PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies
Abstract
PointNet++ 是点云理解领域最有影响力的神经网络架构之一。虽然近期出现了 PointMLP 和 Point Transformer 等新型网络,它们的精度已经大大超过了 PointNet++,但我们发现大部分性能提升是由于改进的训练策略,例如数据增强和优化技术以及增加的模型大小,而不是由于架构创新。因此,PointNet++ 的全部潜力尚未被充分发掘。在本研究中,我们通过系统性的模型训练和缩放策略对经典的 PointNet++ 进行了重新审视,并提出了两个主要贡献。首先,我们提出了一组改进的训练策略,显著提高了 PointNet++ 的性能。例如,我们展示了在不改变架构的情况下,PointNet++ 在 ScanObjectNN 对象分类任务上的整体准确率(OA)可以从 77.9 77.9 % 77.9 提高到 86.1 86.1 % 86.1,甚至超过了最先进的 PointMLP。其次,我们将倒置残差瓶颈设计和可分离 MLP 引入到 PointNet++ 中,实现了高效和有效的模型缩放,并提出了 PointNeXt,即 PointNets 的下一版本。PointNeXt 可以灵活地进行扩展,并在 3D 分类和分割任务上优于最先进的方法。在分类任务中,PointNeXt 在 ScanObjectNN 上达到了 87.7 87.7 % 87.7 的整体准确率,比 PointMLP 高 2.3 2.3 % 2.3,并且推理速度是其 10 10 10 倍。在语义分割任务中,PointNeXt 在 S3DIS 上实现了新的最先进性能,均值 IoU 达到 74.9 74.9 % 74.9(6 折交叉验证),优于最近的 Point Transformer。代码和模型可在 https://github.com/guochengqian/pointnext 上获取。
1 Introduction
近年来,三维数据采集技术的进步导致点云理解领域兴起了一股热潮。随着 PointNet [29] 和 PointNet++ [30] 的兴起,使用深度卷积神经网络处理未经结构化的点云数据成为了可能。在 “PointNets” 之后,许多基于点云的网络被引入,其中大部分专注于开发新的、精密的模块来提取局部结构,如 KPConv 中的伪网格卷积 [43] 和 Point Transformer 中的自注意力层 [56]。这些新提出的方法在各种任务中都大幅优于 PointNet++,给人留下了 PointNet++ 架构过于简单、难以学习复杂的点云表示的印象。在本研究中,我们重新审视了经典且广泛使用的 PointNet++ 网络,并发现它的全部潜力尚未被充分发掘,主要原因是 PointNet++ 时代缺少了两个因素:(1)更优秀的训练策略和(2)有效的模型缩放策略。
通过对各种基准测试的全面实证研究,例如用于对象分类的ScanObjecNN [44]和用于语义分割的S3DIS [1],我们发现训练策略,即数据增强和优化技术,在网络性能中起着重要作用。事实上,现有最先进(SOTA)方法 [ 46 , 43 , 56 ] [46,43,56] [46,43,56]相对于PointNet++ [30]的性能提升很大程度上是由于改进的训练策略,不幸的是,与体系结构的变化相比,这些策略不太被人所知。例如,训练过程中随机丢弃颜色可以意外地提高PointNet++在S3DIS [1]上的测试性能 5.9 5.9% 5.9平均交并比(mIoU),如表5所示。此外,采用标签平滑[39]可以将ScanObjectNN [44]的整体准确度(OA)提高 1.3 1.3% 1.3。这些发现激励我们重新审视PointNet++并为其配备今天广泛使用的新高级训练策略。令人惊讶的是,如图1所示,仅利用改进的训练策略就将PointNet++的OA在ScanObjectNN上提高了 8.2 8.2% 8.2(从 77.9 77.9% 77.9提高到 86.1 86.1% 86.1),在不引入任何架构更改的情况下建立了新的SOTA(详见第4.4.1节)。对于S3DIS分割基准测试,通过6倍交叉验证在所有区域评估的mIoU可以增加 13.6 13.6% 13.6(从 54.5 54.5% 54.5提高到 68.1 68.1% 68.1),超越了许多在PointNet++之后的现代架构,例如PointCNN [22]和DeepGCN [21]。

