RabbitMQ集群架构模型与原理解析
第一种叫做主备模式,这种主备模式呢它可以理解为我们的一个热备份,就是说我有一个master,还有一个slave。正常情况下我们的master是对外提供读写的,而slave呢仅仅作为一个备份,当我们出现异常的时候,比如说master故障宕机的时候呢会做一个切换,然后我们的slave节点被升级成一个master节点,这种方式呢也是非常经典的一种模型。
接下来我们再看一种远程模式,远程模式这个是RabbitMQ早期版本提供的一种多活的存储,主要是做这个数据的异地的容灾哈,异地的这个转移的它也可以提升我们的性能。比如说当我们单节点就是单个集群处理不过来的时候,可以把消息转发到下游的某一个集群模型中。这种方式呢它的架构其实非常简单,但是呢它的配置就非常的复杂。所以说一般都会用这种多活模式来替代这种远程模式。
接下来要介绍这种叫做镜像模式。这种镜像模式是业界使用最为广泛的一种RabbitMQ集群架构的模型,这种模型呢能够保障消息是非常可靠的。
最后一种就是多活模型了,多活模型其实跟远程模型也差不太多,就是做一个异地的容灾,或者是双活,或者是数据的一个转储功能,路由转发的功能。

接下来首先来介绍一下我们的主备模式,主备模式呢也叫warren叫做兔子窝,通常呢就是一个主节点加一个备份节点,然后呢采用一种主备的方案,当然是热备份。如果主节点由于某些故障挂掉,从节点可以继续的去提供服务,然后去做一个切换。
RabbitMQ它也是一种主备的机制,当我们RabbitMQ的master挂掉,它会利用这个zookeeper去做一个切换。并且它的切换呢也是秒级的,也不会说太影响我们整个的这个MQ集群服务。
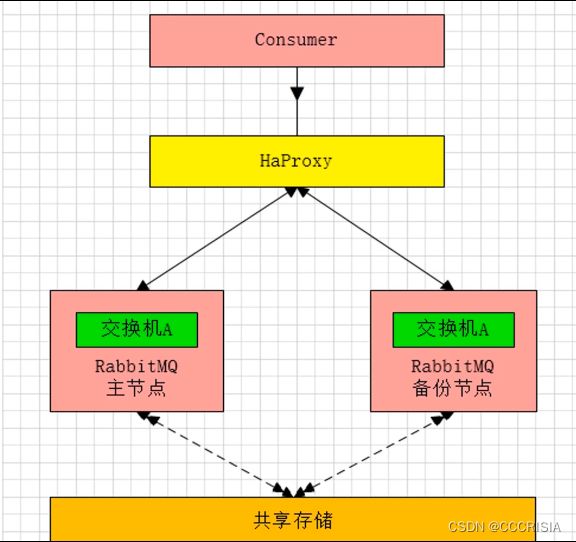
上面呢比如说是我们的这个consumer或者是这个provider生产消费者。
总之呢我在这里的这个consumer注意指的不仅仅是消费者,他可以理解为是一个需求方,他通过HaProxy去路由到默认是路由到主节点,master, 然后默认就是master去提供服务。当我们master出现故障的时候呢,下一次路由在我们这个HaProxy里面配置了一些规则以后,他会帮我们去路由到备份节点,备份节点会升级为主节点。当我们的这个主节点再次比如说修复好了之后,它也是加入到集群了,成为原来备份节点的一个备份节点,说白了就是主节点会进行一个漂移,有点类似于我们的里边的这个VIP漂移的概念,
对于这个主备模式,它的HaProxy里面的一些核心配置有哪些?
