详解Flink作业提交流程
一、提交流程
Flink 作业在开发完毕之后,需要提交到 Flink 集群执行。ClientFronted 是入口,触发用户开发的 Flink 应用 Jar 文件中的 main 方法,然后交给 PipelineExecutor(流水线执行器,在 FlinkClient 升成 JobGraph 之后,将作业提交给集群的重要环节。)#execue 方法,最终会选择一个触发一个具体的 PiplineExecutor 执行。


提交模式又可分为:
-
Detached:Flink Client 创建完集群之后,可以退出命令行窗口,集群独立运行。
-
Attached:不能关闭命令行窗口,需要与集群之间维持连接。
1.1 Yarn Session 提交流程

启动集群:
-
使用 bin/yarn-session.sh 提交会话模式的作业。如果提交到已经存在的集群,则获取 Yarn 集群信息、应用 ID,并准备提交作业。如果启动新的 Yarn Session 集群,则进入步骤(2)
-
Yarn 启动新 Flink 集群
1)如果没有集群,则创建一个新的 Session 模式的集群。首先将应用配置(flink-conf.yaml、logback.xml、log4j.properties)和相关文件(Flink Jar、配置类文件、用户 Jar 文件、JobGraph 对象等)上传至分布式存储(如 HDFS)的应用暂存目录。
2)通过 Yarn Client 向 Yarn 提交 Flink 创建集群的申请,Yarn 分配资源,在申请的 Yarn Container 中初始化并启动 FlinkJobManager 进程,在 JobManager 进程中运行 YarnSessionClusterEntrypoint 作为集群启动入口(不同的集群部署模式有不同的 ClusterEntrypoint 实现),初始化 Dispatcher、ResourceManager,启动相关的 RPC 服务,等待 Client 通过 Rest 接口提交作业。
作业提交:
Yarn 集群准备好后,开始作业提交。
1)Flink Client 通过 Rest 向 Dispatcher 提交 JobGraph。
2)Dispatcher 是 Rest 接口,不负责实际的调度、执行方面的工作,当收到 JobGraph 后,为作业创建一个 JobMaster,将工作交给 JobManager(负责作业调度、管理作业和 Task 的生命周期),构建 ExecutionGraph(JobGraph 的并行化版本,调度层最核心的数据结构)。
这两个步骤结束后,作业进入调度执行阶段。
作业调度执行:
1)JobMaster 向 YarnResourceManager 申请资源,开始调度 ExecutionGraph 执行,向 YarnResourceManager 申请资源;初次提交作业集群中尚没有 TaskManager,此时资源不足,开始申请资源。
2)YarnResourceManager 收到 JobManager 的资源请求,如果当前有空闲 Slot 则将 Slot 分配给 JobMaster.,否则 YarnResourceManager 将向 YarnMaster 请求创建 TaskManager。
3)YarnResourceManager 将资源请求加入到等待请求队列,并通过心跳向 Yarn RM 申请新的 Container 资源来启动 TaskManager 进程,Yarn 分配新的 Container 给 TaskManager。
4)YarnResourceManager 启动,然后从 HDFS 加载 Jar 文件等所需要的的相关资源,在容器中启动 TaskManager。
5)TaskManager 启动之后,向 ResourceManager 注册,并把自己的 Slot 资源情况汇报给 ResouceManager。
6)ResourceManager 从等待队列中取出 Slot 请求,向 TaskManager 确认资源可用情况,并告知 TaskManager 将 Slot 分配给哪个 JobMaster。
7)TaskManager 向 JobMaster 提供 Slot,JobMaster 调度 Task 到 TaskManager 的此 Slot 上执行。
1.2 Yarn Per-Job 提交流程

