个用于功能仿真的独立模拟器
instructions.h
instructions.cc
这是实现所有PTX指令的仿真代码的地方
memory.h
memory.cc
功能存储空间仿真
opcodes.def
DEF文件,用于链接每条指令的各种信息(例如字符串名称,实现,内部操作码…)
opcodes.h
定义每个PTX指令ptxinfo.l ptxinfo.y用于解析ptxinfo文件的Lex和Yacc文件。(获取内核资源要求)
ptx_ir.h
ptx_ir.cc
CUDA中的静态结构 - 内核,函数,符号…等。还包含执行静态分析的代码,用于在加载时从内核中提取immediatepost-dominators
ptx.l
ptx.y
用于解析.ptx文件和嵌入式cubin结构的Lex和Yacc文件,以获取CUDA内核的PTX代码
ptx_loader.h
ptx_loader.cc
包含用于加载和解析以及打印PTX和PTX信息文件的功能
ptx_parser.h
ptx_parser.cc
包含Yacc在解析期间调用的函数,这些函数创建功能和性能模拟所需的基础结构
ptx_parser_decode.def
包含PTX提取中使用的解析器的标记定义
ptx_sim.h
ptx_sim.cc
CUDA中的动态结构 - 网格,CTA,线程
ptx-stats.h
ptx-stats.cc
PTX源线分析器
2.gpgpu-sim
Makefile
gpgpu-sim的编译文件。由上一级Makefile调用
addrdec.h
addrdec.cc
地址解码器 - 将给定地址映射到DRAM通道中的特定行,存储区,列
delayqueue.h
灵活流水线队列的实现
dram_sched.h
dram_sched.cc
FR-FCFS DRAM请求调度程序
dram.h
dram.cc
DRAM时序模型+ gpgpu-sim其他部分的接口
gpu-cache.h
gpu-cache.cc
GPGPU-Sim的缓存模型
gpu-misc.h
gpu-misc.cc
包含misc。 gpgpu-sim部分所需的功能
gpu-sim.h
gpu-sim.cc
将GPGPU-Sim中的不同时序模型粘合为一个。 它包含支持多个时钟域并实现线程块调度程序的实现
histogram.h
histogram.cc
定义了几个实现不同类型直方图的类
icnt_wrapper.h
icnt_wrapper.c
gpgpu-sim的互连网络接口。 它提供了一个完全解耦的接口,允许intersim作为gpgpu-sim的互连网络定时模拟器
l2cache.h
l2cache.cc
实现内存分区的时序模型。它还实现L2高速缓存并将其与存储器分区的其余部分(例如DRAM定时模型)接口
mem_fetch.h
mem_fetch.cc
定义mem_fetch,一种为内存请求建模的通信结构
mem_fetch_status.tup
定义内存请求的状态
mem_latency_stat.h
mem_latency_stat.cc
包含用于内存系统统计信息收集的各种代码
scoreboard.h
scoreboard.cc
实现SIMT核心中使用的记分板
shader.h
shader.cc
SIMT核心时序模型。它调用cudu-sim进行特定线程的功能模拟,而cuda-sim将返回线程的性能敏感信息
stack.h
stack.cc
立即后支配者线程调度程序使用的简单堆栈。(废弃)
stats.h
定义对内存管道中的内存访问和各种停顿条件进行分类的enumstat-tool.h
stat-tool.cc
实现各种性能测量工具
visualizer.h
visualizer.cc
输出可视化工具的动态统计信息
3.intersim
Makefile
修改为创建库而不是独立的网络模拟器
booksim_config.cpp
intersim的配置选项在此处定义并给出默认值
flit.hpp
修改后添加了向数据传输数据的功能。 Flits也知道他们属于哪个网络
interconnect_interface.cpp
interconnect_interface.h
这里实现了GPGPU-Sim和intersim之间的接口
iq_router.cpp
iq_router.hpp
修改后添加对output_extra_latency的支持(用于创建ISPASS 2009)
islip.cpp
一些小修改来修复数组绑定错误
stats.cpp
stats.hpp
统计信息收集功能在此文件中。我们做了一些小调整。 例如。添加了一个名为NeverUsed的新函数,用于指示是否更新了特定的统计信息
statwraper.cpp
statwraper.h
一个包装器,它允许使用C文件中stats.cpp中Stat类中实现的stat收集功能
trafficmanager.cpp
trafficmanager.hpp
从原始booksim重新修改。 这里完成了许多高级操作
以下是详细介绍:
Option Parser
