神经网络 width_人工智能Keras CNN卷积神经网络的图片识别模型训练
CNN卷积神经网络是人工智能的开端,CNN卷积神经网络让计算机能够认识图片,文字,甚至音频与视频。CNN卷积神经网络的基础知识,可以参考:CNN卷积神经网络
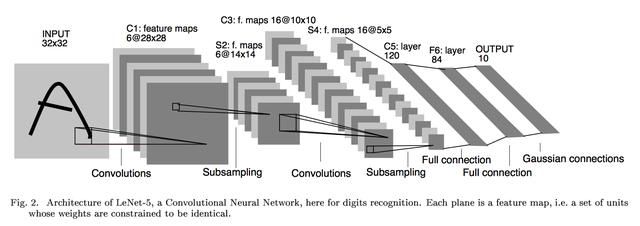
LetNet体系结构是卷积神经网络的“第一个图像分类器”。最初设计用于对手写数字进行分类,上期文章我们分享了如何使用keras来进行手写数字的神经网络搭建:Keras人工智能神经网络 Classifier 分类 神经网络搭建
我们也可以轻松地将其扩展到其他类型的图像上,本期使用小雪人的照片,来让神经网络识别雪人
雪人的图片大家可以到网络上自行下载,当然也可以使用爬虫技术来下载
搭建keras神经网络识别图片
from keras.models import Sequentialfrom keras.layers.convolutional import Conv2Dfrom keras.layers.convolutional import MaxPooling2Dfrom keras.layers.core import Activationfrom keras.layers.core import Flattenfrom keras.layers.core import Densefrom keras import backend as K首先导入需要的模块,建立一个神经网络以便后期使用,在一个单独的文件中,命名此神经网络类(lenet.py)
class LeNet:@staticmethoddef build(width, height, depth, classes):# 使用Sequential()初始化modelmodel = Sequential()inputShape = (height, width, depth) #tensorflow默认设置 #宽度 :输入图像的宽度 #高度 :输入图像的高度 #深度 :输入图像中的频道数(1个 对于灰度单通道图像, 3 标准RGB图像) # 若是其他的(Theano),则使用((depth, height, width)if K.image_data_format() == "channels_first":inputShape = (depth, height, width)#建立卷积神经网络 =>然后是 RELU => 然后是max pooling(跟前期分享的tensorflow教程类似)model.add(Conv2D(20, (5, 5), padding="same",input_shape=inputShape))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))# 建立卷积神经网络 =>然后是 RELU => 然后是max pooling(第二层)model.add(Conv2D(50, (5, 5), padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))# 增加全连接层model.add(Flatten())model.add(Dense(500))model.add(Activation("relu"))# softmax classifier 来进行神经网络的分类model.add(Dense(classes))model.add(Activation("softmax"))# return the modelreturn model训练keras神经网络
以上建立了keras 的神经网络模型,我们就使用预先下载好的图片来训练神经模型
建立一个train.py文件,插入如下代码,来训练神经网络模型(图片数据里面分成如下2类)
- snowman #我们训练的图片
- notsnowman 增加非雪人图片的训练
import matplotlibmatplotlib.use("Agg")from keras.preprocessing.image import ImageDataGeneratorfrom keras.optimizers import Adamfrom sklearn.model_selection import train_test_splitfrom keras.preprocessing.image import img_to_arrayfrom keras.utils import to_categoricalfrom lenet import LeNetfrom imutils import pathsimport matplotlib.pyplot as pltimport numpy as npimport randomimport cv2import os初始化参数
EPOCHS = 25 #学习的步数INIT_LR = 1e-3# 学习效率BS = 32# 每步学习的个数data = []# 存放图片数据labels = []# 存放图片标签imagePaths = sorted(list(paths.list_images("dataset")))# 遍历所有的图片random.seed(42)random.shuffle(imagePaths) # 打乱图片顺序初始化参数完成后,需要把所有的图片加载,进行图片数据的整理
for imagePath in imagePaths: # 加载图片 image = cv2.imread(imagePath) image = cv2.resize(image, (28, 28)) # resize 到28*28 LeNet所需的空间尺寸 image = img_to_array(image) # 图片转换成array data.append(image) # 保存图片数据 label = imagePath.split(os.path.sep)[-2] #获取图片标签 label = 1 if label == "snowman" else 0 labels.append(label) # 获取图片标签预先处理图片
# 把图片数据变成【0.1】data = np.array(data, dtype="float") / 255.0labels = np.array(labels)# 设置测试数据与训练数据#使用75%的数据将数据划分为训练和测试#用于训练的数据,其余25%用于测试(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, random_state=42)# 标签转换成向量trainY = to_categorical(trainY, num_classes=2)testY = to_categorical(testY, num_classes=2)# 创建一个图像生成器对象,该对象在图像数据集上执行随机旋转,平移,翻转,修剪和剪切。#这使我们可以使用较小的数据集,但仍然可以获得较高的结果aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode="nearest")建立神经网络,进行神经网络训练
#建立modelmodel = LeNet.build(width=28, height=28, depth=3, classes=2)opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])# 训练神经网络H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS), validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS, epochs=EPOCHS, verbose=1)神经网络训练完成后,对神经网络训练的结果进行保存,以便后期使用预训练模型进行图片识别
保存模型,显示训练结果
model.save("lenet.model") # 保存模型# 显示结果plt.style.use("ggplot")plt.figure()N = EPOCHSplt.plot(np.arange(0, N), H.history["loss"], label="train_loss")plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")plt.plot(np.arange(0, N), H.history["acc"], label="train_acc")plt.plot(np.arange(0, N), H.history["val_acc"], label="val_acc")plt.title("Training Loss and Accuracy on snowman/Notsnowman")plt.xlabel("Epoch #")plt.ylabel("Loss/Accuracy")plt.legend(loc="lower left")plt.savefig("plot1.JPG")从训练结果可以看出,loss越来越小,精度越来越高,表明我们的神经网络模型是完全ok。
若想得到更好的训练数据,当然是使用大量的数据进行训练

以上便是我们训练的神经网络模型,下期我们使用预训练模型,对图片进行识别