启动集群:
-
使用./flink run -m yarn-cluster 提交 Per-Job 模式的作业。
-
Yarn 启动 Flink 集群。该模式下 Flink 集群的启动入口是 YarnJobClusterEntryPoint,其他与 YarnSession 模式下集群的启动类似。
作业提交:
该步骤与 Seesion 模式下的不同,Client 并不会通过 Rest 向 Dispatcher 提交 JobGraph,由 Dispatcher 从本地文件系统获取 JObGraph,其后的不好走与 Session 模式的一样
作业调度执行:
与 Yarn Session 模式下一致。
1.3 K8s Session 提交流程
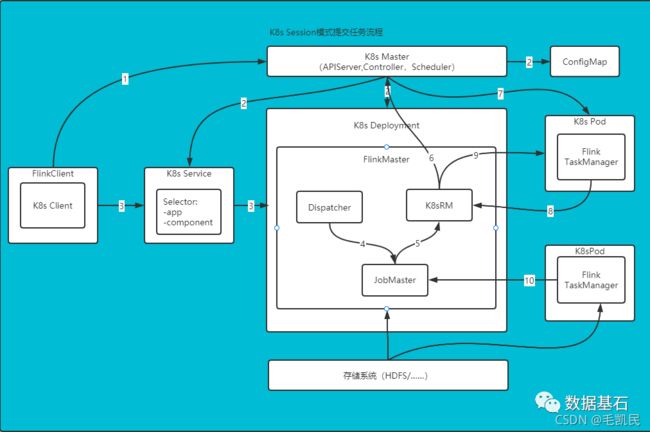
启动集群:
-
Flink 客户端首先连接 Kubernetes API Server,提交 Flink 集群的资源描述文件,包括 flink-configuration-configmap.yaml、jobmanager-service.yaml、jobmanager-deployment.yaml 和 taskmanager-deployment.yaml 等。
-
Kubernets Master 会根据这些资源描述文件去创建对应的 Kubernetes 实体。以 JobManager 部署为例,Kubernetes 集群中的某个节点收到请求后,Kubelet 进程会从中央仓库下载 Flink 镜像,准备和挂载卷,然后执行启动命令。Pod 启动后 Flink Master(JobManager)进程随之启动,初始化 Dispacher 和 KubernetesResourceManager。并通过 K8s 服务对外暴露 FlinkMaster 的端口,K8s 服务类似于路由服务。
两个步骤完成之后,Session 模式的集群就创建成功,集群可以接收作业提交请求,但是此时还没有 JobManager、TaskManager,当作业需要执行时,才会按需创建。
作业提交:
-
Client 用户可以通过 Flink 命令行(即 Flink Client)向这个会话模式的集群提交任务。此时 JobGraph 会在 FlinkClient 端生成,然后和用户 Jar 包一起通过 RestClient 上传。
-
作业提交成功,Dispatcher 会为每个作业启动一个 JobMaster,将 JobGraph 交给 JobMaster 调度执行。
两个步骤完成之后,作业进入调度执行阶段。
作业调度执行:
K8s Session 模式集群下,ResourceManager 向 k8sMaster 申请和释放 TaskManager,除此之外,作业的调度与执行和 Yarn 模式是一样的。
1)JobMaster 向 KubernetesResourceManager 请求 Slot。
2)KubernetesResourceManager 从 kubernetes 集群分配 TaskManager。每个 TaskManager 都是具有唯一标识的 Pod。KubernetesResourceManager 会为 TaskManager 生成一份新的配置文件,里面有 Flink Master 的 service name 作为地址。这样在 FLInkMaster failover 之后,TaskManager 仍然可以重新连上。
3)Kubernetes 集群分配一个新的 Pod 后,在上面启动 TaskManager。
4)TaskManager 启动后注册到 SlotManager。
5)SlotManager 向 TaskManager 请求 Slot.
6)TaskManager 提供 Slot 给 JobMaster,然后任务就会被分配到这个 Slot 上运行。
二、Graph 总览