当研究修改GPGPU-Sim时,可能会添加要在不同模拟中进行不同配置的功能。GPGPU-Sim 3.x提供了一个通用命令行选项解析器,允许不同的软件模块通过简单的接口注册其选项。选项解析器在gpgpusim_entrypoint.cc中的gpgpu_ptx_sim_init_perf()中实例化。使用以下函数在gpgpu_sim_config :: reg_options()中添加选项:
void option_parser_register(option_parser_t opp,
const char *name,
enum option_dtype type,
void *variable,
const char *desc,
const char *defaultvalue);
以下是每个参数的说明:
- option_parser_t opp - 选项解析器标识符。
- const char * name - 标识命令行选项的字符串。
- enum option_dtype type - 选项的数据类型。 它可以是以下之一:
- int
- unsigned int
- long long
- unsigned long long
- bool(as int in C)
- float
- double
- c string
- void * variable - 指向变量的指针。
- const char * desc - 显示的选项的描述
- const char * defaultvalue - 选项的默认值(字符串值将自动解析)。 您可以为此c字符串变量将此值设置为NULL。
查看gpgpu-sim / gpu-sim.cc中的示例。
选项解析器使用option_parser.cc中的OptionParser类实现(在C接口中公开为option_parser.h中的option_parser_t)。以下是GPGPU-Sim其余部分使用的完整C接口:
- option_parser_register() 在选项名称(字符串)和模拟器中的变量之间创建绑定。 变量通过引用(指针)传递,并在调用option_parser_cmdline()或option_parser_cfgfile()时进行修改。 请注意,每个选项只能绑定到单个变量。
- option_parser_cmdline() 解析给定的命令行选项。 为选项-config 调用option_parser_cmdline()。
- **option_parser_cfgfile()**解析包含配置选项的给定文件。
- **option_parser_print()**转储所有已注册的选项及其解析的值。
在gpgpusim_entrypoint.cc中的gpgpu_ptx_sim_init_perf()内,GPGPU-Sim中只实例化了一个OptionParser对象。 此OptionParser对象将gpgpusim.config中的模拟选项转换为可在模拟器中访问的变量值。 GPGPU-Sim中的不同模块将其选项注册到OptionParser对象中(即指定哪个选项对应于模拟器中的哪个变量)。 之后,模拟器调用option_parser_cmdline()来解析gpgpusim.config中包含的模拟选项。
在内部,OptionParser类包含一组OptionRegistry。 OptionRegistry是一个使用>>运算符进行解析的模板类。 OptionRegistry的每个实例负责解析特定类型变量的一个选项。 目前,解析器仅支持以下数据类型,但可以通过重载>>运算符来扩展对更复杂数据类型的支持:
- 32-bit/64-bit integers
- floating points (float and doubles)
- booleans
- c-style strings (char*)
硬件抽象模型(Abstract Hardware Model)
文件abstract_hardware_model {.h,.cc}提供了一组在功能和时序模拟器之间进行接口的类
硬件抽象模型对象(Hardware Abstraction Model Objects)
| Enum名称 | 相关描述 |
|---|---|
| _memory_space_t | |
| uarch_op_t | |
| _memory_op_t | |
| cudaTextureAddressMode | |
| cudaTextureFilterMode | |
| cudaTextureReadMode | |
| cudaChannelFormatKind | |
| mem_access_type | |
| cache_operator_type | |
| divergence_support_t |
| Class名称 | 相关描述 |
|---|---|
| class kernel_info_t | |
| class core_t | |
| struct cudaChannelFormatDesc | |
| struct cudaArray | |
| struct textureReference | |
| class gpgpu_functional_sim_config | |
| class gpgpu_t | |
| struct gpgpu_ptx_sim_kernel_info | |
| struct gpgpu_ptx_sim_arg | |
