浅谈数仓建模
1、数据仓库建模的目的
大家知道为什么要进行数据仓库建模?
大数据的数仓建模是通过建模的方法更好的组织、存储数据,以便在 性能、成本、效率和数据质量之间找到最佳平衡点。
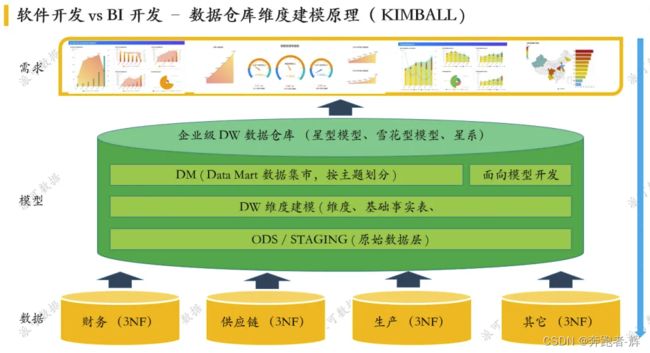
一般主要从下面四点考虑
访问性能:能够快速查询所需的数据,减少数据I/O;
数据成本:减少不必要的数据冗余,实现计算结果数据复用,降低大数 据系统中的存储成本和计算成本;
使用效率:改善用户应用体验,提高使用数据的效率;
数据质量:改善数据统计口径的不一致性,减少数据计算错误 的可能性,提供高质量的、一致的数据访问平台;
2、实体关系(E-R)模型
实体建模并不是一种常见的建模方法,实体关系模型将复杂的数据抽象为两个概念——实体和关系。实体表示一个对象,例如医生、患者,关系是指两个实体之间的关系,例如医生和患者之间的关系。
3、 范式建模
范式建模主要解决的是关系型数据的数据存储,以消除“数据冗余”为目标。目前,关系型数据库大多采用的是三范式建模法。
3.1 定义
从关系型数据库的角度出发,结合了业务系统的数据模型。
范式可以理解为设计一张数据表的表结构,符合的标准级别、规范和要求。
3.2 优点
采用范式,可以降低数据的冗余性。
为什么要降低数据冗余性?
(1)十几年前,磁盘很贵,为了减少磁盘存储;
(2)以前没有分布式系统,都是单机,只能增加磁盘,磁盘个数也是有限的;
(3)一次修改,需要修改多个表,很难保证数据一致性。
3.3 缺点
范式的缺点是获取数据时,需要通过join拼接出最后的数据。
3.4 分类
目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
1NF核心原则:属性不可切割
2NF核心原则:不能存在部分函数依赖
3NF核心原则:不能存在传递函数依赖
4、关系建模与维度建模
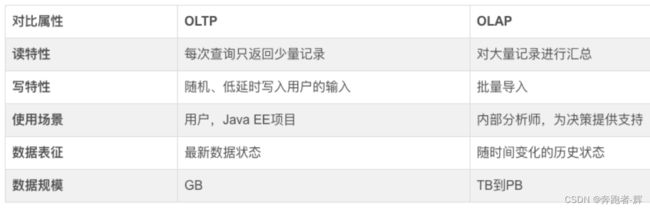