其实很简单,对于HaProxy第一个listener就是你主备模型的一个集群名字,我这里叫做rabbitmq_cluster,绑定的端口5672。
接下来就是轮询的模型,就是轮询的model是TCP呀还是HTTP呀,还是其他的协议。
HaProxy其实跟这个Nginx也差不太多。Nginx也提供了很多包括TCP HTTP这种协议,这种轮询的模型。
对于轮询模型呢,主流的轮询模型就是就是轮询。还有我们比如说最小连接数的一种这个balance策略,包括我们的这个哈希。通过这个哈希算法帮我们去做IP哈希呀等等等等这种轮询策略有很多。
然后呢我们看一看这个HaProxy。这个主节点就是这个76,然后备份节点是下面的77.主节点呢它做一个check。当我们每5秒钟做一个check。如果两次失败的时候,会帮我们去切换到下面比较长的这个配置里。
这个就是我们的备用节点,它比上面唯一的区别就是多了一个backup配置,这个backup关联字。
ok这个就是我们兔子窝的主备的这么一个配置了,是不是非常简单。
然后接下来呢我们去介绍一下这个远程模式。远程模式呢它的概念就是进行远程的通信复制,可以实现双活的一种简单的方式,简称Shovel。这种远程模式在现在来看,它是用的并不是特别多了,为什么呢?因为它的可靠性可能还有待提高,并且它的配置呢也非常非常的麻烦。
所谓这种Shovel呢,其实就是我们可以把消息进行不同中心的一个复制和转移的工作。当上游的MQ比如说压力过大的时候,有些消息呢处理不过来了,我们可以把它堆积到另外一个地方,然后呢让他两个集群进行一个互联,这么一个操作好了。我们接下来通过几幅图来看一看这种Shovel,就是我们的远程模式是如何去做的。

这个也是官方的一幅图了。比如说用户发消息,通过website,然后到我们第一个RabbitMQ去做消费处理。
然后呢,这里边注意有一个Shovel叫做replicate,是不是就是说我们的消息可以被转发到下游的另外一个地点的这个MQ中心集群,然后也可以去做一个消费的处理。它呢不仅仅是能够做一个容灾,而且还可以提高我们的什么,提高我们的这个订单的这个速率,消费速率。
好了,我们接下来再看,下面这是第2个MQ集群,它可以帮你去做一层路由的转换。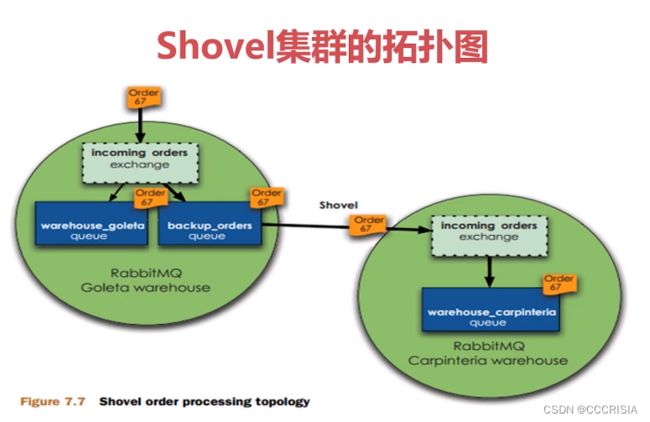
也就是说当我们第一个集群消费不过来的时候,可以去转到第二个。当我们第一个集群出现问题的时候,也可以转到第二个,这个是什么一种多活的方式。为什么说现在用的不多呢?原因就是因为它的配置非常非常的复杂,它的配置我们在这里简单读一读就好了。
因为实际工作中呢很少人去使用这种远程模式,都会用多活的模式去代替这种远程模式。首先呢它要启动rabbitMQ的插件,这个rabbitMQ插件首先要启动它的AMQP,为什么呀?因为这种远程模式,它们MQ集群之间的通信使用到了这个MQ的AMQP协议。然后去做通信的,然后呢你还要按able它的这个slope插件,这才可以。这是仅仅是第一步,第二步呢还要对一些配置文件进行配置。
比如说对这个配置文件叫做running cute config做一个配置。你做法就是你要touch到一个这个配置文件,touch完了之后,我要对这个配置文件加一堆的配置。这一堆的配置呢主要是我们的源与目的地的一个配置,当然这里说源和目的地使用相同的配置就可以了。
我们来看一看这个配置有多复杂。

大体上呢就是说你当前两个集群想要建立关联,有一个source就是源,还有一个destination,然后呢,对于每一个broker它的地址,你要配置一下,对于它的这个deletion,就是你要声明什么队列需要帮我去做路由什么交换机,然后怎么去绑定规则。就是说你每次建一种exchange交换机,每次建一种队列的时候,可能都需要在里面去加一个配置。就是把这个路由去通过配置写上。
如果以后你要加配置,你怎么办?如果你要加队列,想要帮我去路由到下游的destination,你就在配置平台上,你还要去加。所以说这个是非常非常不方便的,运营起来非常麻烦的这种方式。
当然其实最终我们业界目前使用rabbitMQ集群,最主流的还是我接下来要讲的这种模式叫做Mirror镜像模式。
镜像模式呢它也是一种非常经典的进行架构,它能够保障数据百分之百不流失。镜像的概念其实就是一个复制嘛。
我们来看一看,在实际的工作中呢使用非常的多,并且我们很多互联网大公司都是使用这种方式来搭建rabbitMQ集群的,镜像模式呢其实说白了就是我们数据的一个备份。
其实最主流的或者是说最显而易见的。大家如果对mangoDB熟悉,它有一种模型叫做复制集replicate这种方式。
这种呢其实跟它比较相像,或者是我们的ESsearch中的一些replicate副本概念。
当然呢它的缺点也会有这个我们后面再说。这个就是rabbitMQ的镜像。rabbitMQ的镜像队列呢,它能够保障哪几点呢?
