搭建Lambda架构日志分析流水线
搭建日志分析流水线
1 准备工作
(1)启动HDFS
a)启动所有的Zookeeper,在3个节点分别使用以下命令:
zkServer.sh start
b)启动HDFS,在master节点使用以下命令:
start-dfs.sh
c)启动Yarn,在master节点使用以下命令:
start-yarn.sh
d)检查进程是否全部启动,在3个节点分别使用以下命令:
jps
(2)启动和配置Kafka
a)启动kafka,在3个节点分别使用以下命令:
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties &
b)检查kafka是否启动成功,在3个节点分别使用以下命令:
jps
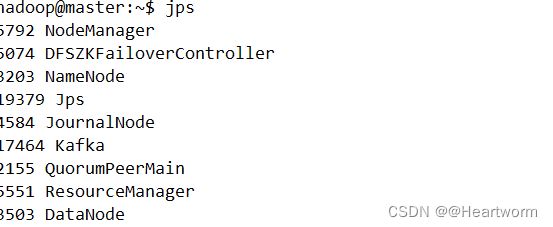 c)创建lambda主题,在master执行以下命令:
c)创建lambda主题,在master执行以下命令:
kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --replication-factor 3 --partitions 3 --topic lambda
 d)查看主题是否创建成功,使用以下命令:
d)查看主题是否创建成功,使用以下命令:
kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181
e)启动控制台消费者,查看lambda主题接收到的数据,在master使用以下命令:
kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --topic lambda
 (3)生成网站访问日志:
(3)生成网站访问日志:
a)启动Nginx,在master使用以下命令:
sudo systemctl start nginx
b)访问网页,使用以下网址:
http://master/shop.html
![]()
c)检查是否生成日志,在master使用以下命令:
sudo tail -F /var/log/nginx/access.log

(4)创建lambda目录存储项目文件,在master使用以下命令:
mkdir /home/hadoop/lambda
 (5)配置Spark依赖的第三方jar文件
(5)配置Spark依赖的第三方jar文件
a)上传mysql-connector-java-5.1.47.jar、spark-streaming-kafka-0-8_2.11-2.4.6.jar和spark-streaming-kafka-0-8-assembly_2.11-2.4.6.jar文件到/usr/local/spark/jars
如图:
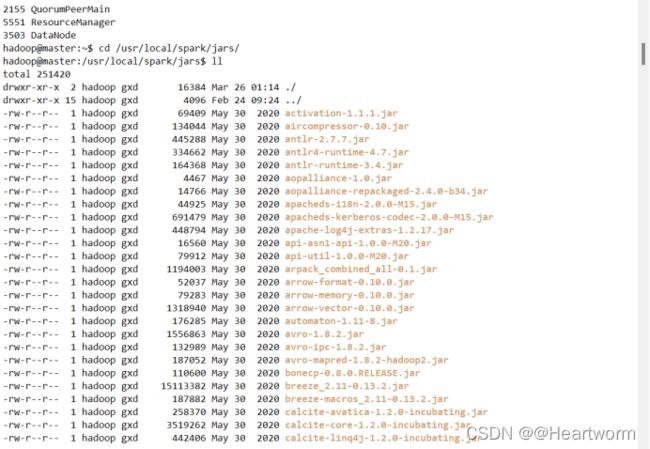
(6)在MySQL创建lambda用户和lambda数据库,步骤如下:
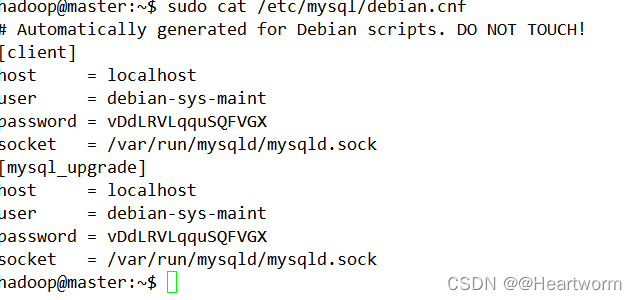
a)查看MySQL管理员账号和密码,使用以下命令:
sudo cat /etc/mysql/debian.cnf
b)使用管理员账号和密码登录MySQL
 c)创建lambda用户,使用以下命令:
c)创建lambda用户,使用以下命令:
CREATE USER 'lambda'@'%' IDENTIFIED BY '123456';
 d)给lambda用户授权,使用以下命令:
d)给lambda用户授权,使用以下命令:
GRANT ALL PRIVILEGES ON lambda.* TO 'lambda'@'%';
FLUSH PRIVILEGES;
 e)创建lambda数据库,使用以下命令:
e)创建lambda数据库,使用以下命令:
CREATE DATABASE lambda;

f)退出MySQL,使用以下命令:
exit

2 使用Flume采集数据
本案例的Flume需要配置两个输出端:一个是输出到HDFS,用于离线分析;另一个是输出到Kafka,用于实时分析。
(1)创建nginx-memory-kafka-hdfs.properties文件,在master使用以下命令:
touch /home/hadoop/lambda/nginx-memory-kafka-hdfs.properties
![]()
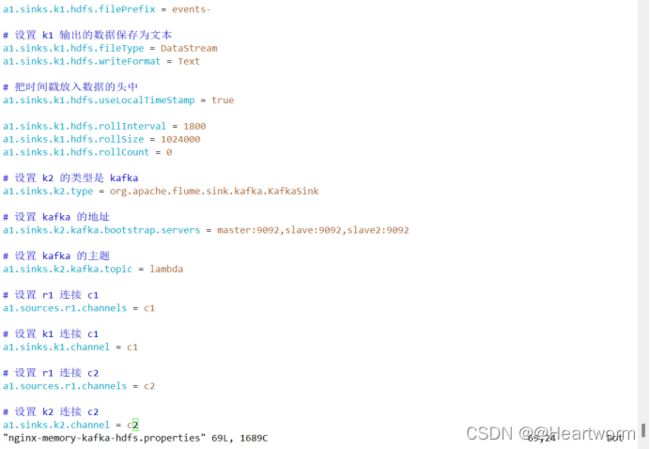
(2)编辑该文件,填写以下内容:
# agent 起个名字叫做 a1
# 设置 a1 的 sources 叫做 r1
a1.sources = r1
# 设置 a1 的 sinks 叫做 k1
a1.sinks = k1 k2
# 设置 a1 的 channels 叫做 c1
a1.channels = c1 c2
# 设置 r1 的类型是 exec,用于采集命令产生的数据
a1.sources.r1.type = exec
# 设置 r1 采集 tail -F 命令产生的数据
a1.sources.r1.command = sudo tail -F /var/log/nginx/access.log
# 设置 c1 的类型是 memory
a1.channels.c1.type = memory
# 设置 c1 的缓冲区容量
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 500
# 设置 c2 的类型是 memory
a1.channels.c2.type = memory
# 设置 c2 的缓冲区容量
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 500
# 设置 k1 的类型是 hdfs
a1.sinks.k1.type = hdfs
# 设置 k1 输出路径,按照时间在 hdfs 上创建相应的目录
a1.sinks.k1.hdfs.path = /lambda/log/%Y-%m-%d/%H
a1.sinks.k1.hdfs.filePrefix = events-
# 设置 k1 输出的数据保存为文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
# 把时间戳放入数据的头中
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.rollInterval = 1800
a1.sinks.k1.hdfs.rollSize = 102400
a1.sinks.k1.hdfs.rollCount = 0
# 设置 k2 的类型是 kafka
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
# 设置 kafka 的地址
a1.sinks.k2.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
# 设置 kafka 的主题
a1.sinks.k2.kafka.topic = lambda
# 设置 r1 连接 c1
a1.sources.r1.channels = c1 c2
# 设置 k1 连接 c1
a1.sinks.k1.channel = c1
# 设置 k2 连接 c2
a1.sinks.k2.channel = c2
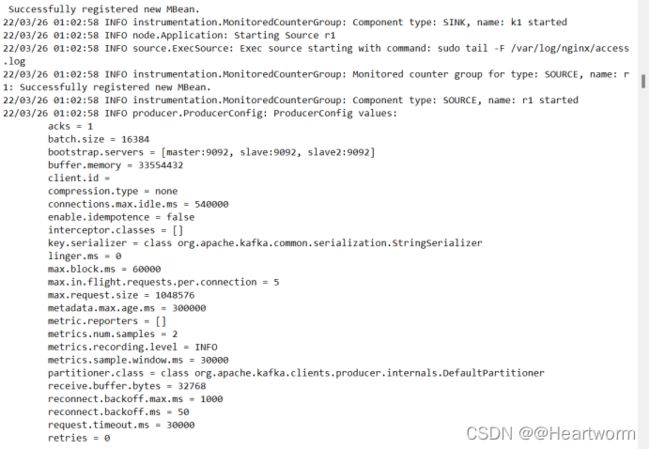
(3)启动Flume,在master使用以下命令:
