基于Keras的深度学习(二)——LeNet的搭建与训练
这里写自定义目录标题
- 基于Keras的深度学习(二)——LeNet的搭建与训练
- Keras功能介绍
-
- 1.卷积
- 2.激活函数
- 3.池化
- 4.Flatten
- 5.全连接层
- 搭建LeNet
-
- 1.模型的搭建
- 2.数据获取及预处理
- 3.训练
- 4.评估模型
基于Keras的深度学习(二)——LeNet的搭建与训练
LeNet是一种用于手写体字符识别的非常高效的卷积神经网络。网络虽然很小,但是它包含了深度学习的基本模块:卷积层,池化层,全连接层。也是其他深度学习模型的基础。
关于LeNet的介绍可以参考链接:LeNet
我们一边看LeNet,一边来学习一下如何使用Keras搭建一个简单的DCNN网络。
Keras功能介绍
1.卷积
关于卷积的理解,可以参考链接:卷积层
本文主要介绍Keras实现卷积的方式,以及需要注意的参数
keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
2D 卷积层 (例如对图像的空间卷积)。
该层创建了一个卷积核, 该卷积核对层输入进行卷积, 以生成输出张量。 如果 use_bias 为 True, 则会创建一个偏置向量并将其添加到输出中。 最后,如果 activation 不是 None,它也会应用于输出。
当使用该层作为模型第一层时,需要提供 input_shape 参数 (整数元组,不包含样本表示的轴),例如, input_shape=(128, 128, 3) 表示 128x128 RGB 图像, 在 data_format=“channels_last” 时。
参数
filters: 整数,输出空间的维度 (即卷积中滤波器的输出数量)。
kernel_size: 一个整数,或者 2 个整数表示的元组或列表, 指明 2D 卷积窗口的宽度和高度。 可以是一个整数,为所有空间维度指定相同的值。
strides: 一个整数,或者 2 个整数表示的元组或列表, 指明卷积沿宽度和高度方向的步长。 可以是一个整数,为所有空间维度指定相同的值。 指定任何 stride 值 != 1 与指定 dilation_rate 值 != 1 两者不兼容。
padding: “valid” 或 “same” (大小写敏感)。
data_format: 字符串, channels_last (默认) 或 channels_first 之一,表示输入中维度的顺序。
channels_last 对应输入尺寸为 (batch, height, width, channels), channels_first 对应输入尺寸为 (batch, channels, height, width)。 它默认为从 Keras 配置文件 ~/.keras/keras.json 中 找到的image_data_format 值。 如果你从未设置它,将使用 channels_last。
dilation_rate: 一个整数或 2 个整数的元组或列表, 指定膨胀卷积的膨胀率。 可以是一个整数,为所有空间维度指定相同的值。 当前,指定任何 dilation_rate 值 != 1 与 指定 stride 值 != 1 两者不兼容。
activation: 要使用的激活函数 (详见 activations)。 如果你不指定,则不使用激活函数 (即线性激活: a(x) = x)。
use_bias: 布尔值,该层是否使用偏置向量。
kernel_initializer: kernel 权值矩阵的初始化器 (详见 initializers)。
bias_initializer: 偏置向量的初始化器 (详见 initializers)。
kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 (详见 regularizer)。
bias_regularizer: 运用到偏置向量的正则化函数 (详见 regularizer)。
activity_regularizer: 运用到层输出(它的激活值)的正则化函数 (详见 regularizer)。
kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见 constraints)。
bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
输入尺寸
如果 data_format=‘channels_first’, 输入 4D 张量,尺寸为 (samples, channels, rows, cols)。
如果 data_format=‘channels_last’, 输入 4D 张量,尺寸为 (samples, rows, cols, channels)。
输出尺寸
如果 data_format=‘channels_first’, 输出 4D 张量,尺寸为 (samples, filters, new_rows, new_cols)。
如果 data_format=‘channels_last’, 输出 4D 张量,尺寸为 (samples, new_rows, new_cols, filters)。
由于填充的原因, rows 和 cols 值可能已更改。
2.激活函数