-
流计算应用的 Graph 转换:StreamGraph-->JobGraph-->ExecutionGraph-->物理执行图(启动计算任务)
-
批处理应用的 Graph 转换:OptimizedPlan-->JobGraph
-
Table & SQL API 的 Graph 转换:Blink Table Planner Flink Table Planner。
2.1 流图
使用 DataStreamAPI 开发的应用程序,首先被转换为 Transformation,然后被映射为 StreamGraph。
2.1.1 SteramGraph 核心对象
-
StreamNode
StreamNode 是 StremGraph 中的节点 ,从 Transformation 转换而来,可以简单理解为一个 StreamNode 表示一个算子,从逻辑上来说,SteramNode 在 StreamGraph 中存在实体和虚拟的 StreamNode。StremNode 可以有多个输入,也可以有多个输出。
实体的 StreamNode 会最终变成物理算子。虚拟的 StreamNode 会附着在 StreamEdge 上。
-
StreamEdge
StreamEdge 是 StreamGraph 中的边,用来连接两个 StreamNode,一个 StreamNode 可以有多个出边、入边,StreamEdge 中包含了旁路输出、分区器、字段筛选输出等信息。
2.1.2 StreamGraph 生成过程
StreamGraph 在 FlinkClient 中生成,由 FlinkClient 在提交的时候触发 Flink 应用的 main 方法,用户编写的业务逻辑组装成 Transformation 流水线,在最后调用 StreamExecutionEnvironment.execute() 的时候开始触发 StreamGraph 构建。
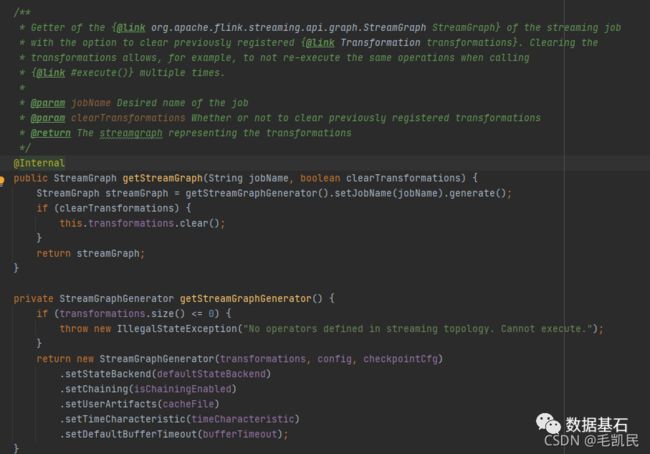
StreamGraph 实际上是在 StreamGraphGenerator 中生成的,从 SinkTransformation(输出) 向前追溯到 SourceTransformation。在遍历过程中一边遍历一边构建 StreamGraph。

在遍历 Transformation 的过程中,会对不同类型的 Transformation 分别进行转换。对于物理 Transformation 则转换为 StreamNode 实体,对于虚拟 Transformation 则作为虚拟 StreamNode。
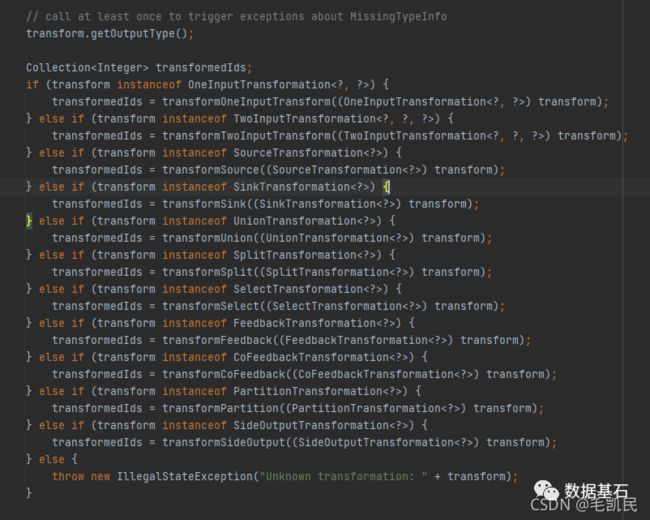
针对于某一种类型的 Transformation,会调用其相应的 transformxxx()函数进行转换。transfromxxx()首先转换上游 Transformation 进行递归转换,确保上游的都已经完成了转换。然后通过 addOperator()方法构造出 StreamNode,通过 addEdge()方法与上游的 transform 进行连接,构造出 StreamEdge。
在添加 StreamEdge 的过程中,如果 ShuffleMode 为 null,则使用 ShuffleMode PIPELINED 模式,在流计算中,只有 PIPLINED 模式才会在批处理中设计其他模式。构建 StreamEdge 的时候,在转换 Transformation 过程中生成的 虚拟 StreamNode 会将虚拟 StreamNode 的信息附着在 StreamEdge 上
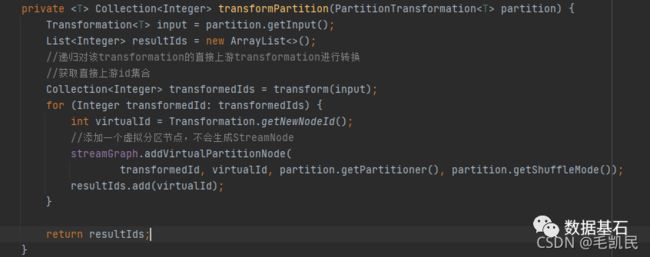
2.1.3 虚拟 Transformation 的转换
虚拟的 Transformation 生成的时候不会转换为 SteramNode,而是添加为虚拟节点。
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner partitioner,
List outputNames,
OutputTag outputTag,
ShuffleMode shuffleMode) {
//当上游是sideoutput时,递归调用,并传入sideoutput信息
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag, shuffleMode);
}
//当上游是select时,递归调用,并传入select信息
else if (virtualSelectNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSelectNodes.get(virtualId).f0;
if (outputNames.isEmpty()) {
// selections that happen downstream override earlier selections
outputNames = virtualSelectNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode);
}
//当上游是Partition时,递归调用,并传入Partition信息
else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode);
}
//不是以上逻辑转换的情况,真正构建StreamEdge
else {
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
//没有指定partitioner时,会为其选择forward或者rebalance
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner
2.2 作业图
JobGraph 可以由流计算的 StreamGraph 和批处理的 OptimizedPlan 转换而来。流计算中,在 StreamGraph 的基础上进行了一些优化,如果通过 OperatorChain 机制将算子合并起来,在执行时,调度在同一个 Task 线程上,避免数据的跨线程、跨网段的传递。