flume-ng agent -n a1 -c conf -f /home/hadoop/lambda/nginx-memory-kafka-hdfs.properties
(4)检查hdfs和kafak是否都接收到了数据
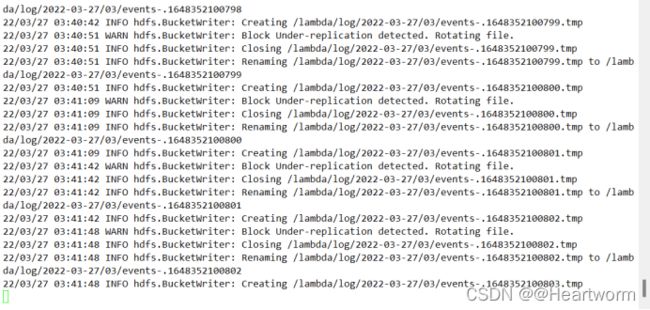
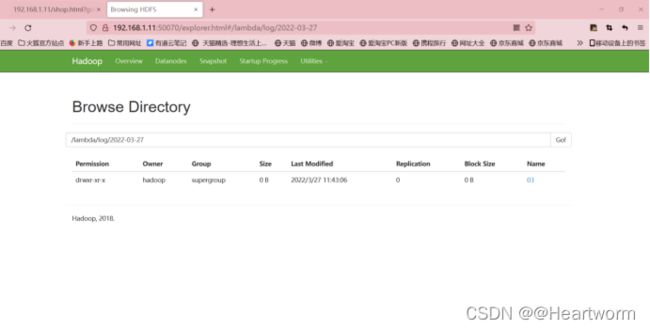

3 使用Spark SQL进行离线分析
离线分析的需求很简单,统计出每小时内商品浏览次数的排名,并保存到数据库中。
具体实现步骤如下所示:
(1)在MySQL创建shop_count_rank_hour表,步骤如下:
a)使用lambda登录MySQL
 b)使用lambda数据库,使用以下命令:
b)使用lambda数据库,使用以下命令:
USE lambda;
c)创建shop_count_rank_day_hour表,使用以下命令:
CREATE TABLE shop_count_rank_day_hour (
shop varchar(10) NOT NULL,
count int,
rank int,
day char(10) NOT NULL,
hour char(2) NOT NULL,
PRIMARY KEY(day, hour, shop)
);
d)退出MySQL
exit
 (2)在/home/hadoop/lambda目录创建LambdaBatch.py文件,使用命令:
(2)在/home/hadoop/lambda目录创建LambdaBatch.py文件,使用命令:
cd /home/hadoop/lambda
touch LambdaBatch.py
vim LambdaBatch.py
(3)填入以下代码:
import sys
# 导入 SparkSession
from pyspark.sql import SparkSession
# 导入 schema
from pyspark.sql.types import StructType, StructField, LongType, StringType
# 读取 day 和 hour 参数
day = sys.argv[1]
hour = sys.argv[2]
# 创建 SparkSession
spark = SparkSession.builder.appName("Lambda SQL").getOrCreate()
# 配置 Hadoop 的 HA 信息,用于从 Hadoop 读取数据
spark.sparkContext._jsc.hadoopConfiguration().set("dfs.nameservices", "ns")
spark.sparkContext._jsc.hadoopConfiguration().set('dfs.ha.namenodes.ns', 'nn1,nn2')
spark.sparkContext._jsc.hadoopConfiguration().set('dfs.namenode.rpc-address.ns.nn2', 'hdfs://master:9000')
spark.sparkContext._jsc.hadoopConfiguration().set('dfs.namenode.rpc-address.ns.nn1', 'hdfs://master:9000')
spark.sparkContext._jsc.hadoopConfiguration().set("dfs.client.failover.proxy.provider.ns", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider")