当今的数据处理大致可以分成两大类:联机事务处理OLTP、联机分析处理OLAP。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。二者的主要区别对比如下表所示。
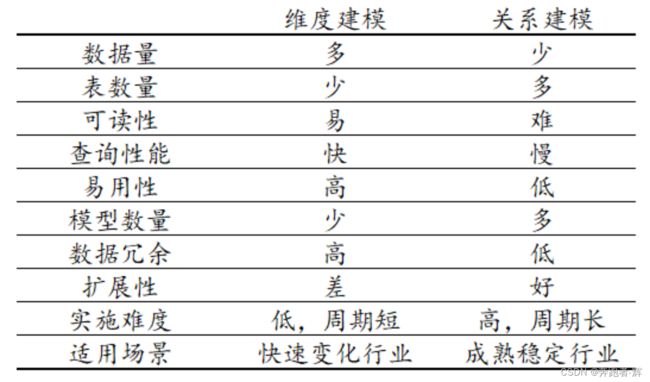
4.1 关系建模
关系模型如图所示,严格遵循第三范式(3NF),从图中可以看出,较为松散、零碎,物理表数量多,而数据冗余程度低。
由于数据分布于众多的表中,这些数据可以更为灵活地被应用,功能性较强。关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
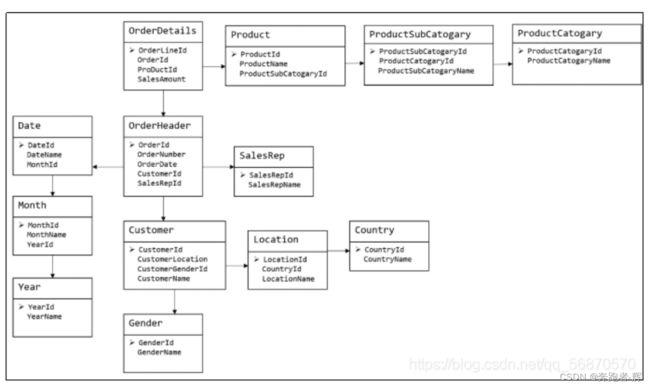
4.2 维度建模
维度模型如图所示,主要应用于OLAP系统中,通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。
关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以通常我们采用维度模型建模,把相关各种表整理成两种:事实表和维度表两种。
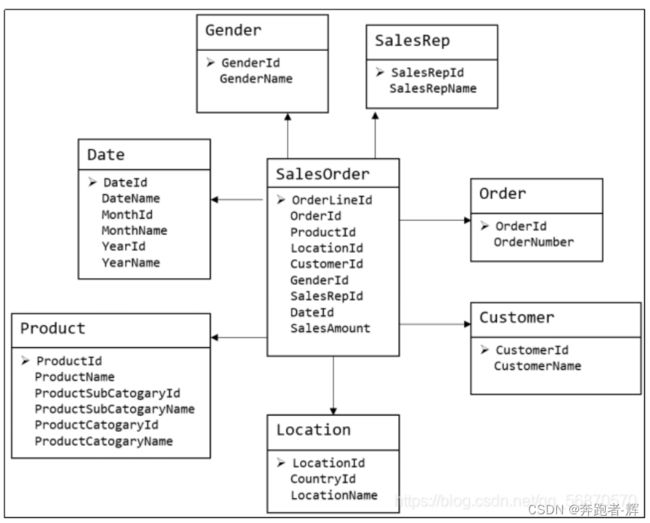
4.3 维度建模分类
Kimball 最先提出维度建模这一概念。其最简单的描述就是,按照事实表,维表来构建数据仓库,数据集市。
维度建模是面向分析的,为了提高查询效率可以增加数据冗余,反规范化的设计技术。
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型等。
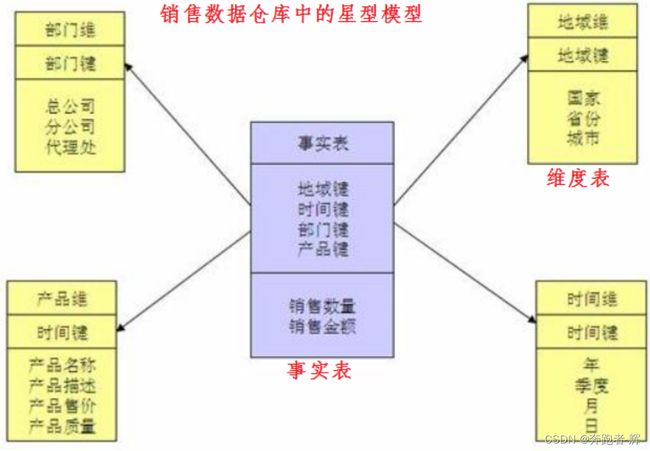
星型模型
1张事实表,维度只有1层,维度表之间没有关联,当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型。星形模型是最简单,也是最常用的模型。
