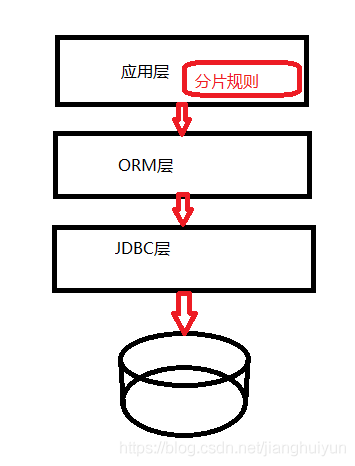
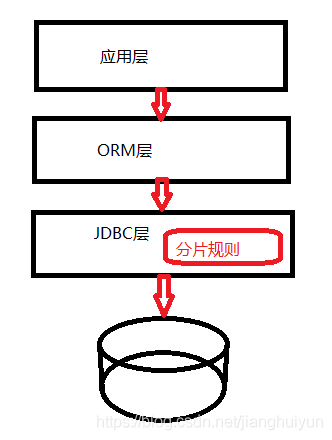
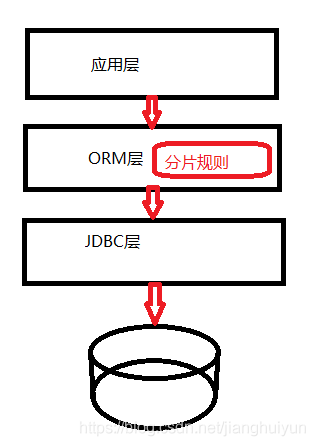
- 10月|愿你的青春不负梦想-读书笔记-01
Tracy的小书斋
本书的作者是俞敏洪,大家都很熟悉他了吧。俞敏洪老师是我行业的领头羊吧,也是我事业上的偶像。本日摘录他书中第一章中的金句:『一个人如果什么目标都没有,就会浑浑噩噩,感觉生命中缺少能量。能给我们能量的,是对未来的期待。第一件事,我始终为了进步而努力。与其追寻全世界的骏马,不如种植丰美的草原,到时骏马自然会来。第二件事,我始终有阶段性的目标。什么东西能给我能量?答案是对未来的期待。』读到这里的时候,我便
- 《投行人生》读书笔记
小蘑菇的树洞
《投行人生》----作者詹姆斯-A-朗德摩根斯坦利副主席40年的职业洞见-很短小精悍的篇幅,比较适合初入职场的新人。第一部分成功的职业生涯需要规划1.情商归为适应能力分享与协作同理心适应能力,更多的是自我意识,你有能力识别自己的情并分辨这些情绪如何影响你的思想和行为。2.对于初入职场的人的建议,细节,截止日期和数据很重要截止日期,一种有效的方法是请老板为你所有的任务进行优先级排序。和老板喝咖啡的好
- WPF中的ComboBox控件几种数据绑定的方式
互联网打工人no1
wpfc#
一、用字典给ItemsSource赋值(此绑定用的地方很多,建议熟练掌握)在XMAL中:在CS文件中privatevoidBindData(){DictionarydicItem=newDictionary();dicItem.add(1,"北京");dicItem.add(2,"上海");dicItem.add(3,"广州");cmb_list.ItemsSource=dicItem;cmb_l
- 拥有断舍离的心态,过精简生活--《断舍离》读书笔记
爱吃丸子的小樱桃
不知不觉间房间里的东西越来越多,虽然摆放整齐,但也时常会觉得空间逼仄,令人心生烦闷。抱着断舍离的态度,我开始阅读《断舍离》这本书,希望从书中能找到一些有效的方法,帮助我实现空间、物品上的断舍离。《断舍离》是日本作家山下英子通过自己的经历、思考和实践总结而成的,整体内涵也从刚开始的私人生活哲学的“断舍离”升华成了“人生实践哲学”,接着又成为每个人都能实行的“改变人生的断舍离”,从“哲学”逐渐升华成“
- SQL Server_查询某一数据库中的所有表的内容
qq_42772833
SQLServer数据库sqlserver
1.查看所有表的表名要列出CrabFarmDB数据库中的所有表(名),可以使用以下SQL语句:USECrabFarmDB;--切换到目标数据库GOSELECTTABLE_NAMEFROMINFORMATION_SCHEMA.TABLESWHERETABLE_TYPE='BASETABLE';对这段SQL脚本的解释:SELECTTABLE_NAME:这个语句的作用是从查询结果中选择TABLE_NAM
- MYSQL面试系列-04
king01299
面试mysql面试
MYSQL面试系列-0417.关于redolog和binlog的刷盘机制、redolog、undolog作用、GTID是做什么的?innodb_flush_log_at_trx_commit及sync_binlog参数意义双117.1innodb_flush_log_at_trx_commit该变量定义了InnoDB在每次事务提交时,如何处理未刷入(flush)的重做日志信息(redolog)。它
- MongoDB Oplog 窗口
喝醉酒的小白
MongoDB运维
在MongoDB中,oplog(操作日志)是一个特殊的日志系统,用于记录对数据库的所有写操作。oplog允许副本集成员(通常是从节点)应用主节点上已经执行的操作,从而保持数据的一致性。它是MongoDB副本集实现数据复制的基础。MongoDBOplog窗口oplog窗口是指在MongoDB副本集中,从节点可以用来同步数据的时间范围。这个窗口通常由以下因素决定:Oplog大小:oplog的大小是有限
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- Linux MariaDB使用OpenSSL安装SSL证书