2.2.1 JobGraph 核心对象
-
JobVertex
经过算子融合优化后符合条件的多个 SteramNode 可能会融合在一起生成一个 JobVertex,即一个 JobVertex 包含一个或多个算子,JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
-
JobEdge
JobEdge 是 JobGraph 中连接 IntermediateDataSet 和 JobVertex 的边,表示 JobGraph 中的一个数据流转通道,其上游数据源是 IntermediateDataSet,下游消费者是 JobVertex。数据通过 JobEdge 由 IntermediateDataSet 传递给 JobVertex。
-
IntermediateDataSet
中间数据集 IntermediateDataSet 是一种逻辑结构,用来表示 JobVertex 的输出,即该 JobVertex 中包含的算子会产生的数据集。不同的执行模式下,其对应的结果分区类型不同,决定了在执行时刻数据交换的模式。
IntermediateDataSet 的个数与该 JobVertex 对应的 StreamNode 的出边数量相同,可以是一个或者多个。
2.2.2 JobGraph 生成过程


StreamingJobGraphGenerator 负责流计算 JobGraph 的生成,在转换前需要进行一系列的预处理。
private JobGraph createJobGraph() {
preValidate();
// make sure that all vertices start immediately
//设置调度模式
jobGraph.setScheduleMode(streamGraph.getScheduleMode());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
//为每个节点生成确定的hashid作为唯一表示,在提交和执行过程中保持不变。
Map hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
//为了向后保持兼容,为每个节点生成老版本的hash id
List> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
Map>> chainedOperatorHashes = new HashMap<>();
//真正对SteramGraph进行转换,生成JobGraph图
setChaining(hashes, legacyHashes, chainedOperatorHashes);
setPhysicalEdges();
//设置共享slotgroup
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getMinResources(),
id -> streamGraph.getStreamNode(id).getManagedMemoryWeight());
//配置checkpoint
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
//如果有之前的缓存文件的配置,则重新读入
JobGraphGenerator.addUserArtifactEntries(streamGraph.getUserArtifacts(), jobGraph);
// set the ExecutionConfig last when it has been finalized
try {
//设置执行环境配置
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException("Could not serialize the ExecutionConfig." +
"This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}
预处理完毕后,开始构建 JobGraph 中的点和边,从 Source 向下遍历 StreamGraph,逐步创建 JObGraph,在创建的过程中同事完成算子融合(OperatorChain)优化。