图1:训练策略和模型扩展对PointNet++[30]的影响。我们展示了改进的训练策略(数据增强和优化技术)和模型扩展可以显著提高PointNet++的性能。我们在ScanObjectNN [44]和S3DIS [1]上报告平均的整体精度和mIoU(6倍交叉验证)。
此外,我们观察到目前用于点云分析的主流模型 [ 20 , 43 , 56 ] [20,43,56] [20,43,56] 比最初的 PointNets [ 29 , 30 ] [29,30] [29,30] 使用了更多的参数。有效地将 PointNet++ 从原来的小规模扩展到大规模是值得研究的一个主题,因为更大的模型通常能够实现更丰富的表示并表现更好 [ 2 , 19 , 55 ] [2,19,55] [2,19,55]。然而,我们发现在 PointNet++ 中简单地使用更多的构建块或增加通道大小只会导致延迟的增加,而不会显著提高准确性(请参见第 4.4.2 节)。为了实现有效和高效的模型扩展,我们将残差连接 [13]、反向瓶颈设计 [36] 和可分离的 MLPs [32] 引入到 PointNet++ 中。现代化的架构被命名为 PointNeXt,是 PointNets 的下一个版本。PointNeXt 可以灵活扩展,并在各种基准测试中优于 SOTA。正如图 1 所示,PointNeXt 在 S3DIS [1] 6-fold 上将原始的 PointNet++ 提高了 20.4 20.4 % 20.4 的 mIoU(从 54.5 54.5 % 54.5 提高到 74.9 74.9 % 74.9),并在 ScanObjecNN [44] 上实现了 9.8 9.8 % 9.8 的 OA 增益,超过了 SOTA 的 Point Transformer [56] 和 PointMLP [28]。我们接下来总结我们的贡献:
- 我们首次对点云领域的训练策略进行了系统研究,并表明仅仅采用改进的训练策略就能使PointNet++在ScanObjectNN上的OA增加8.2%,在S3DIS上的mIoU增加13.6%,PointNet++在这些任务上成功反击了。这些改进的训练策略具有普适性,可以轻松应用于改进其他方法[29, 46, 28]。
- 我们提出了PointNeXt,PointNets的下一个版本。PointNeXt具有可扩展性,超过了所有研究任务的SOTA,包括对象分类[44, 49],语义分割[1, 5]和部分分割[53],同时在推理速度方面也优于SOTA。
2 Preliminary: A Review of PointNet++
我们的PointNeXt是基于PointNet++ [30]构建的,它使用了类似U-Net [35]的编码器和解码器结构,如图2所示。编码器部分使用一系列集合抽象(SA)块,以分层方式对点云特征进行抽象;而解码器通过相同数量的特征传播块逐步插值抽象的特征。SA块包括一个下采样层以降采样输入点,一个分组层以查询每个点的邻居,一组共享的多层感知机(MLPs)以提取特征,以及一个减少层以在邻居内聚合特征。分组层、MLPs和减少层的组合形式为:
x i l + 1 = R j : ( i , j ) ∈ N { h Θ ( [ x j l ; p j l − p i l ] ) } (1) \mathbf{x}_i^{l+1}=\mathcal{R}_{j:(i, j) \in \mathcal{N}}\left\{h_{\boldsymbol{\Theta}}\left(\left[\mathbf{x}_j^l ; \mathbf{p}_j^l-\mathbf{p}_i^l\right]\right)\right\} \tag1 xil+1=Rj:(i,j)∈N{hΘ([xjl;pjl−pil])}(1)
其中, R \mathcal{R} R 是缩减层(例如最大池化层),用于聚合点 i i i 的邻居特征,表示为 j : ( i , j ) ∈ N {j:(i, j) \in \mathcal{N}} j:(i,j)∈N。 p i l , x i l , x j l \mathbf{p}_i^l, \mathbf{x}_i^l, \mathbf{x}j^l pil,xil,xjl 分别是网络第 l l l 层中输入坐标、输入特征和邻居 j j j 的特征。 h Θ h{\Theta} hΘ 表示共享的 MLP,将 x j l \mathbf{x}_j^l xjl 和相对坐标 ( p j l − p i l ) \left(\mathbf{p}_j^l-\mathbf{p}_i^l\right) (pjl−pil) 的连接作为输入。需要注意的是,由于使用单尺度分组的 PointNet++ 是原论文中使用的默认架构,即每个阶段使用一个 SA 块,因此我们在整个论文中都将其称为 PointNet++ 并将其用作我们的基线。