Meta39
MySQLOracleMariaDBLinuxWindowsssllinuxmariadb
进入到证书存放目录,批量删除.pem证书警告:确保已经进入到证书存放目录find.-typef-iname\*.pem-delete查看是否安装OpenSSLopensslversion没有则安装yuminstallopensslopenssl-devel开启SSL编辑/etc/my.cnf文件(没有的话就创建,但是要注意,在/etc/my.cnf.d/server.cnf配置了datadir的,
- 读书笔记|《遇见孩子,遇见更好的自己》5
抹茶社长
为人父母意味着放弃自己的过去,不要对以往没有实现的心愿耿耿于怀,只有这样,孩子们才能做回自己。985909803.jpg孩子在与父母保持亲密的同时更需要独立,唯有这样,孩子才会成为孩子,父母才会成其为父母。有耐心的人生往往更幸福,给孩子留点余地。认识到养儿育女是对耐心的考验。为失败做好心理准备,教会孩子控制情绪。了解自己的底线,说到底线,有一点很重要,父母之所以发脾气,真正的原因往往在于他们自己,
- spring如何整合druid连接池?
惜.己
springspringjunit数据库javaidea后端xml
目录spring整合druid连接池1.新建maven项目2.新建mavenModule3.导入相关依赖4.配置log4j2.xml5.配置druid.xml1)xml中如何引入properties2)下面是配置文件6.准备jdbc.propertiesJDBC配置项解释7.配置druid8.测试spring整合druid连接池1.新建maven项目打开IDE(比如IntelliJIDEA,Ecl
- MongoDB知识概括
GeorgeLin98
持久层mongodb
MongoDB知识概括MongoDB相关概念单机部署基本常用命令索引-IndexSpirngDataMongoDB集成副本集分片集群安全认证MongoDB相关概念业务应用场景:传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。解释:“三高”需求:①Highperformance-对数据库高并发读写的需求。②HugeStorage-对海量数
- Mongodb Error: queryTxt ETIMEOUT xxxx.wwwdz.mongodb.net
佛一脚
errorreactmongodb数据库
背景每天都能遇到奇怪的问题,做个记录,以便有缘人能得到帮助!换了一台电脑开发nextjs程序。需要连接mongodb数据,对数据进行增删改查。上一台电脑好好的程序,新电脑死活连不上mongodb数据库。同一套代码,没任何修改,搞得我怀疑人生了,打开浏览器进入mongodb官网毫无问题,也能进入线上系统查看数据,网络应该是没问题。于是我尝试了一下手机热点,这次代码能正常跑起来,连接数据库了!!!是不
- 阅读《认知觉醒》读书笔记
就看看书
本周阅读了周岭的《认知觉醒开启自我改变的原动力》,启发较多,故做读书笔记一则,留待学习。全书共八章,讲述了大脑、潜意识、元认知、专注力、学习力、行动力、情绪力及成本最低的成长之道。具体描述了大脑、焦虑、耐心、模糊、感性、元认知、自控力、专注力、情绪专注、学习专注、匹配、深度、关联、体系、打卡、反馈、休息、清晰、傻瓜、行动、心智宽带、单一视角、游戏心态、早起、冥想、阅读、写作、运动等相关知识点。大脑
- GenVisR 基因组数据可视化实战(三)
11的雾
3.genCov画每个突变位点附件的coverage,跟igv有点相似。这个操作起来很复杂,但是图还是挺有用的。可以考虑。由于我的referencegenomebuild是hg38BiocManager::install(c("TxDb.Hsapiens.UCSC.hg38.knownGene","BSgenome.Hsapiens.UCSC.hg38"))library(TxDb.Hsapien
- MyBatis 详解
阿贾克斯的黎明
javamybatis