| class memory_space_t | |
| class mem_access_t | |
| struct dram_callback_t | |
| class inst_t | |
| class warp_inst_t |
GPGPU-SIM性能模拟引擎
在GPGPU-Sim 3.x中,性能模拟引擎是通过在
本节介绍性能模拟引擎中的各种类。 这些包括一组模拟前面描述的微体系结构的软件对象,本节还描述了性能模拟引擎如何与功能模拟引擎接口,如何与AerialVision接口,以及我们在性能模拟引擎中使用的各种非平凡软件设计。
性能模型软件对象
GPGPU-Sim 3.x与2.x之间的一个更重要的变化是为性能模拟引擎引入了面向对象的C ++(主要是)面向对象的设计。 本小节描述了用于实现性能模拟引擎的各种类的高级设计。 这些与前面描述的硬件块密切对应。
SIMT核心簇类
SIMT核心集群由simt_core_cluster类建模。 该类包含m_core中的SIMT核心对象数组。 simt_core_cluster :: core_cycle()方法只是按顺序循环每个SIMT内核。 simt_core_cluster :: icnt_cycle()方法将内存请求从互连网络推入SIMT核心集群的响应FIFO。 它还会弹出FIFO的请求,并将它们发送到相应的内核指令缓存或LDST单元。 simt_core_cluster :: icnt_inject_request_packet(…)方法为SIMT核心提供了一个接口,用于将数据包注入网络。
SIMT核心类
图3中显示的SIMT核心微体系结构是使用shader.h / cc中的类shader_core_ctx实现的。 派生自类core_t(核心的抽象功能类),该类结合了实现SIMT核心微体系结构模型的各个部分的所有不同对象:
- 一组shd_warp_t对象,用于模拟核心中每个warp的模拟状态
- 一个SIMT堆栈,simt_stack对象,用于处理分支发散的每个warp
- 一组scheduler_unit对象,每个对象负责从其warp集合中选择一个或多个指令并发出这些指令以供执行,用于检测数据危险的记分板对象。
- 一个opndcoll_rfu_t对象,它为操作数收集器建模
- 一组simd_function_unit对象,用于实现SP单元和SFU单元(ALU管道)
- 一个ldst_unit对象,用于实现内存管道
- 一个shader_memory_interface,它将SIMT核心连接到相应的SIMT核心集群,每个内存请求都通过此接口由一个内存分区提供服务
调用每个核心循环shader_core_ctx :: cycle()以模拟SIMT核心的一个循环。 此函数调用一组成员函数,这些函数以相反的顺序模拟核心的流水线阶段,以模拟流水线效果:
- fetch()
- decode()
- issue()
- read_operand()
- execute()
- writeback()
各个流水线级通过一组流水线寄存器连接,这些寄存器是指向warp_inst_t对象的指针(Fetch和Decode除外,它通过ifetch_buffer_t对象连接)。
在访问特定于SIMT核心的配置选项时,每个shader_core_ctx对象引用一个公共shader_core_config对象。 所有shader_core_ctx对象还链接到shader_core_stats对象的公共实例,该对象跟踪所有SIMT核心的一组性能测量。
Fetch 和 Decode 软件模型
本节介绍了Fetch和Decode的软件模型。
图1中显示的I-Buffer在shader_core_ctx中实现为shd_warp_t对象的数组。 每个shd_warp_t都有一组I-Buffer条目的m_ibuffer(ibuffer_entry),它们包含可配置数量的指令(在一个周期内获取的最大允许指令)。 此外,shd_warp_t还有一些标志,调度程序使用这些标志来确定warp for issue的合格性。 解码的指令存储在ibuffer_entry中,作为指向warp_inst_t对象的指针。 warp_inst_t保存有关此指令的操作类型和使用的操作数的信息。
此外,在提取阶段,shader_core_ctx :: m_inst_fetch_buffer变量充当Fetch(指令高速缓存访问)和Decode阶段之间的流水线寄存器。
如果解码阶段没有停止(即shader_core_ctx :: m_inst_fetch_buffer没有有效指令),则获取单元工作。 外部for循环实现循环调度程序,最后一个调度的warp id存储在m_last_warp_fetched中。 第一个if语句检查warp是否已完成执行,而在第二个if语句内,在命中或生成内存访问的情况下,从指令高速缓存中实际获取,以防丢失。 第二个if语句主要检查是否没有有效指令存储在与当前检查的warp对应的条目中。
解码阶段只是检查shader_core_ctx :: m_inst_fetch_buffer并开始在指令缓冲区条目(m_ibuffer,shd_warp_t :: ibuffer_entry的对象)中存储解码的指令(当前配置解码每个周期最多两条指令),该条目对应于warp in shader_core_ctx :: m_inst_fetch_buffer。