# 读取日志数据
rdd = spark.sparkContext.textFile("hdfs://ns/lambda/log/" + day + "/" + hour)
# ETL 清洗,获得日志中的 path
path = rdd.map(lambda x : [x.split(" ")[6], day, hour])
# 转换为 DataFrame
schema = StructType([StructField("path", StringType(), True), StructField("day", StringType(), True), StructField("hour", StringType(), True)])
df = spark.createDataFrame(path, schema)
# 注册为临时表
df.registerTempTable("log")
# 注册获取商品名称的 udf, 名字是 getShop, 返回值是 LongType 类型
spark.udf.register('getShop', lambda x : x.split("&")[0].split("=")[1], StringType())
# 使用 udf 获取商品名称
dws = spark.sql("""
SELECT getShop(path) shop
, day
, hour
FROM log
""")
# 注册为临时表
dws.registerTempTable("dws")
# 获取
ads = spark.sql("""
SELECT shop
, COUNT(*) count
, day
, hour
, DENSE_RANK() OVER(ORDER BY COUNT(*) DESC) rank
FROM dws
GROUP BY shop, day, hour
""")
# 保存分析结果到数据库
ads.write.mode("append").format("jdbc").options(
url='jdbc:mysql://master:3306',
user='lambda',
password='123456',
dbtable="lambda.shop_count_rank_day_hour",
batchsize="1000",
).save()

(4)创建lambdaBatch.sh脚本,使用以下命令:
touch lambdaBatch.sh
chmod +x lambdaBatch.sh
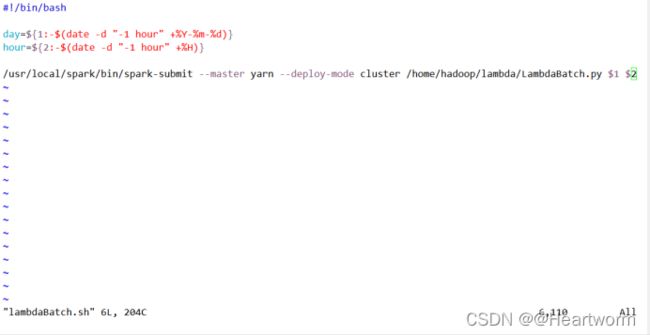
 (5)在lambdaBatch.sh脚本填入以下内容:
(5)在lambdaBatch.sh脚本填入以下内容:
#!/bin/bash
day=${1:-$(date -d "-1 hour" +%Y-%m-%d)}
hour=${2:-$(date -d "-1 hour" +%H)}
/usr/local/spark/bin/spark-submit --master yarn --deploy-mode cluster /home/hadoop/lambda/LambdaBatch.py $1 $2
 (6)把lambdaBatch.sh脚本加入定时任务,使用以下命令:
(6)把lambdaBatch.sh脚本加入定时任务,使用以下命令:
crontab -e
*/1 * * * * /home/hadoop/lambda/lambdaBatch.sh
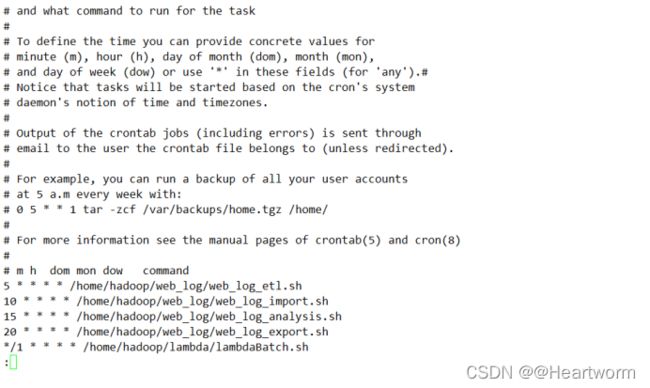
项目结束:结束后最好进入lambdaBatch.sh脚本把定时任务关掉,把添加的下面这行代码删除即可
*/1 * * * * /home/hadoop/lambda/lambdaBatch.sh