目录目录一、MyBatis是什么二、为什么使用MyBatis(一)灵活性高(二)性能优化(三)易于维护三、怎么用MyBatis(一)添加依赖(二)配置MyBatis(三)创建实体类和接口(四)使用MyBatis一、MyBatis是什么MyBatis是一个优秀的持久层框架,它支持自定义SQL、存储过程以及高级映射。MyBatis免除了几乎所有的JDBC代码以及设置参数和获取结果集的工作。它可以通过简
- wandb一直上传 解决方案
行业边缘的摸鱼怪
bug解决方案服务器linux服务器
问题描述运行带有wandb的代码时,虽然可以实现及时同步非常方便,但当设置错参数或其他原因不得不使用ctrl+C停止运行时,总会出现wandb一直上传个不停的现象,给在同一终端重新运行新的代码造成困难。解决方案运行以下代码把wandb的进程直接杀死。psaux|grepwandb|grep-vgrep|awk'{print$2}'|xargskill-9参考链接[CLI]:Ctrl+Ctokill
- You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version
努力的菜鸟~
sql数据库
YouhaveanerrorinyourSQLsyntax;checkthemanualthatcorrespondstoyourMySQLserverversionfortherightsyntaxtousenear‘IDENTIFIEDBY‘123456’WITHGRANTOPTION’atline1在mysql5.7之前GRANTALLPRIVILEGESON*.*TO'root'@'%'I
- Redis 有哪些危险命令?如何防范?
花小疯
redis缓存数据库危险命令大数据
Redis有哪些危险命令?Redis的危险命令主要有以下几个:1.keys客户端可查询出所有存在的键。2.flushdb删除Redis中当前所在数据库中的所有记录,并且此命令从不会执行失败。3.flushall删除Redis中所有数据库中的所有记录,不止是当前所在数据库,并且此命令从不会执行失败。4.config客户端可修改Redis配置。怎么禁用和重命名危险命令?看下redis.conf默认配置
- 【Java】已解决:org.springframework.jdbc.datasource.lookup.DataSourceLookupFailureException
屿小夏
java开发语言
文章目录一、分析问题背景问题背景描述出现问题的场景二、可能出错的原因三、错误代码示例四、正确代码示例五、注意事项已解决:org.springframework.jdbc.datasource.lookup.DataSourceLookupFailureException在使用Spring框架进行开发时,数据源的配置和使用是非常关键的一环。然而,有时候我们可能会遇到org.springframewo
- swing窗体打jar包后找不到图片的问题
zoyation
javajarswingclassloaderimageeclipsejava
今天打jar包遇到一个怪问题:打成jar包后双击运行没反应cmd运行有反应但出现下列问题Causedby:java.lang.ExceptionInInitializerErroratcom.zou.ui.MyDialog.init(MyDialog.java:92)atcom.zou.ui.MyDialog.(MyDialog.java:45)atcom.zou.ui.LoginDialog.(
- 2021-06-07 Do What You Are Meant To Do
春生阁
Don’tgiveupontryingtofindbalanceinyourlife.Sticktoyourpriorities.Rememberwhat’smostimportanttoyouanddoeverythingyoucantoputyourselfinapositionwhereyoucanfocusonthosepriorities,ratherthanbeingpulledbyt
- 大牛:新型电动汽车电池技术问世! 可将电池能量密度提高2倍成本降一半
38cc8b780dc0
据外媒报道,当地时间6月10日,电动汽车电池技术领导者OneDBatterySciences宣布推出一项可为下一代电动汽车电池提供动力的突破性技术——SINANODE。对于电动汽车行业而言,打造含有更多硅的电池一直是一个挑战,而SINANODE无缝集成至现有的生产工艺中,让硅纳米线与商用石墨粉末融合,将电池阳极的能量密度提高了两倍,但是将每kWh的成本降低了一半。能量密度更高可以让电池的续航更长,