Schedule 和 Issue 软件模型
在每个核心内,有一个可配置数量的调度器单元。函数shader_core_ctx :: issue()遍历这些单元,其中每个单元执行scheduler_unit :: cycle(),其中在warp上应用循环算法。在scheduler_unit :: cycle()中,使用函数shader_core_ctx :: issue_warp()将指令发送到其合适的执行管道。在此函数中,通过调用shader_core_ctx :: func_exec_inst()函数执行指令,并通过调用simt_stack :: update()更新SIMT堆栈(m_simt_stack [warp_id])。此外,在此函数中,由于shd_warp_t:set_membar()和barrier_set_t :: warp_reaches_barrier的障碍,warp被保持/释放。另一方面,记分板由Scoreboard :: reserveRegisters()保留,稍后由记分板算法使用。 scheduler_unit :: m_sp_out,scheduler_unit :: m_sfu_out,scheduler_unit :: m_mem_out可以接收地指向SP,SFU和Mem pipline的发布阶段和执行阶段之间的第一个流水线寄存器。这就是为什么在使用shader_core_ctx :: issue_warp()向相应的管道发出任何指令之前检查它们的原因。
SIMT 栈软件模型
对于每个调度器单元,存在一组SIMT堆栈。 每个SIMT堆栈对应一个warp。 在scheduler_unit :: cycle()中,调度warp的SIMT堆栈的堆栈条目的顶部确定发出的指令。 堆栈条目顶部的程序计数器通常与IBuffer中与调度的warp相对应的下一条指令的程序计数器一致(参见SIMT堆栈)。 否则,在控制危险的情况下,它们将不匹配,并且I-Buffer中的指令被刷新。
SIMT堆栈的实现位于shader.h中的simt_stack类中。 使用此函数simt_stack :: update(…)在每次问题后更新SIMT堆栈。 此函数实现发散和重新收敛点所需的算法。 在更新SIMT堆栈之前,在发布阶段执行功能执行(参考指令执行)。 这允许发布阶段具有每个线程的下一个pc的信息,因此,根据需要更新SIMT堆栈。
Scoreboard 软件模型
记分板单元在shader_core_ctx中实例化为成员对象,并通过引用(指针)传递给scheduler_unit。 它通过warp id存储着色器核心id和寄存器表索引。 该寄存器表存储每个warp保留的寄存器数。 功能Scoreboard :: reserveRegisters(…),Scoreboard :: releaseRegisters(…)和Scoreboard :: checkCollision(…)用于保留寄存器,释放寄存器和分别在发出warp之前检查冲突。
操作数收集器软件模型
操作数收集器被建模为由函数shader_core_ctx :: cycle()执行的主管道中的一个阶段。 此阶段由shader_core_ctx :: read_operands()函数表示。 有关操作数收集器接口的更多详细信息,请参阅ALU Pipeline。
类opndcoll_rfu_t模拟基于操作数收集器的寄存器文件单元。 它包含抽象收集器单元集,仲裁器和调度单元的类。
opndcoll_rfu_t :: allocate_cu(…)负责将warp_inst_t分配给其分配的操作数收集器集合中的空闲操作数收集器单元。 此外,它还在仲裁器中的相应银行队列中添加了对所有源操作数的读取请求。
但是,opndcoll_rfu_t :: allocate_reads(…)处理没有冲突的读取请求,换句话说,从仲裁器队列中弹出不同寄存器库中的读取请求并且不会转到相同的操作数收集器。 这解释了写请求优先于读请求。
函数opndcoll_rfu_t :: dispatch_ready_cu()将就绪操作数收集器的操作数寄存器(收集了所有操作数)调度到执行阶段。
函数opndcoll_rfu_t :: writeback(const warp_inst_t&inst)在内存管道的写回阶段被调用。 它负责写入的分配。
这总结了用于对操作数收集器进行建模的主要函数的要点,但是,更多细节在shader.cc和shader.h中的opndcoll_rfu_t类的实现中。
ALU流水线软件模型
SP单元和SFU单元的时序模型主要在shader.h中定义的pipelined_simd_unit类中实现。 建模单元的特定类(sp_unit和sfu类)是从此类派生的,具有重写的can_issue()成员函数,用于指定单元可执行的指令类型。
SP单元通过OC_EX_SP流水线寄存器连接到操作收集器单元; SFU单元通过OC_EX_SFU流水线寄存器连接到操作数收集器单元。 两个单元通过WB_EX流水线寄存器共享一个公共写回阶段。 为防止两个单元因写回阶段冲突而停止,进入任一单元的每条指令必须在结果总线(m_result_bus)中分配一个插槽,然后才能将其发送到目标单元(请参阅shader_core_ctx :: execute())。