第一点就是可靠性,数据不会丢。因为他的数据发过来,他要同步到对应的镜像集群内,所有所有的节点都会做一个数据的备份存储了。
所以说即使是说你集群中有一个节点挂掉了,有一个节点磁盘坏了都没关系。我们通过镜像队列的一些恢复手段都都可以做一些恢复。
然后呢,它就是内部主要是做的这个数据同步。因为我们都知道rabbitMQ它的底层是天然的这种交换机的方式,它也会是跟原生socket一样低的延迟。
所以说它的性能在做数据同步的时候,它的性能是非常好的,ok然后呢它还可以保证可靠性,保证可靠性最好呢大家是基数个节点。
ok接下来呢我们来看一看镜像队列如何去搭建这个镜像集群。

这幅图呢其实就是一个完整的镜像队列集群的模型。
先从最下面去看。这个最下面呢是三个节点MQ服务器,大家可以看到叫mirror queue。然后这个第二个也是mirror queue,第三个也是mirror queue。
也就是说我们三个节点数据保存都是一致的。这个就有点像我们的复制集的概念了。
ok再往上看呢,就是我们上游的这个服务,叫做spring boot application。他去访问我们的这个镜像服务器MQ服务器它不是直连的,它是通过一层中间的代理层。中间代理层蓝色的用什么呢?
其实还是用HAproxy,但是我在这里又加了一个叫做keep live,为什么呢?因为当我们HAproxy如果是单点,如果发生故障,就这台服务器如果挂掉了或者有问题了,是不是你整个就提供不了服务了。所以说利用keep live做一个什么高可用,他会虚拟出来一个VIP。我们应用服务直接去通过VIP跟我们的两台HAproxy打交道。当然他只是路由到其中一台,然后由其中一台的HAproxy帮我们去负载均衡到3个最下面的最底层的mirror queue上面。
这种镜像队列有一种天然的缺陷是什么?其实一眼就看出来了,缺陷就是说它不能支持横向的扩展,因为它的数据存储是有限的。当我们的数据量尤其在高峰期的时候,如果一旦流量非常大,可能我们消费者他消费的速率没有快,消息呢都会堆积到我们的这个镜像队列上。横向扩容根本就没有意义。
为什么呢?你横向再扩一份儿,它是增加了我们rabbitMQ集群的负担。
因为四个节点4份数据要同步,肯定性能上吞吐量上一定是有所降低的。所以说其实官方也建议说,如果镜像对着集群呢三个就好了。
三个呢其实能够保障一个可靠性,奇数个节点,也就是说最小的奇数个节点了。
但如果说你现在想要横向扩容应该怎么办呢?在这里官方呢其实提供了一种叫做多活模式,就是federation,也就是下面我们要讲解的去解决这种镜像队列的一种无法横向扩容的一个缺点。
多活模式呢这种模式其实也是实现了这个数据的异地的一个复制的这么一个主流的方式。
它呢其实相比于我们的这种远程模式,就是Shovel,它其实肯定是有优点的。
因为这种slower远程模式它的配置非常复杂。之前我们就说了,所以说一般呢你想去做这种异地的集群,多活呀,都会采用这种federation。
就是我们现在要说的这种模式,要依赖的federation插件去做。也就是说你也需要安装一个插件,叫federation插件,然后呢可以去实现我们MQ可靠性的数据通信,并且呢也可以实现这种多活。我两个rabbit MQ集群中心,这样从宏观的角度来讲,让你整个的应用服务能够更加的稳定一些。
对于多活模式呢,rabbitMQ它其实采取了双中心或者是多中心的概念了,两套或者多套数据中心,它各有一套MQ集群。
每个中心的集群呢除了正常的去提供自己所需的服务之外,还可以去做数据的一些互通。这就是federation集群模型的最重要的这么一个特点,接下来我们来看一看这个多活模型的一个架构图。
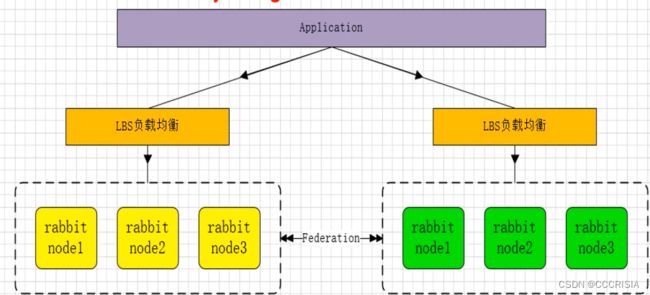