- Kubernetes部署MySQL数据持久化
沫殇-MS
KubernetesMySQL数据库kubernetesmysql容器
一、安装配置NFS服务端1、安装nfs-kernel-server:sudoapt-yinstallnfs-kernel-server2、服务端创建共享目录#列出所有可用块设备的信息lsblk#格式化磁盘sudomkfs-text4/dev/sdb#创建一个目录:sudomkdir-p/data/nfs/mysql#更改目录权限:sudochown-Rnobody:nogroup/data/nfs
- 《对生命说是》读书笔记2021-5-27
Diana_58d9
静心技巧——换个视角看待问题。尝试一下这个实验,1坐在椅子上,允许自己全身心的沉浸在你最爱的问题当中,你知道头脑热爱咀嚼他们,记录当你被卷入问题时的感受。2站起来有意识地离开那张椅子,想象你现在离开了你的问题。缓缓的围绕椅子走一圈,从不同的角度看看你的问题。在房间中找一个远离问题的空间,开始仔细深入的看看这个问题,他是真实的还是你制造出来的,同样的状况对于其他人来说会是问题吗?3反复体会作战问题里
- 基于STM32的简易RTOS分析-预备知识
騏威
嵌入式
写下这篇文章的主要目的是对自己学习RTOS的历程做一个记录和总结,方便以后回忆翻看。以下内容主要来自宋岩先生翻译的《Cortex-M3权威指南》。目录一、Cortex-M3寄存器简介二、堆栈操作简介三、汇编指令简介LDR和STR指令STMDB和LDMIA指令B、BX、BL、BLX指令MRS和MSR指令四、中断简介中断响应过程简介SVC和PensSV中断简介软件中断五、汇编基础一、Cortex-M3
- 漫谈QWidget及其派生类(二)
Caiaolun
原文地址:https://blog.csdn.net/dbzhang800/article/details/6741344上一部分漫谈QWidget及其派生类(一)介绍了QWidget及其派生类,分:窗口、普通控件两种类型(其实有个Qt::SubWindow没有提,不过本系列中也没有介绍它的打算,因为我不熟)。本文接下来试图看看QLayout与窗口的几何尺寸控制。注意:本文只是试图解释,QLayo
- 精力是碎片化时代的核心竞争力——精力管理介绍
爱写作的harry
《掌控:开启不疲惫、不焦虑的人生》读书笔记精力是碎片化时代的核心竞争力精力包括身、心两个层面,包括体力、专注力和意志力等多个维度。在信息爆炸、全球化竞争的时代,谁的体力充沛,专注力和意志力更强,谁获胜的机会就更大。而要做到这些,不做精力管理,一切都是空谈。另外,人的精力是有限的,表现会有高低起伏,所以需要管理,需要规划使用。怎样才算做到了精力管理精力管理是指主动掌握自己的体力、专注力和意志力,让自
- 《女子监狱》系列,Netflix自此走上牛B之路
IMTVS_cc
文|温水排版|不二今天小编要给大家推荐的是让Netflix大方打上“原创剧集”这个牛气标签,也让HBO这些老牌电视网倒吸一口凉气的美剧《女子监狱》。剧集播出后,IMDB得分在9分徘徊,媒体评价持续走高。从收视率及口碑上来看,《女子监狱》是网飞当之无愧的王牌,自上线以来斩获金球奖等重要奖项6次、提名19次,网络话题数不胜数。《女子监狱》的英文原名是“Orangeisthenewblack”,直译过来
- linux gcc 格式,Linux下gcc与gdb简介
神奇的战士
linuxgcc格式
gcc编译器可以将C、C++等语言源程序、汇编程序编译、链接成可执行程序。gdb是GNU开发的一个Unix/Linux下强大的程序调试工具。linux下没有后缀名的概念。但gcc根据文件的后缀来区别输入文件的类别:.cC语言源代码文件.a由目标文件构成的库文件.C、.cc、.cppC++源码文件.h头文件.i经过预处理之后的C语言文件.ii经过预处理之后的C++文件.o编译后的目标文件.s汇编源码
- github中多个平台共存
jackyrong
github
在个人电脑上,如何分别链接比如oschina,github等库呢,一般教程之列的,默认
ssh链接一个托管的而已,下面讲解如何放两个文件