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余; 如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在数据冗余。
如销售数据仓库中的星型模型:
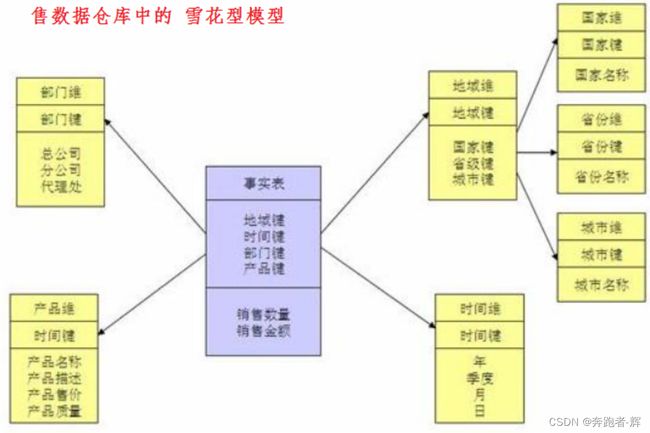
雪花模型
1张事实表,维度会涉及多级,维度表之间有关联,通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。
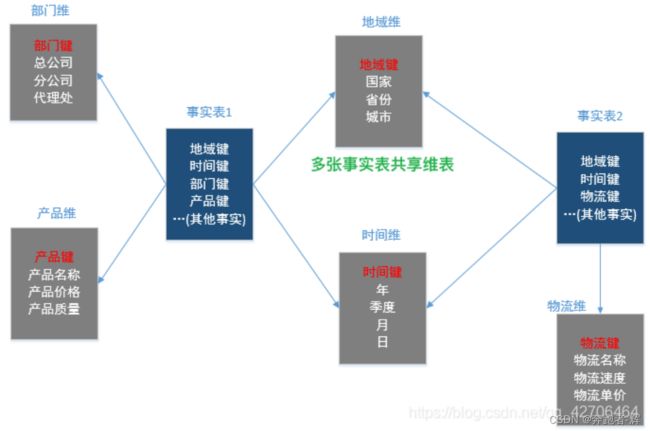
星座模型
星座模式是基于多张事实表,并且共享维度表信息,这种模型往往应用于数据关系比星型模型和雪花模型更复杂的场合。
星型模型 vs 雪花模型
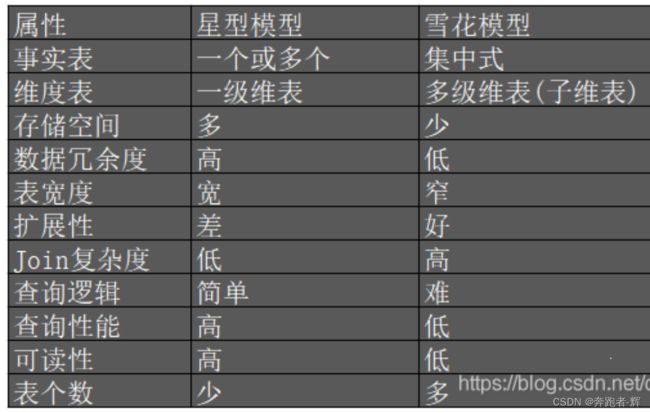
5、使用方面的选择
星型模型因为数据的冗余,所以很多统计查询不需要做外部的连接(不需要太多join),因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。而且在相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。
- 如果在冗余[数据重复]可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
- 可以考虑是不是能结合两者的优点参与设计,以此达到设计的最优化目的。
其它建模方式
Data Vault模型、Anchor模型,暂时还没有应用过。
相关建模工具
Erwin、Powerdesigner、Visio、Drawio等,路过的朋友请多多指教哈。
推荐阅读以往类似博文:
数仓分层建设_奔跑者-辉的博客-CSDN博客