互联网架构演进历程
本篇博客只是用于记录昨天所学,并不一定正确,评论区欢迎指正,我马上改
目录
首先谈谈什么是单体架构?
分布式架构
缓存
互联网架构演进历程:
1.单体架构
2.分布式架构
首先谈谈什么是单体架构?
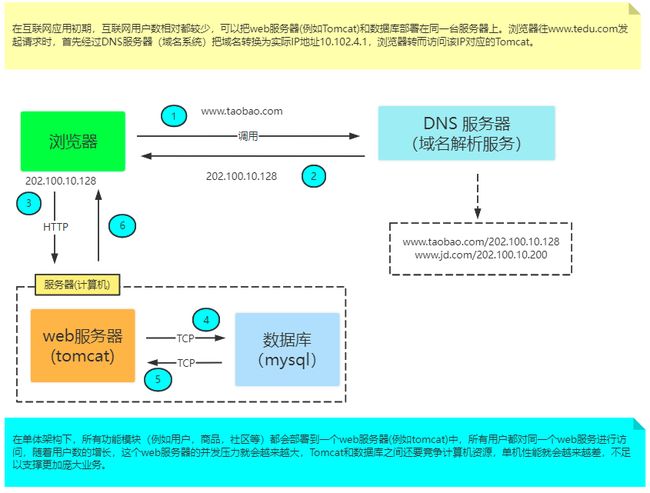
所谓单体架构我理解就是,假设我们将服务器理解为一台提供服务的计算机,那么从头到尾只有一台计算机在提供服务,所有的服务都部署在一个web服务器上,而web服务器与数据库服务器同时部署在一台计算机上,一起提供服务。
让我们先来看看,单体架构下服务的运行顺序。首先我们在地址栏里面输入地址,此时浏览器会将我们输入的地址发给dns(这个应该部分人不陌生,记得之前管家类的软件上都会有dns调优,就是那个玩意),dns根据我们输入的地址进行域名解析,比方说如图的淘宝就解析为202.100.10.128。当dns返回给浏览器这个ip地址时,浏览器就会根据这个ip地址去寻找这条一台计算机,也就是服务器。找到了之后将http请求发给web服务器,也就是tomcat(并不指web服务器就一定是tomcat,仅以tomcat举例,便于理解),那么web服务器去解析请求处理业务,寻找资源并返回。需要查询数据库的就与数据库进行TCP连接,然后将结果原路返回给浏览器,然后浏览器将结果呈现给用户。
那么这样走下来,是不是大家就觉得还可以,是这个流程,这也就是目前大部分学习阶段的学生写的架构。因为不发布,用户数不多,测试基本上也就是组内的几个人测试访问,看不出问题。
但是!如果发布了,火了,用户数量有几万个了。那么问题就出来了。
几万个用户同时访问这台服务器,也就是学生手里的笔记本,那么每一个用户请求笔记本都需要cpu去处理,web服务器上业务处理需要cpu,数据库需要cpu,哪儿哪儿都要cpu,cpu就不够,发生了争抢现象,有的用户的请求就卡住阻塞了, 迟迟得不到回复。这时候服务器的效率就是异常低下了。那么怎么去解决这个问题呢?下面讲的分布式架构就是为了解决这个问题。
那么单体架构是否没有优点?
不是的,有的。
优点:维护起来简单,部署起来也简单。最显而易见的优点。还有我理解的一个,就是都在一个计算机上,用户数少的情况下,访问速度应该要略高于分布式,但是也不一定。
缺点:存储能力有限,计算能力也有限。系统可靠性差(打个比方:学生笔记本死机就所有数据服务都停止了,而且可能发生数据丢失)
单体架构技术栈:jsp+servlet+javabean(基本是不用了),spring+springMVC+mybatis(ssm)+springboot(现在在用)
2.分布式架构
分布式架构也有多种,有web服务器和数据库服务器分开的,也有web服务器有多个,分布在不同计算机,数据库也一样分布在多个计算机,猜想分布式数据库量大了,就是现在的大数据了,大概吧!
补充一个知识点
计算机中服务的唯一标识是端口
网络的服务唯一标识是ip地址
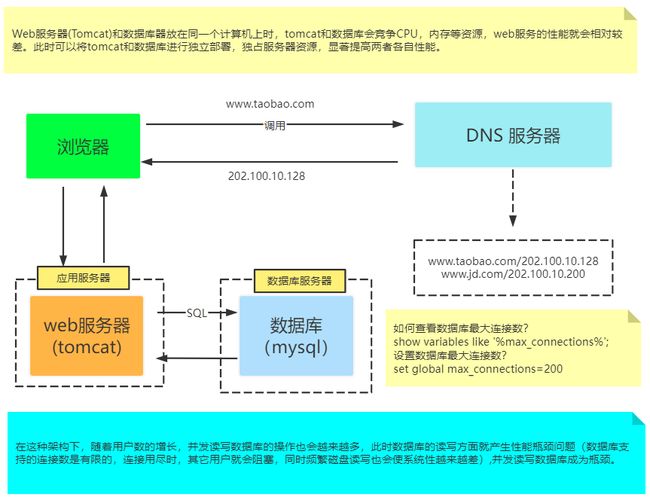
如图,第二张图和第一张图唯一区别就是web服务器和数据库不在一个计算机上了,打个比方:就是同学A写代码,idea里面配置文件写的数据库地址不在自己电脑上了,而是在同一组的同学B电脑上,这就是是最简单的一个分布式例子了。当访问同学A的电脑上的web服务器,服务器要去查询数据库就发sql给同学B的电脑上的数据库进行查询处理然后返回。原先一台电脑既要处理web业务又要处理数据库的业务,现在一台电脑只处理一个事情,那么web服务就相对于拥有原先两倍的cpu,数据库同理,效率就提高了。当web服务器部署在不同电脑,即拥有多个web服务器时,效率会更高!
