MySQL-索引
INSERT INTO index_demo VALUES(4, 4, ‘a’);

由于下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值的要求,所以在插入主键值为 4 的记录的时候需要伴随着一次记录移动,也就是把主键值为 5 的记录移动到 页28 中,然后再把主键值为 4 的记录插入到 页10 中,这个过程的示意图如下:
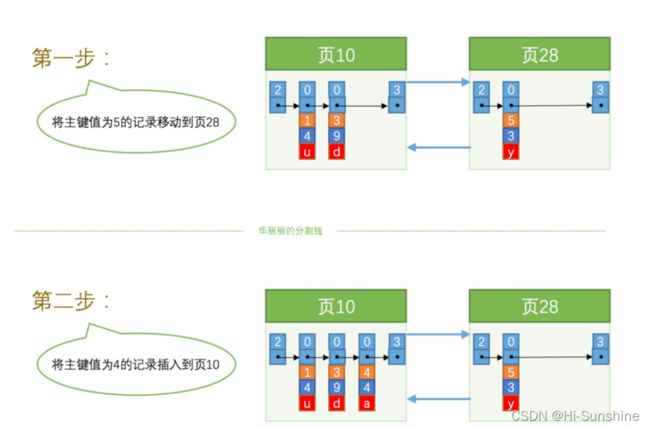
这个过程表明了在对页中的记录进行增删改操作的过程中,我们必须通过一些诸如记录移动的操作来始终保证这个状态一直成立:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。这个过程我们也可以称为 页分裂 。
[](()引入索引概念
=================================================================
由于数据页的编号可能并不是连续的,所以在向 index_demo 表中插入许多条记录后,可能是这样的效果:

接下来我们为每一个页创建一个目录项,每个目录项包含的内容如下:
-
页的用户记录中最小的主键值,用key表示
-
页号,用page_no表示

以 页28 为例,它对应 目录项2 ,这个目录项中包含着该页的页号 28 以及该页中用户记录的最小主键值 5 。我们只需要把几个目录项在物理存储器上连续存储,比如把他们放到一个数组里,就可以实现根据主键值快速查找某条记录的功能了。比方说我们想找主键值为 20 的记录,具体查找过程分两步:
-
先从目录项中根据二分法快速确定出主键值为 20 的记录在 目录项3 中(因为 12 < 20 < 209 ),它对应的页是 页9 。
-
再根据前边说的在页中查找记录的方式去 页9 中定位具体的记录。
到这里我们应该就知道了吧,这个 目录 有一个别名,称为 索引 。恍然大悟吧~,哈哈哈。
[](()引入B+树
================================================================
目录项记录和普通的用户记录的不同点由下图我们得知:
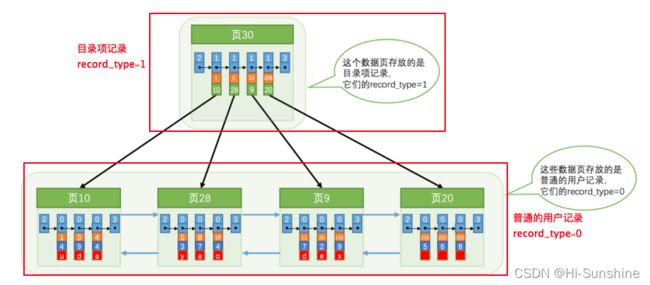
通过上图我们可以总结如下:
-
目录项的record_type的值是1,而普通用户记录的record_type的值是0
-
record_type属性: 0,普通的用户记录;1:目录项记录;2:最小记录;3:最大记录
-
目录项只有主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列, 另外还有 InnoDB 自己添加的隐藏列。
-
只有在存储 目录项记录 的页中的主键值最小的目录项记录 的 min_rec_mask 值为 1 ,其他别的记录的 min_rec_mask 值都是 0 。
现在以查找主键为 20 的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下边两步:
-
先到存储 目录项记录 的页,也就是页 30 中通过二分法快速定位到对应目录项,因为 12 < 20 < 209 ,所 以定位到对应的记录所在的页就是 页9 。
-
再到存储用户记录的 页9 中根据二分法快速定位到主键值为 20 的用户记录。
通过上文我们知道 目录项记录 中只存储主键值和对应的页号,比用户记录需要的存储空间小多了,但是不论怎么说一个页只有 16KB 大小,能存放的 目录项记录 也是有限的,那如果表中的数据太多,以至于一个数据页不足以存放所有的 目录项记录 ,该咋办呢?
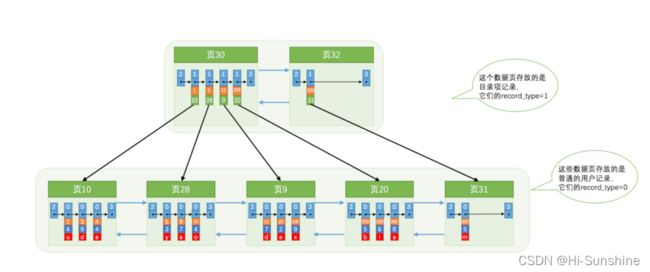
这个时候我们就需要再分配一个数据页了,如下:
-
为存储该用户记录而新生成了 页31 。
-
因为原先存储 目录项记录 的 页30 的容量已满(我们前边假设只能存储4条 目录项记录 ),所以不得不需要一个新的 页32 来存放 页31 对应的目录项。
现在因为存储 目录项记录 的页不止一个,所以如果我们想根据主键值查找一条用户记录大致需要3个步骤,以查找主键值为 20 的记录为例:
-
确定 目录项记录 页
-
通过 目录项记录 页确定用户记录真实所在的页。
-
在真实存储用户记录的页中定位到具体的记录。
如果我们表中的数据非常多则会产生很多存储 目录项记录 的页,那我们怎么根据主键值快速定位一个存储 目录项记录 的页呢?其实也简单,为这些存储 目录项记录 的页再生成一个更高级的目录,就像是一个多级目录一样,大目录里嵌套小目录,小目录里才是实际的数据,所以现在各个页的示意图就是这样子:
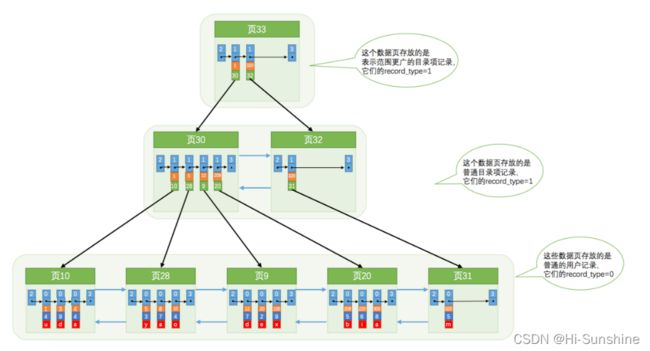
如图,我们生成了一个存储更高级目录项的 页33 ,这个页中的两条记录分别代表 页30 和 页32 ,如果用户记录的主键值在 [1, 320) 之间,则到 页30 中查找更详细的 目录项记录 ,如果主键值不小于 320 的话,就到 页32中查找更详细的 目录项记录 。
随着表中记录的增加,这个目录的层级会继续增加,如果简化一下,那么我们可以用下边这个图来描述它:
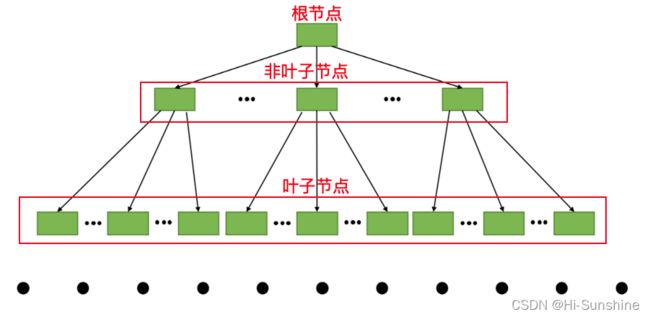
不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把它们存放到 B+ 树这个数据结构中了,所以我们也称这些数据页为 节点 。从图中可以看出来,我们的实际用户记录其实都存放在B+树的最底层的节点上,这些节点也被称为 叶子节点 或 叶节点 ,其余用来存放 目录项 的节点称为 非叶子节点 或者 内节点 ,其中 B+ 树最上边的那个节点也称为 根节点 。
[](()B+树的概念
B+树是应数据库所需而出现的一种 B 树的变形树。
[](()B+树的特点
-
使用记录主键值的大小进行记录和页的排序
-
页内的记录是按照主键的大小顺序排成一个单向链表
-
各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表
-
存放目录项的记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表
-
B+树的叶子节点存储的是完整的用户记录(指这个记录中存储了所有列的值(包括隐藏列))
[](()B+树的形成过程
- 每当为某个表创建一个 B+ 树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个根节点页面。最开始表中没有数据的时候,每个 B+ 树索引对应的 根节点 中既没有用户记录,也没有目录项记录。