激活函数可以通过设置单独的激活层实现,也可以在构造层对象时通过传递 activation 参数实现:
from keras.layers import Activation, Dense
model.add(Dense(64))
model.add(Activation('tanh'))
等价于:
model.add(Dense(64, activation='tanh'))
你也可以通过传递一个逐元素运算的 Theano/TensorFlow/CNTK 函数来作为激活函数:
from keras import backend as K
model.add(Dense(64, activation=K.tanh))
model.add(Activation(K.tanh))
3.池化
关于池化层的理解,可以参考链接:池化
加下来介绍一下Keras中池化的实现方法,主要介绍一下图像数据使用的MaxPooling2D:
MaxPooling2D
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
参数
pool_size: 整数,或者 2 个整数表示的元组, 沿(垂直,水平)方向缩小比例的因数。 (2,2)会把输入张量的两个维度都缩小一半。 如果只使用一个整数,那么两个维度都会使用同样的窗口长度。
strides: 整数,2 个整数表示的元组,或者是 None。 表示步长值。 如果是 None,那么默认值是 pool_size。
padding: “valid” 或者 “same” (区分大小写)。
data_format: 字符串,channels_last (默认)或 channels_first 之一。 表示输入各维度的顺序。 channels_last 代表尺寸是 (batch, height, width, channels) 的输入张量, 而 channels_first 代表尺寸是 (batch, channels, height, width) 的输入张量。 默认值根据 Keras 配置文件 ~/.keras/keras.json 中的 image_data_format 值来设置。 如果还没有设置过,那么默认值就是 “channels_last”。
输入尺寸
如果 data_format=‘channels_last’: 尺寸是 (batch_size, rows, cols, channels) 的 4D 张量
如果 data_format=‘channels_first’: 尺寸是 (batch_size, channels, rows, cols) 的 4D 张量
输出尺寸
如果 data_format=‘channels_last’: 尺寸是 (batch_size, pooled_rows, pooled_cols, channels) 的 4D 张量
如果 data_format=‘channels_first’: 尺寸是 (batch_size, channels, pooled_rows, pooled_cols) 的 4D 张量
4.Flatten
Flatten层的实现在Keras.layers.core.Flatten()类中。
作用:
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
keras.layers.Flatten(data_format=None)
参数
data_format:一个字符串,其值为 channels_last(默认值)或者 channels_first。它表明输入的维度的顺序。此参数的目的是当模型从一种数据格式切换到另一种数据格式时保留权重顺序。channels_last 对应着尺寸为 (batch, …, channels) 的输入,而 channels_first 对应着尺寸为 (batch, channels, …) 的输入。默认为 image_data_format 的值,你可以在 Keras 的配置文件 ~/.keras/keras.json 中找到它。如果你从未设置过它,那么它将是 channels_last
例如:
model.add(Flatten())
model.add(Dense(500))
model.add(Activation('relu'))
5.全连接层
全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
就是你常用的的全连接层。
例
# 作为 Sequential 模型的第一层
model = Sequential()
model.add(Dense(32, input_shape=(16,)))
# 现在模型就会以尺寸为 (*, 16) 的数组作为输入,
# 其输出数组的尺寸为 (*, 32)
# 在第一层之后,你就不再需要指定输入的尺寸了:
model.add(Dense(32))
参数
units: 正整数,输出空间维度。
activation: 激活函数 (详见 activations)。 若不指定,则不使用激活函数 (即,「线性」激活: a(x) = x)。
use_bias: 布尔值,该层是否使用偏置向量。
kernel_initializer: kernel 权值矩阵的初始化器 (详见 initializers)。
bias_initializer: 偏置向量的初始化器 (see initializers).
kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 (详见 regularizer)。
bias_regularizer: 运用到偏置向的的正则化函数 (详见 regularizer)。
activity_regularizer: 运用到层的输出的正则化函数 (它的 “activation”)。 (详见 regularizer)。
kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见 constraints)。
bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
输入尺寸
nD 张量,尺寸: (batch_size, …, input_dim)。 最常见的情况是一个尺寸为 (batch_size, input_dim) 的 2D 输入。
输出尺寸
nD 张量,尺寸: (batch_size, …, units)。 例如,对于尺寸为 (batch_size, input_dim) 的 2D 输入, 输出的尺寸为 (batch_size, units)。
搭建LeNet
1.模型的搭建
# model
NB_classes = 10
optimizer = Adam()
dropout = 0.3
INPUT_SHAPE = (1,28, 28)
# 选择channels_first:返回(3,256,256)
# 选择channels_last:返回(256,256,3)
model = Sequential()
# CONN->RELU->POOL
model.add(Conv2D(20, kernel_size=5, input_shape=INPUT_SHAPE, padding='same',data_format='channels_first'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), data_format='channels_first'))
# CONN->RELU->POOL
model.add(Conv2D(50, kernel_size=5, padding='same',data_format='channels_first'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), data_format='channels_first'))
# Flatten -> Dense ->RELU
# Flatten层用来将输入“压平”,把多为的输入一维化,作为卷积层待全连接层的过渡
model.add(Flatten())
model.add(Dense(500))
model.add(Activation('relu'))
# Dense->softmax
model.add(Dense(NB_classes))
model.add(Activation('softmax'))
model.summary()
# 选择适合的损失函数、目标函数、评价函数
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
plot_model(model, to_file='./2-Lenet-model_1.png', show_shapes=True)
经过上面模型的搭建我们可以得到如下的模型结构
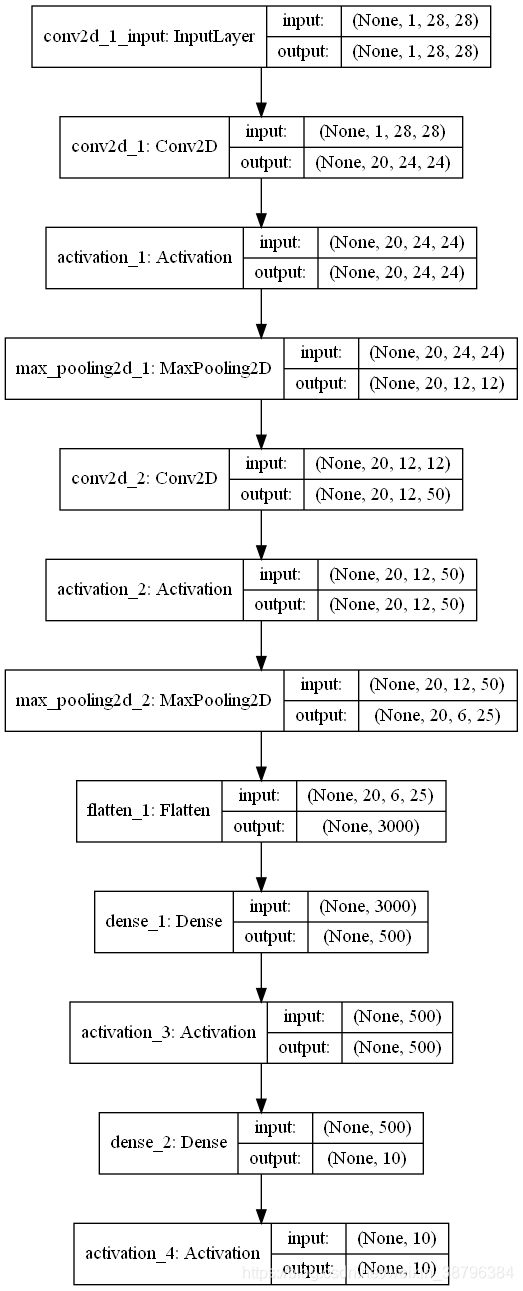
2.数据获取及预处理
# data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# we need a 60K x [1 x 28 x 28] shape as input to the CONVNET
X_train = X_train[:, np.newaxis, :, :]
X_test = X_test[:, np.newaxis, :, :]
# nomalize
X_train /= 255
X_test /= 255
y_train = np_utils.to_categorical(y_train, NB_classes)
y_test = np_utils.to_categorical(y_test, NB_classes)
3.训练
使用model.fit训练模型
# train
batch_size = 128
NB_epoch = 20
history = model.fit(X_train, y_train, batch_size=batch_size, epochs=NB_epoch, validation_split=0.2, verbose=1)
score = model.evaluate(X_test, y_test, batch_size=batch_size, verbose=1)
print('score:', score[1], ' accuracy:', score[1])
print('history:', history.history.keys())
4.评估模型
使用plt绘制出来模型训练过程中的loss与accuracy
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig('lenet_acc.png')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig('lenet_loss.png')
plt.show()
到这里就完成了LeNet的搭建与训练,通过这个过程,对卷积层,激活函数、池化层、全连接层、模型的训练与评估等都有了进一步的学习,快快开始你的搭建吧。