1) 设置用户名和邮件地址
$ git config --global user.name "xx"
$ git config --global user.email "
[email protected]"
- ip地址与整数的相互转换(javascript)
alxw4616
JavaScript
//IP转成整型
function ip2int(ip){
var num = 0;
ip = ip.split(".");
num = Number(ip[0]) * 256 * 256 * 256 + Number(ip[1]) * 256 * 256 + Number(ip[2]) * 256 + Number(ip[3]);
n
- 读书笔记-jquey+数据库+css
chengxuyuancsdn
htmljqueryoracle
1、grouping ,group by rollup, GROUP BY GROUPING SETS区别
2、$("#totalTable tbody>tr td:nth-child(" + i + ")").css({"width":tdWidth, "margin":"0px", &q
- javaSE javaEE javaME == API下载
Array_06
java
oracle下载各种API文档:
http://www.oracle.com/technetwork/java/embedded/javame/embed-me/documentation/javame-embedded-apis-2181154.html
JavaSE文档:
http://docs.oracle.com/javase/8/docs/api/
JavaEE文档:
ht
- shiro入门学习
cugfy
javaWeb框架
声明本文只适合初学者,本人也是刚接触而已,经过一段时间的研究小有收获,特来分享下希望和大家互相交流学习。
首先配置我们的web.xml代码如下,固定格式,记死就成
<filter>
<filter-name>shiroFilter</filter-name>
&nbs
- Array添加删除方法
357029540
js
刚才做项目前台删除数组的固定下标值时,删除得不是很完整,所以在网上查了下,发现一个不错的方法,也提供给需要的同学。
//给数组添加删除
Array.prototype.del = function(n){
- navigation bar 更改颜色
张亚雄
IO
今天郁闷了一下午,就因为objective-c默认语言是英文,我写的中文全是一些乱七八糟的样子,到不是乱码,但是,前两个自字是粗体,后两个字正常体,这可郁闷死我了,问了问大牛,人家告诉我说更改一下字体就好啦,比如改成黑体,哇塞,茅塞顿开。
翻书看,发现,书上有介绍怎么更改表格中文字字体的,代码如下
- unicode转换成中文
adminjun
unicode编码转换
在Java程序中总会出现\u6b22\u8fce\u63d0\u4ea4\u5fae\u535a\u641c\u7d22\u4f7f\u7528\u53cd\u9988\uff0c\u8bf7\u76f4\u63a5这个的字符,这是unicode编码,使用时有时候不会自动转换成中文就需要自己转换了使用下面的方法转换一下即可。
/**
* unicode 转换成 中文
- 一站式 Java Web 框架 firefly
aijuans
Java Web
Firefly是一个高性能一站式Web框架。 涵盖了web开发的主要技术栈。 包含Template engine、IOC、MVC framework、HTTP Server、Common tools、Log、Json parser等模块。
firefly-2.0_07修复了模版压缩对javascript单行注释的影响,并新增了自定义错误页面功能。
更新日志:
增加自定义系统错误页面功能
- 设计模式——单例模式
ayaoxinchao
设计模式
定义
Java中单例模式定义:“一个类有且仅有一个实例,并且自行实例化向整个系统提供。”
分析
从定义中可以看出单例的要点有三个:一是某个类只能有一个实例;二是必须自行创建这个实例;三是必须自行向系统提供这个实例。
&nb
- Javascript 多浏览器兼容性问题及解决方案