比如说我上面的这个application是我的应用,然后我的LBS负载均衡器下面它负载到三个节点,然后这边也负载到三个节点。
有一些数据你想保障不丢失,或者是想保证他们两个集群之间的异地互通,中间呢就可以去使用我们的federation 插件去做消息的这个连接就可以了。
对于federation 呢它其实是一个不需要构建cluster 的这种方式。其实本身自己的集群内部已经是镜像队列了。
所以说你就没必要再搞一个什么federation 集群了,你直接用它做一个插件,让两个集群之间做一个消息相互之间的传输,做一个高性能传输就可以了。
federation 插件呢可以在broker 或者cluster 之间进行消息传输。然后连接的双方呢可以使用不同的users 和virtual host。就是说他不在意你的user 权限以及v host,双方也可以使用不同版本的RabbitMQ和ERlang了。
所以说federation 插件使用的协议就是我们RabbitMQ经典的AMQP协议通信即可,可以接受不连续的数据的传输。这个是他的这个federation 最优秀的地方,就是版本我要升级都没问题。
可能就是有一些历史遗留原因,我一个中心的RabbitMQ集群,他可能搭建的比较早。另外一个我想用新的没关系,是可以的。
他们两个想互通互通也可以。
federation本质上它其实就是一个exchanges,可以看成downstream 与从upstream 主动拉取消息。也就是说我们的下游从上游主动拉取消息,对不对?但并不是拉取所有的消息。其实这个东西感觉就跟我们的什么呢?之前所说的个远程模式就是Shovel 差不多。
但是它解决了这个Shovel 的弊端是什么?Shovel 它需要在配置文件里去配,他没办法动态去做。
就你想要去加一个什么呀,加一个exchange,去让他这两个集群多一个exchange 去做同步的时候,你必须要重启服务。然后在配置文件里先配置好了之后,然后再起来,这就非常麻烦。
federation它的优点就是说你想去加哪几个exchange 进行相互之间的通信和转发。可以你直接可以通过控制台操作就好了。所以说这个是可以可视化,而且是即时生效的,不需要写一些这种复杂的配置,也是支持这种热更新的。在这里必须是Downstream 上已经明确了绑定关系的一个限制。
也就是说你的downstream 一定要upstream 上面的exchange 的一个绑定,这样它才能够通过Downstream 自己的一个物理的队列去去拉取upstream。给我传过来的消息。这里边也就是说AAMQP它实现的是这个中间两个集群的一个通信代理。
Downstream会将绑定关系组合在一起,绑定解除命令也可以去做。
也就是说你说我配完了之后,我两个集群之间我不想去做通信了,可以直接通过控制台把个exchange 之间的这个连线的一个桥梁给它删掉就可以了。
所以说这是非常非常方便的。接下来我们来看一看这个federation 的一幅图。
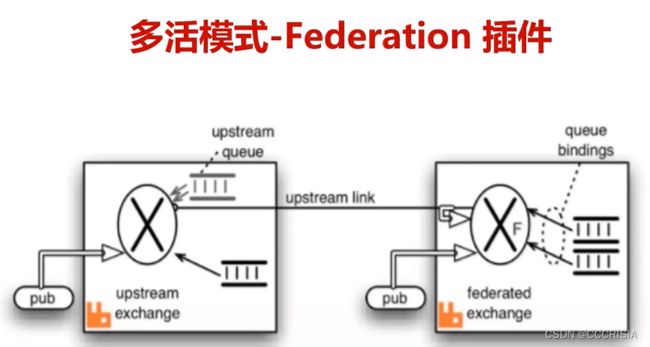
这个是我们的upstream,就是左边的这块是我们的上游。下面呢肯定就是我们的Downstream 了,是不是upstream 跟downstream 有什么区别呢?
这里边注意它们两个之间有一个叫做upstream link ,就是一个上游的连接。上游的连接呢一定要跟下游一定要绑定上上游的一个这个exchange,他们两个之间才能连上。
我上游可不可以消费呢?可以,我上游消费完了之后,也可以把消息转发给我的这个下游,然后下游也可以做一个具体的处理,这就是一个federation。
当然这里边自己他也可以去发消息处理。也就是说你可以认为是两个完全独立的镜像队列集群,只不过我们可以利用非的A型插件实现上下游的一个灵活的消息的这种转储转发功能。