但是!随之而来的另一个问题来咯!小飞棍来咯~
当web服务器越来越多,用户越来越多,那么势必查询数据库的操作也会越来越多,但是要知道一个数据库所能支持的连接数是有限的。
这里补充一个知识点:
Mysql5.0版本:默认的最大连接数为100,上限为16384
不同版本数据库不同,但是也能说明一件事情,就是数据库连接数确实是有上限的,而且数量不多。
show variables like’%max_connections%’;
//查询语句,用于查询数据库连接数,大家可以自己试试,看看自己的数据库连接数是多少
set global_max_connections = 200;
//sql语句设置连接数,可以是300.400.500.1000
//但是一般不会写这个,我们一般会在项目配置文件中配置最大连接数
当数据库连接到到顶了,那么再布置多的web服务器也没有意义了,数据库访问受限了!这就是效率的瓶颈了!
此时解决数据库连接问题至关重要!否则分布式就没有太大意义了!
使用缓存和连接池可以部分解决数据库连接限制问题。
连接池是使连接复用,减少连接数!实际上用户基数大的情况下,也没啥用,再减少也少不到哪里去,还是受限。
缓存呢?
缓存即将一次查询的结果存储在web服务器上面,当别的用户再次请求这个数据库查询的时候就不再查询数据库了,而是直接返回这个结果,减少了访问数据库的次数。如果说将大量用户会进行的重复数据库操作缓存在服务器是可以大量减少数据库操作的,但是这要求我们的缓存具有高命中率。所谓高命中率就是,缓存的东西是大量用户需要的,而不是缓存个别用户的。比如商品列表,某某列表,所有用户进淘宝首页都会查询这个商品的列表,那么就可以缓存这个列表到web服务器,用户别的用户再请求,直接返给他就行了。
这里就引入了一个问题,要用缓存来解决数据库连接限制问题,提高效率,不是说只有有缓存就行的,而是对我们的缓存有要求的。那么我们建立一个缓存对象,需要考虑上什么问题?
- 数据结构(散列结构=>存取数据速度要快,随机存取)
- 数据淘汰算法(缓存满了基于什么方式淘汰数据)
- 缓存数据的生命周期
- 缓存数据的定时刷新(提高数据一致性)
- 缓存命中率分析(命中率低说明设计不合理)
- 并发访问时的线程安全
- 数据的序列化和返序列化
数据结构:很重要的一个问题。缓存对象的数据结构一定要具有随机存取,尤其对取数据的速度有高要求,我们缓存了一个商品列表,就不可能用数组,不然用户查询一个商品信息,我们难道就要遍历一次数组吗?显然这种数据结构不行,map就会比数组好一些,根据用户给的商品key值就能直接找到该商品信息,返给他,效率就高了很多,所以缓存的数据结构尤其重要。
数据淘汰算法:缓存是需要更新换代的!缓存满了,我们基于什么算法去淘汰缓存,是新时间优先(即保留新的缓存,将旧的缓存淘汰掉)还是多访问优先(不管时间,保留最多人用的那个缓存,将较少人用的缓存淘汰) ,这是我们需要去考虑的问题,只管时间与只管使用人数显然都是不行的,这时候一个好的GC算法就很重要。
最常见的几种过期策略如下:
多长时间没有被请求,则过期,最典型的就是ASP和ASP.net 提供的 Section 功能。
依赖于文件变更的缓存,一旦文件被修改,缓存则过期,典型的是 WEB站点的 Web.config 。
缓存数据生命周期:
1.进入缓存。(进入缓存的时候,可能需要指定它以后的过期策略,如果不指定,需要使用系统默认的过期策略)
2.从缓存中获得它,注意,这时候需要处理线程安全的问题。
3.更新缓存,注意,也需要考虑线程安全问题
4.离开缓存,这个可能是外部请求,也可能是缓存根据过期策略把它清理掉。
自己设计一个缓存的生命周期,什么时候更新什么时候淘汰等。。
缓存定时刷新:主要就是上面讲到过的,什么时候刷新缓存,老旧的已经过时的数据要被淘汰
命中率:前面讲过不赘述
安全问题:这个是缓存最大的问题!主要发生在获得缓存和更改缓存的过程中!因为必然是涉及线程并发,那么多线程同时访问同一个缓存对象肯定就会存在线程安全问题,不注意线程安全,可能导致一个用户修改了缓存,然后其他用户获得的都是修改后的数据,全部出错!
解决方法很简单,把你的业务逻辑,代码触发情况都考虑清楚,不要遗留没有触底的地方。
简单的方法会导致你的代码逻辑变得非常复杂。
这也就是有些人,在非必要的时候,建议你不要用缓存的原因。一旦开始使用缓存,你就应该准备增加大量的代码来处理数据同步的问题。
当然也可以使用一些线程安全的产品,但是线程安全的产品并不一定代表线程安全,主要还得看代码,业务逻辑!CurrentHashMap是线程安全的HashMap!
数据的序列化和反序列化
序列化:将 Java 对象转换成字节流的过程
反序列化:将字节流转换成 Java 对象的过程。
发生在两个进程远程传输
以下是一些使用序列化的示例:
- 以面向对象的方式将数据存储到磁盘上的文件。例如,分布式缓存Redis 存储 Student 对象的列表。
- 将程序的状态保存在磁盘上。例如保存游戏状态。
- 通过网络以表单对象形式发送数据。例如,在聊天应用程序中以对象形式发送消息。