执行具体的 Chain 和 JobVertex 生成、JobEdge 的关联、IntermediateDataSet。从 StreamGraph 读取数据的 StreamNode 开始,递归遍历同时将 StreamOperator 连接在一起。
整理构建的逻辑如下(看上图!!!):
1)从 Source 开始,Source 与下游的 FlatMap 不可连接,Source 是起始节点,自己成为一个 JobVertx。
2)此时开始一个新的连接分析,FlatMap 是起始节点,与下游的 KeyedAgg 也不可以连接,那么 FlatMap 自己成为一个 JobVertex。
3)此时开始一个新的连接分析。KeyedAgg 是起始节点,并且与下游的 Sink 可以连接,那么递归地分析 Sink 节点,构造 Sink 与其下游是否可以连接,因为 Slink 没有下游,所以 KeyedAgg 和 Sink 节点连接在一起,共同构成了一个 JobVertex。在这个 JobVertex 中,KeyedAgg 是起始节点,index 编号为 0,sink 节点 index 编号为 1.
构建 JobVertex 的时候需要将 StreamNode 中的重要配置信息复制到 JobVertex 中。构建好 JobVertex 之后,需要构建 JobEdge 将 JobVertex 连接起来。KeyedAgg 和 Sink 之间构成了一个算子连接,连接内部的算子之间无序构成 JobEdge 进行连接。
在构建 JobEdge 的时候,很重要的一点是确定上游 JobVertex 和下游 JobVertex 的数据交换方式。此时根据 ShuffleMode 来确定 ResultPartition 类型,用 FlinkPartition 来确定 JobVertex 的连接方式。
Shuffle 确定了 ResultPartition,那么就可以确定上游 JobVertex 输出的 IntermediateDataSet 的类型了,也就知道 JobEdge 的输入 IntermediateDataSet。
ForwardPartitioner 和 RescalePartitioner 两种类型的 Partitioner 转换为 DistributionPattern.POINTWISE 的分发模式。其他类型的 Partitioner 统一转换为 DistributionPattern.ALL_TO_ALL 模式。
JobGraph 的构建和 OperatorChain 优化:
private List createChain(
Integer startNodeId,
Integer currentNodeId,
Map hashes,
List> legacyHashes,
int chainIndex,
Map>> chainedOperatorHashes) {
if (!builtVertices.contains(startNodeId)) {
List transitiveOutEdges = new ArrayList();
List chainableOutputs = new ArrayList();
List nonChainableOutputs = new ArrayList();
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
//获取当前节点的出边,判断是否符合OperatorChain的条件
//分为两类:chainableoutputs,nonchainableoutputs
for (StreamEdge outEdge : currentNode.getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
//对于chainable的边,递归调用createchain
//返回值添加到transitiveOutEdges中
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(startNodeId, chainable.getTargetId(), hashes, legacyHashes, chainIndex + 1, chainedOperatorHashes));
}
//对于无法chain在一起的边,边的下游节点作为Operatorchain的Head节点
//进行递归调用,返回值添加到transitiveOutEdges中
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(nonChainable.getTargetId(), nonChainable.getTargetId(), hashes, legacyHashes, 0, chainedOperatorHashes);
}
List> operatorHashes =
chainedOperatorHashes.computeIfAbsent(startNodeId, k -> new ArrayList<>());
byte[] primaryHashBytes = hashes.get(currentNodeId);
OperatorID currentOperatorId = new OperatorID(primaryHashBytes);
for (Map legacyHash : legacyHashes) {
operatorHashes.add(new Tuple2<>(primaryHashBytes, legacyHash.get(currentNodeId)));
}
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));
chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs));
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
//如果当前节点是起始节点,则直接创建JobVertex,否则返回一个空的StreamConfig
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes)
: new StreamConfig(new Configuration());
//将StreamNode中的配置信息序列化到Streamconfig中。
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs);
//再次判断,如果是Chain的起始节点,执行connect()方法,创建JobEdge和IntermediateDataset
//否则将当前节点的StreamConfig 添加到chainedConfig中。
if (currentNodeId.equals(startNodeId)) {
config.setChainStart();
config.setChainIndex(0);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
for (StreamEdge edge : transitiveOutEdges) {
connect(startNodeId, edge);
}
config.setOutEdgesInOrder(transitiveOutEdges);
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
chainedConfigs.computeIfAbsent(startNodeId, k -> new HashMap());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}
2.2.3 算子融合
一个 Operatorchain 在同一个 Task 线程内执行。OperatorChain 内的算子之间,在同一个线程内通过方法调用的方式传递数据,能减少线程之间的切换,减少消息的序列化/反序列化,无序借助内存缓存区,也无须通过网络在算子间传递数据,可在减少延迟的同时提高整体吞吐量
operatorchain 的条件:
1)下游节点的入度为 1
2)SteramEdge 的下游节点对应的算子不为 null
3)StreamEdge 的上游节点对应的算子不为 null
4)StreamEdge 的上下游节点拥有相同的 slotSharingGroup,默认都是 default.
5)下游算子的连接策略为 ALWAYS.
6)上游算子的连接策略为 ALWAYS 或者 HEAD.
7)StreamEdge 的分区类型为 ForwardPartitioner
8)上下游节点的并行度一致
9)当前 StreamGraph 允许 chain
2.3 执行图