3 Methodology: From PointNet++ to PointNeXt
在本节中,我们介绍了如何将经典架构PointNet++[30]现代化为具有SOTA性能的下一代PointNet++:PointNeXt。我们的研究主要集中在两个方面:(1)现代化的训练方法,以改进数据增强和优化技术,以及(2)现代化的架构,以探究感受野的缩放和模型的缩放。这两个方面都对模型的性能有重要影响,但以前的研究还没有很好地探讨这些问题。
3.1 Training Modernization: PointNet++ Strikes Back
我们进行了系统性研究,量化了现代点云网络( [ 46 , 43 , 56 ] [46,43,56] [46,43,56])使用的每种数据增强和优化技术的影响,并提出了一组改进的训练策略。采用我们提出的训练策略可以揭示出 PointNet++ 的潜力。
3.1.1 Data Augmentation
数据增强是提高神经网络性能的最重要策略之一,因此我们从那里开始进行现代化。原始的PointNet ++在各种基准测试中使用了随机旋转、缩放、平移和抖动的简单数据增强组合[30]。近期的方法采用比PointNet++中使用的更强的增强策略。例如,KPConv [43] 在训练期间随机丢弃颜色,Point-BERT [54] 使用常见的点重采样策略从原始点云中随机采样1024个点进行数据缩放,而RandLA-Net [15]和Point Transformer [56]在分割任务中将整个场景作为输入。在本文中,我们通过添加性研究量化了每种数据增强的效果。
我们从PointNet++ [30]作为基线开始我们的研究,该基线使用原始的数据增强和优化技术进行训练。我们逐个移除每个数据增强以检查其是否必要。我们添加回有用的增强但移除不必要的增强。然后,我们系统地研究了代表性工作 [46, 43, 32, 56, 28, 54] 中使用的所有数据增强,包括数据缩放,如点重采样[54]和将整个场景加载为输入[15],随机旋转、随机缩放、平移以移动点云、抖动以为每个点添加独立噪声、高度附加[43](即将沿物体重力方向的每个点的测量附加为附加输入特征)、自动对比度调整颜色对比度[56]和颜色随机丢弃,将颜色随机替换为零值。我们逐步验证数据增强的有效性,并仅保留提供更好验证准确性的增强。在此研究的结尾,我们提供了每个任务的数据增强集合,以实现模型性能的最大提升。第4.4.1节详细介绍和分析了发现的结果。
3.1.2 Optimization Techniques
优化技术包括损失函数、优化器、学习率调度器和超参数,对神经网络的性能也至关重要。 PointNet++ 在其实验中使用相同的优化技术:CrossEntropy 损失函数,Adam 优化器 [16],指数学习率衰减(Step Decay)和相同的超参数。由于机器学习理论的发展,现代神经网络可以使用理论上更好的优化器(例如AdamW [27] v s Adam [16])和更高级的损失函数(具有标签平滑的CrossEntropy [39])。类似于我们对数据增强的研究,我们还量化了每种现代优化技术对 PointNet++ 的影响。我们首先对学习率和权重衰减进行顺序超参数搜索。然后,我们对标签平滑、优化器和学习率调度器进行了逐步研究。我们发现了一组改进的优化技术,进一步提高了性能。总的来说,带有标签平滑的CrossEntropy、AdamW和Cosine Decay可以在各种任务中相对优化模型的表现。有关详细结果,请参见第4.4.1节。
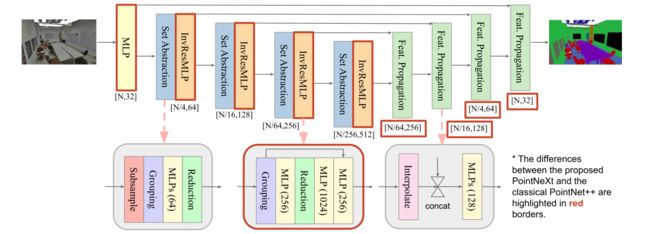
图2:PointNeXt架构。PointNeXt与PointNet++ [30]共享相同的Set Abstraction和Feature Propagation块,同时在开头添加了一个额外的MLP层,并使用提出的倒置残差MLP(InvResMLP)块来扩展架构。
3.2 Architecture Modernization: Small Modifications → Big Improvement
在这个小节中,我们将 PointNet++ [30] 现代化成提出的 PointNeXt。这个现代化包含两个方面:(1)感受野尺度的缩放和(2)模型尺度的缩放。
3.2.1 Receptive Field Scaling