下图概述了pipelined_simd_unit如何为不同类型的指令建模吞吐量和延迟。

在每个pipelined_simd_unit中,问题(warp_inst_t *&)成员函数将给定管道寄存器的内容移动到m_dispatch_reg中。 然后该指令在m_dispatch_reg等待initiate_interval周期。 同时,不能向该单元发出其他指令,因此该等待模拟指令的吞吐量。 在等待之后,将指令分派到内部流水线寄存器m_pipeline_reg以进行延迟建模。 确定调度位置,以便在m_dispatch_reg中花费的时间也计入延迟。 每个周期,指令将通过流水线寄存器前进,最终进入m_result_port,m_result_port是共享流水线寄存器,通向SP和SFU单元的公共写回阶段。
每种类型指令的吞吐量和延迟在cuda-sim.cc中的ptx_instruction :: set_opcode_and_latency()中指定。 在预解码期间调用此函数。
内存阶段软件模型
shader.cc中的ldst_unit类实现了着色器管道的内存阶段。 该类在所有着色器内存中实例化和操作:纹理(m_L1T),常量(m_L1C)和数据(m_L1D)。 ldst_unit :: cycle()实现了单元操作的内容,并且在核心周期之前被抽取m_config-> mem_warp_parts次。 这样可以在一个着色器循环中处理完全合并的内存访问。 ldst_unit :: cycle()处理来自互连的内存响应(存储在m_response_fifo中),填充缓存并将存储标记为完成。 该功能还可以循环缓存,以便它们可以将对丢失数据的请求发送到互连。
对每种类型的L1内存的高速缓存访问分别在shared_cycle(),constant_cycle(),texture_cycle()和memory_cycle()中完成。 memory_cycle用于访问L1数据缓存。 然后,这些函数中的每一个都调用process_memory_access_queue(),这是一个通用函数,它从指令内部访问队列中提取访问权并将此请求发送到缓存。 如果在这个循环中无法处理此访问(即,当各种系统队列已满或当特定方式的所有行都已被保留且尚未填充时,它既不会丢失也不会在缓存中命中)则访问权限是 再次尝试下一个周期。
值得注意的是,并非所有指令都到达设备的回写阶段。 所有存储指令和加载指令,其中所有请求的高速缓存块在循环功能中命中退出管道。 这是因为它们不必等待来自互连的响应,并且可以绕过书写的写回逻辑 - 保留指令所请求的高速缓存行和已经返回的高速缓存行。
缓存软件模型
gpu-cache.h实现了ldst_unit使用的所有缓存。 常量高速缓存和数据高速缓存都包含一个成员tag_array对象,该对象实现了保留和替换逻辑。 probe()函数检查块地址而不影响有问题数据的LRU位置,而access()用于建模影响LRU位置的查找,并且是生成未命中和访问统计信息的函数。 MSHR使用mshr_table类建模,模拟具有有限数量的合并请求的完全关联表。 通过next_access()函数从MSHR释放请求。
read_only_cache类用于常量缓存,并用作data_cache类的基类。 这种层次结构可能有点令人困惑,因为R / W数据缓存从read_only_cache扩展。 唯一的原因是它们共享大部分相同的功能,但处理函数除外,它必须处理data_cache中的写入。 L2缓存也使用data_cache类实现。
tex_cache类实现上面的体系结构描述中概述的纹理缓存。 它不使用tag_array或mshr_table,因为它的操作与传统缓存的操作明显不同。
线程块/ CTA /工作组调度
线程块到SIMT核心的调度发生在shader_core_ctx :: issue_block2core(…)中。 可以在核心上同时调度的线程块(或CTA或工作组)的最大数量由函数shader_core_config :: max_cta(…)计算。 此函数根据程序指定的每个线程块的线程数,每线程寄存器的使用情况,共享内存使用情况和配置的限制,确定可以同时分配给单个SIMT内核的最大线程块数。 每个核心的最大线程块数。 具体地,如果上述每个标准是限制因素,则计算可以分配给SIMT核心的线程块的数量。 其中最小值是可以分配给SIMT内核的最大线程块数。
在shader_core_ctx :: issue_block2core(…)中,首先将线程块大小填充为warp大小的精确倍数。 然后确定一系列免费硬件线程ID。 通过调用ptx_sim_init_thread初始化每个线程的功能状态。 通过调用shader_core_ctx :: init_warps初始化SIMT堆栈和warp状态。
当每个线程完成时,SIMT内核调用register_cta_thread_exit(…)来更新活动线程块的状态。 当线程块中的所有线程都已完成时,相同的函数会减少核心上活动的线程块的数量,从而允许在下一个周期中调度更多的线程块。 从挂起的内核中选择要调度的新线程块。