Flink项目最佳实践(一):初始化项目
文章目录
-
-
- 一、前提
- 二、创建项目
- 三、pom.xml 解析
-
- 1. dependencies
- 2. build
- 3. profile
- 4. scope 类型参考
- 四、总结
- 五、参考:
-
一、前提
Maven >= 3.0.4 和 Java 8.x,
使用 IDEA 来开发项目。
二、创建项目
$ mkdir -p /data/datacenter;
$ cd /data/datacenter;
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.9.1
...
Define value for property 'groupId': org.demo
Define value for property 'artifactId': flink
Define value for property 'version' 1.0-SNAPSHOT: :<回车>
Define value for property 'package' org.demo: : <回车>
Confirm properties configuration:
groupId: org.demo
artifactId: flink
version: 1.0-SNAPSHOT
package: org.demo.flink
Y: : Y
以交互式的方式要求填写项目的 groupId,artifactId 和 package
这里以 flink.demo.org 示例,
$ mv flink flink.demo.org
$ tree flink.demo.org/
flink.demo.org/
├── pom.xml
└── src
└── main
├── resources
│ └── log4j.properties
└── scala
└── org
└── demo
└── flink
├── BatchJob.scala
└── StreamingJob.scala
BatchJob.scala 和 StreamingJob.scala 分别是批处理任务和流处理任务的示例。
现在把项目导入到 IntelliJ IDEA;
三、pom.xml 解析
示例中的 pom 是一个非常好的实践, pom.xml 分三大段
<dependencies>dependencies>
<build>build>
<profiles>profiles>
1. dependencies
Flink 项目,必定需要依赖 Flink 类库,Flink 应用至少需要依赖 Flink APIs。许多应用还会额外依赖连接器类库(比如 Kafka、Cassandra 等)。 当用户运行 Flink 应用时(无论是在 IDE 环境下进行测试,还是部署在分布式环境下),运行时类库都必须可用。
- Flink 核心依赖
此类依赖,我们应对设置 依赖的scope 为 provided,以减小jar包大小,比如:
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
注意:项目在 IDEA 调试时会出现
no such class等错误而无法运行, 需要对开发环境进行另外配置,在下面第三点
profile
- 用户应用程序依赖
比如 json 解析,各类组件的连接器则必须要打包到 jar 中,比如:
<dependency>
<groupId>com.google.code.gsongroupId>
<artifactId>gsonartifactId>
<version>2.8.5version>
dependency>
2. build
示例里 build 区块构建带有依赖的应用 jar 包, 如果使用IntelliJ IDEA,则可以把 Eclipse 相关配置删除;
另强烈建议在 build 节点增加如下配置,方便测试和线上配置文件环境隔离;
<build>
<plugins>
....
plugins>
<resources>
<resource>
<directory>src/main/resources_${profileActive}directory>
<includes>
<include>**/*include>
includes>
resource>
resources>
build>
3. profile
profile 是 maven 项目常用的测试环境与生成环境配置隔离工具,修改配置如下:
<profiles>
<profile>
<id>prodid>
<activation>
<activeByDefault>trueactiveByDefault>
activation>
<properties>
<profileActive>prodprofileActive>
properties>
profile>
<profile>
<id>testid>
<properties>
<profileActive>testprofileActive>
properties>
profile>
<profile>
<id>devid>
<activation>
<property>
<name>idea.versionname>
property>
activation>
<properties>
<profileActive>testprofileActive>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>compilescope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>compilescope>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
<scope>compilescope>
dependency>
dependencies>
profile>
profiles>
这是就能看到如下图的maven profiles 中出现了 dev prod test, pom.xml 配置文件中可以使用 ${profileActive} 来表示。
特别注意: 我这里 dev 的profileActive 写的是 test, 因为对于一般大数据开发来说,不一定有 dev 环境,建议直接使用测试集群配置即可。
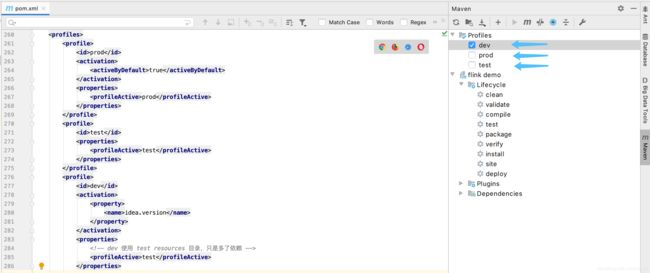
profile 节点中也有一部分 dependencies, 这里就是第一点 dependiences 说了开发环境的配置,
4. scope 类型参考
compile
默认scope为compile,表示为当前依赖参与项目的编译、测试和运行阶段,属于强依赖。打包之时,会达到包里去。
test
该依赖仅仅参与测试相关的内容,包括测试用例的编译和执行,比如定性的Junit。
runtime
依赖仅参与运行周期中的使用。一般这种类库都是接口与实现相分离的类库,比如JDBC类库,在编译之时仅依赖相关的接口,在具体的运行之时,才需要具体的mysql、oracle等等数据的驱动程序。 此类的驱动都是为runtime的类库。
provided
该依赖在打包过程中,不需要打进去,这个由运行的环境来提供,比如tomcat或者基础类库等等,事实上,该依赖可以参与编译、测试和运行等周期,与compile等同。区别在于打包阶段进行了exclude操作。
system
使用上与provided相同,不同之处在于该依赖不从maven仓库中提取,而是从本地文件系统中提取,其会参照systemPath的属性进行提取依赖。
import
这个是maven2.0.9版本后出的属性,import只能在dependencyManagement的中使用,能解决maven单继承问题,import依赖关系实际上并不参与限制依赖关系的传递性。
四、总结
绝大部分软件工程都需要通过修改配置文件的方式来区分「开发」、「测试」、「生产」环境,但很多项目的配置往往不甚明白。我个人见解:
- 测试环境配置必须提交到版本控制中(比如:git)
- 更改配置文件类型必须非常简单,并且不会导致代码变动(比如:git status 不会出现文件变更)
本文介绍项目代码框架,我认为已经满足上述需求。
五、参考:
-
scala-flink 项目 quickstart
-
flink 项目依赖
-
https://github.com/fencex/flink.demo.org

下一篇:Flink项目最佳实践(二):第一个实时模拟ETL任务
欢迎订阅本专栏 :)
记住:
能力越大
薪资越高