在神经网络设计空间中,感受野是一个重要的因素[38,7]。在点云处理中,至少有两种方法可以扩大感受野:(1)采用更大的半径来查询邻域,和(2)采用分层结构。由于分层结构已经被原始的PointNet++采用,因此我们主要在本小节中研究(1)。需要注意的是,PointNet++的半径设置为一个初始值 r r r,当点云下采样时翻倍。我们在每个基准测试中研究不同的初始值,发现半径是特定于数据集的,对性能有重大影响。这将在4.4.2节中详细阐述。
此外,我们发现方程(1)中的相对坐标 Δ p = p j l − p i l \Delta_p = \mathbf{p}_j^l-\mathbf{p}_i^l Δp=pjl−pil使网络优化更加困难,导致性能下降。因此,我们提出相对位置归一化( Δ p \Delta_p Δp 归一化),将相对位置除以邻域查询半径:
x i l + 1 = R j : ( i , j ) ∈ N { h Θ ( [ x j l ; ( p j l − p i l ) / r l ] ) } . (2) \mathbf{x}_i^{l+1}=\mathcal{R}_{j:(i, j) \in \mathcal{N}}\left\{h_{\boldsymbol{\Theta}}\left(\left[\mathbf{x}_j^l ;\left(\mathbf{p}_j^l-\mathbf{p}_i^l\right) / r^l\right]\right)\right\} . \tag2 xil+1=Rj:(i,j)∈N{hΘ([xjl;(pjl−pil)/rl])}.(2)
没有归一化时,相对位置的值( Δ p = p j l − p i l \Delta_p=\mathbf{p}_j^l-\mathbf{p}_i^l Δp=pjl−pil)非常小(小于半径),需要网络学习更大的权重来应用于 Δ p \Delta_p Δp。这使得优化变得非常困难,特别是由于使用了权重衰减以减少网络的权重,因此容易忽略相对位置的影响。所提出的归一化通过重新缩放来减轻了这个问题,并同时减少了不同阶段 Δ p \Delta_p Δp 的方差。
3.2.2 Model Scaling
PointNet++ 是一个相对较小的网络,在分类结构中编码器仅由 2 个阶段组成,而在分割中为 4 个阶段。每个阶段仅包含 1 个 SA 块,每个块包含 3 层 MLP。PointNet++ 的模型大小用于分类和分割都小于 2 2 2M,这与通常使用超过 10 10 10M 参数的现代网络相比要小得多。有趣的是,我们发现,即使附加更多的 SA 块或使用更多的通道,也不会导致明显的精度提高,而会导致吞吐量显著下降(请参见第 4.4.2 节),主要原因是梯度消失和过拟合。因此,在本小节中,我们研究如何有效且高效地扩展 PointNet++。
我们提出了反向残差多层感知机(InvResMLP)块,以实现有效和高效的模型扩展。在每个阶段的第一个SA块之后追加InvResMLP块,其结构如图2中间下方所示。InvResMLP与SA之间有三个不同之处。 (1)添加了输入和输出之间的残差连接,以减轻梯度消失问题[13],特别是当网络更深时。 (2)引入可分离的MLP以减少计算量并增强点特征提取。尽管原始SA块中的所有3个MLP层都是在邻域特征上计算的,InvResMLP将MLP分成一层计算邻域特征(在分组和缩减层之间)和两层计算点特征(在缩减层之后),受MobileNet [14]和ASSANet [32]启发。 (3)利用倒置瓶颈设计[36]将第二个MLP的输出通道扩展4倍,以丰富特征提取。追加InvResMLP块被证明可以显着提高性能,相比追加原始SA块而言(请参见第4.4.2节)。
此外,我们在宏观架构上提出了三个变化。 (1) 我们统一了 PointNet++ 分类和分割编码器的设计,即将分类的 SA 块数量从 2 扩展到 4,同时在每个阶段保持原始数量 (4 个块) 用于分割。 (2) 我们使用对称解码器,其通道大小改变以匹配编码器。 (3) 我们添加了一个 stem MLP,即一个额外的 MLP 层插入到架构的开头,将输入点云映射到更高的维度。
总之,我们提出了 PointNeXt,这是 PointNets [ 29 , 52 ] [29,52] [29,52] 的下一个版本,通过结合所提出的 InvResMLP 和上述的宏体系结构更改从 PointNet++ 进行修改。PointNeXt 的体系结构如图 2 所示。我们将 stem MLP 的通道大小表示为 C C C,InvResMLP 块的数量表示为 B B B。更大的 C C C 导致网络的宽度增加(即宽度扩展),而更大的 B B B 导致网络的深度增加(即深度扩展)。当 B = 0 B=0 B=0 时,在每个阶段仅使用一个 SA 块和没有 InvResMLP 块。SA 块中 MLP 层数为 2,每个 SA 块内部添加一个残差连接。当 B ≠ 0 B \neq 0 B=0 时,在原始 SA 块后添加 InvResMLP 块。在这种情况下,SA 块中 MLP 层数设置为 1 以节省计算成本。我们的 PointNeXt 系列的配置如下所述:
- PointNeXt-S: C = 32 , B = 0 C=32, B=0 C=32,B=0
- PointNeXt-L: C = 32 , B = ( 2 , 4 , 2 , 2 ) C=32, B=(2,4,2,2) C=32,B=(2,4,2,2)
- PointNeXt-B: C = 32 , B = ( 1 , 2 , 1 , 1 ) C=32, B=(1,2,1,1) C=32,B=(1,2,1,1)
- PointNeXt-XL: C = 64 , B = ( 3 , 6 , 3 , 3 ) C=64, B=(3,6,3,3) C=64,B=(3,6,3,3)
5 Related Work
点云方法直接使用点云的无结构格式进行处理,相比于基于体素的方法[10, 4]和基于多视图的方法[37, 12, 9]。点云网络(PointNet) [29] 是点云方法的先驱工作,通过限制特征提取为逐点方式,使用共享的MLP模型来建模点的置换不变性。点云网络++(PointNet++) [30] 的出现旨在提高PointNet的性能,以捕捉局部几何结构。目前,大多数基于点云的方法都专注于局部模块的设计。[46、45、31]采用图神经网络,[51、22、43、42]将点云投影到伪网格上,以允许进行规则卷积,[48、23、24]通过局部结构确定的权重自适应地聚合邻域特征。此外,最近的一些方法通过类似于Transformer的网络 [ 56 , 17 ] [56,17] [56,17],利用自注意力来提取局部信息。我们的工作不追随这种局部模块设计的趋势。相反,我们将注意力转移到另一个重要但鲜为人知的方面,即训练和扩展策略。
最近对于图像分类领域的训练策略已经得到了研究 [ 2 , 47 , 26 ] [2,47,26] [2,47,26]。在点云领域,SimpleView [9]是第一篇展示训练策略对神经网络性能有重要影响的工作。然而,SimpleView仅仅采用了与DGCNN [46]相同的训练策略。相反,我们进行了系统研究,以量化每种数据增强和优化技术的影响,并提出了一组改进的训练策略,可以提高PointNet++ [30]和其他代表性工作 [ 29 , 46 , 28 ] [29,46,28] [29,46,28]的性能。
模型扩展能够显著提高网络性能,这在各个领域的开创性工作中得到了证明 [ 40 , 55 , 21 ] [40,55,21] [40,55,21]。与使用少于 2 2 2M参数的PointNet++ [ 30 ] [30] [30]相比,大多数当前流行的网络的参数超过了 10 10 10M,例如KPConv [ 43 ] [43] [43](15M)和PointMLP [ 28 ] [28] [28](13M)。在我们的工作中,我们探索了一些有效且高效的PointNet++模型扩展策略。我们提供了实际建议,即使用残差连接和反向瓶颈设计来提高性能,同时使用可分离MLP来保持吞吐量。
6 Conclusion and Discussion
本文展示了通过改进训练和模型缩放策略,PointNet++的性能可以提高到超过当前的最新技术。具体而言,我们量化了每种数据增强和优化技术的效果,并提出了一组改进的训练策略。这些策略可以轻松应用于提高PointNet++和其他代表性作品的性能。我们还将反向残差MLP块引入PointNet++中以开发PointNeXt。我们展示了PointNeXt在各种基准测试中具有卓越的性能和可伸缩性,同时保持高吞吐量。本研究旨在引导研究人员更加关注训练和缩放策略的影响,并激励未来的研究朝这个方向发展。
Limitation. 虽然PointNeXt-XL是所有代表性基于点的网络[30、43、15、56]中最大的之一,但它的参数数量(44M)仍然低于图像分类中的小型网络,例如Swin-S [25](50M)、ConNeXt-S [26](50M)和ViT-B [8](87M),并且远远低于它们的大型变体,包括Swin-L(197M)、ConvNeXt-XL(350M)和ViT-L(305M)。在这项工作中,我们没有进一步推动模型大小,主要是因为与更大的图像数据集(如ImageNet [6])相比,点云数据集具有更小的规模。此外,由于重点不在引入新的架构变化上,因此我们的工作受到现有模块的限制。
论文链接:https://arxiv.org/pdf/2206.04670.pdf