BigBird2012
JavaScript
不论是网站应用还是学习js,大家很注重ie与firefox等浏览器的兼容性问题,毕竟这两中浏览器是占了绝大多数。
一、document.formName.item(”itemName”) 问题
问题说明:IE下,可以使用 document.formName.item(”itemName”) 或 document.formName.elements ["elementName&quo
- JUnit-4.11使用报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing错误
bijian1013
junit4.11单元测试
下载了最新的JUnit版本,是4.11,结果尝试使用发现总是报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing这样的错误,上网查了一下,一般的解决方案是,换一个低一点的版本就好了。还有人说,是缺少hamcrest的包。去官网看了一下,如下发现:
- [Zookeeper学习笔记之二]Zookeeper部署脚本
bit1129
zookeeper
Zookeeper伪分布式安装脚本(此脚本在一台机器上创建Zookeeper三个进程,即创建具有三个节点的Zookeeper集群。这个脚本和zookeeper的tar包放在同一个目录下,脚本中指定的名字是zookeeper的3.4.6版本,需要根据实际情况修改):
#!/bin/bash
#!!!Change the name!!!
#The zookeepe
- 【Spark八十】Spark RDD API二
bit1129
spark
coGroup
package spark.examples.rddapi
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object CoGroupTest_05 {
def main(args: Array[String]) {
v
- Linux中编译apache服务器modules文件夹缺少模块(.so)的问题
ronin47
modules
在modules目录中只有httpd.exp,那些so文件呢?
我尝试在fedora core 3中安装apache 2. 当我解压了apache 2.0.54后使用configure工具并且加入了 --enable-so 或者 --enable-modules=so (两个我都试过了)
去make并且make install了。我希望在/apache2/modules/目录里有各种模块,
- Java基础-克隆
BrokenDreams
java基础
Java中怎么拷贝一个对象呢?可以通过调用这个对象类型的构造器构造一个新对象,然后将要拷贝对象的属性设置到新对象里面。Java中也有另一种不通过构造器来拷贝对象的方式,这种方式称为
克隆。
Java提供了java.lang.
- 读《研磨设计模式》-代码笔记-适配器模式-Adapter
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 适配器模式解决的主要问题是,现有的方法接口与客户要求的方法接口不一致
* 可以这样想,我们要写这样一个类(Adapter):
* 1.这个类要符合客户的要求 ---> 那显然要
- HDR图像PS教程集锦&心得
cherishLC
PS
HDR是指高动态范围的图像,主要原理为提高图像的局部对比度。
软件有photomatix和nik hdr efex。
一、教程
叶明在知乎上的回答:
http://www.zhihu.com/question/27418267/answer/37317792
大意是修完后直方图最好是等值直方图,方法是HDR软件调一遍,再结合不透明度和蒙版细调。
二、心得
1、去除阴影部分的
- maven-3.3.3 mvn archetype 列表
crabdave
ArcheType
maven-3.3.3 mvn archetype 列表
可以参考最新的:http://repo1.maven.org/maven2/archetype-catalog.xml
[INFO] Scanning for projects...