2.3.1 ExecutionGraph 核心对象
-
ExecutionJobVertex
该对象和 JobGraph 中的 JobVertex 一一对应。该对象还包含了一组 ExecutionVertex,数量与该 JobVertex 中所包含的 SteramNode 的并行度一致。
ExecutionJobVertex 用来将一个 JobVertex 封装成一 ExecutionJobVertex,并以此创建 ExecutionVertex、Execution、IntermediateResult 和 IntermediateResultPartition,用于丰富 ExecutionGraph。
在 ExecutionJobVertex 的构造函数中,首先是依据对应的 JobVertex 的并发度,生成对应个数的 ExecutionVertex。其中,一个 ExecutionVertex 代表一个 ExecutionJobVertex 的并发子 Task。然后是将原来 JobVertex 的中间结果 IntermediateDataSet 转化为 ExecutionGrap 中 IntermediateResult
-
ExecutionVertex
ExecutionJobVertex 中会对作业进行并行化处理,构造可以并行执行的实例,每个并行执行的实例就是 ExecutionVertex.
构建 ExecutionVertex 的同时,也回构建 ExecutionVertex 的输出 IntermediateResult。并且将 ExecutionEdge 输出为 IntermediatePartition。
ExecutionVertex 的构造函数中,首先会创建 IntermediatePartition,并通过 IntermediateResult.setPartition()建立 IntermediateResult 和 IntermediateResultPartition 之间的关系,然后生成 Execution,并配置资源相关。
-
IntermediateResult
IntermediateResult 又叫做中间结果集,该对象是个逻辑概念,表示 ExecutionJobVertex 的输出,和 JobGraph 中的 IntermediateDataSet 一一对应,同样,一个 ExecutionJobVertex 可以有多个中间二级果,取决于当前 JobVertex 有几个出边。
一个中间结果集包含多个中间结果分区 IntermediateResultPartition,其个数等于该 JobVertex 的并发度。
-
IntermediateResultPartition IntermediateResultPartition 又叫做中间结果分区,表示 1 个 ExecutionVertex 输出结果,与 ExecutionEdge 相关联。
-
ExecutionEdge
表示 ExecutionVertex 的输入,连接到上游产生的 IntermediateResultPartition。一个 Execution 对应于唯一的一个 IntermediateResultPartition 和一个 ExecutionVertex。一个 ExecutionVertex 可以有多个 ExecutionEdge。
-
Execution
ExecutionVertex 相当于每个 Task 的模板,在真正执行的时候,会将 ExecutionVertex 中的信息包装为一个 Execution,执行一个 ExecutionVertex 的一次尝试。JobManager 和 TaskManager 之间关于 Task 的部署和 Task 执行状态的更新都是通过 ExecutionAttemptID 来标识实例的。在故障或者数据需要重算的情况下,ExecutionVertex 可能会有多个 ExecutionAttemptID.一个 Execution 通过 ExecutionAttemptID 标识。
2.3.2 ExecutionGrap 生成过程
初始话作业调度器的时候,根据 JobGra ph 生活 ExecutionGraph。在 SchedulerBase 的构造方法中触发构建,最终调用 SchedulerBase#createExecutionGraph 触发实际的构建动作,使用 ExecutionGraphBuiler 构建 ExecutionGraph。

核心代码 attachJobGraph:

构建 ExecutionEdge 的连接策略:
-
点对点连接(DistributionPatter n.POINTWISE)
该策略用来连接当前 ExecutionVertex 与上游的 IntermediataeResultParition。
连接分三种情况
1)一对一连接:并发的 Task 数量与分区数相等。
2)多对一连接:下游的 Task 数量小于上游的分区数,此时分两种情况:
a:下游 Task 可以分配同数量的结果分区 IntermediataeResultParition。如上游有 4 个结果分区,下游有 2 个 Task,那么每个 Task 会分配两个结果分区进行消费。
b:每个 Task 消费的上游分区结果数据不均,如上游有 3 个结果分区,下游有两个 Task,那么一个 Task 分配 2 个结果分区消费,另一个分配一个结果分区消费。
3)一对多连接:下游的 Task 数量多余上游的分区数,此时两种情况:
a:每个结果分区的下游消费 Task 数据量相同,如上游有两个结果分区,下游有 4 个 Task,每个结果分区被两个 Task 消费。
b:每个结果分区的下游消费 Task 数量不相同,如上游有两个结果分区,下游有 3 个 Task,那么一个结果分区分配 2 个 Task 消费,另一个结果分区分配一个 Task 消费。
-
全连接(DistributionPattern.ALL_TO_ALL)
该策略下游的 ExecutionVertex 与上 游的所有 IntermediataeResultParition 建立连接,消费其生产的数据。一般全连接的情况意味着数据在 Shuffle。