[INFO]
- linux shell 中文件编码查看及转换方法
daizj
shell中文乱码vim文件编码
一、查看文件编码。
在打开文件的时候输入:set fileencoding
即可显示文件编码格式。
二、文件编码转换
1、在Vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式
&
- MySQL--binlog日志恢复数据
dcj3sjt126com
binlog
恢复数据的重要命令如下 mysql> flush logs; 默认的日志是mysql-bin.000001,现在刷新了重新开启一个就多了一个mysql-bin.000002
- 数据库中数据表数据迁移方法
dcj3sjt126com
sql
刚开始想想好像挺麻烦的,后来找到一种方法了,就SQL中的 INSERT 语句,不过内容是现从另外的表中查出来的,其实就是 MySQL中INSERT INTO SELECT的使用
下面看看如何使用
语法:MySQL中INSERT INTO SELECT的使用
1. 语法介绍
有三张表a、b、c,现在需要从表b
- Java反转字符串
dyy_gusi
java反转字符串
前几天看见一篇文章,说使用Java能用几种方式反转一个字符串。首先要明白什么叫反转字符串,就是将一个字符串到过来啦,比如"倒过来念的是小狗"反转过来就是”狗小是的念来过倒“。接下来就把自己能想到的所有方式记录下来了。
1、第一个念头就是直接使用String类的反转方法,对不起,这样是不行的,因为Stri
- UI设计中我们为什么需要设计动效
gcq511120594
UIlinux
随着国际大品牌苹果和谷歌的引领,最近越来越多的国内公司开始关注动效设计了,越来越多的团队已经意识到动效在产品用户体验中的重要性了,更多的UI设计师们也开始投身动效设计领域。
但是说到底,我们到底为什么需要动效设计?或者说我们到底需要什么样的动效?做动效设计也有段时间了,于是尝试用一些案例,从产品本身出发来说说我所思考的动效设计。
一、加强体验舒适度
嗯,就是让用户更加爽更加爽的用
- JBOSS服务部署端口冲突问题
HogwartsRow
java应用服务器jbossserverEJB3
服务端口冲突问题的解决方法,一般修改如下三个文件中的部分端口就可以了。
1、jboss5/server/default/conf/bindingservice.beans/META-INF/bindings-jboss-beans.xml
2、./server/default/deploy/jbossweb.sar/server.xml
3、.
- 第三章 Redis/SSDB+Twemproxy安装与使用
jinnianshilongnian
ssdbreidstwemproxy
目前对于互联网公司不使用Redis的很少,Redis不仅仅可以作为key-value缓存,而且提供了丰富的数据结果如set、list、map等,可以实现很多复杂的功能;但是Redis本身主要用作内存缓存,不适合做持久化存储,因此目前有如SSDB、ARDB等,还有如京东的JIMDB,它们都支持Redis协议,可以支持Redis客户端直接访问;而这些持久化存储大多数使用了如LevelDB、RocksD
- ZooKeeper原理及使用
liyonghui160com
ZooKeeper是Hadoop Ecosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordination)服务,与之对应的Google的类似服务叫Chubby。今天这篇文章分为三个部分来介绍ZooKeeper,第一部分介绍ZooKeeper的基本原理,第二部分介绍ZooKeeper
- 程序员解决问题的60个策略
pda158
框架工作单元测试
根本的指导方针
1. 首先写代码的时候最好不要有缺陷。最好的修复方法就是让 bug 胎死腹中。
良好的单元测试
强制数据库约束
使用输入验证框架
避免未实现的“else”条件
在应用到主程序之前知道如何在孤立的情况下使用
日志
2. print 语句。往往额外输出个一两行将有助于隔离问题。
3. 切换至详细的日志记录。详细的日
- Create the Google Play Account
sillycat
Google
Create the Google Play Account
Having a Google account, pay 25$, then you get your google developer account.
References:
http://developer.android.com/distribute/googleplay/start.html
https://p
- JSP三大指令
vikingwei
jsp
JSP三大指令
一个jsp页面中,可以有0~N个指令的定义!
1. page --> 最复杂:<%@page language="java" info="xxx"...%>
* pageEncoding和contentType:
> pageEncoding:它