简单的随机森林预测(Python)
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
train=pd.read_excel('E:/project_6.18/train.xlsx')
train_f=pd.read_excel('E:/project_6.18/train_nan.xlsx')
test=pd.read_excel('E:/project_6.18/test.xlsx')
特征处理
非尖货–1 尖货–0
价格力等级 低–0 中–1 高–2
#处理是否尖货
train_f['是否尖货']=(train_f['是否尖货']=='非尖货').astype('int')
#处理价格力等
labels=train_f['价格力等级'].unique().tolist()#显示唯一的值
train_f['价格力等级']=train_f['价格力等级'].apply(lambda x : labels.index(x))
train_f.drop(['商品id'],axis=1,inplace=True)
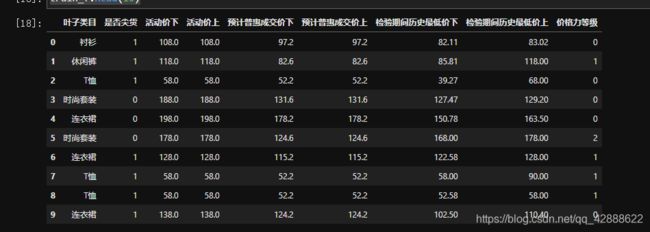
#对叶子类目做二值化分列处理
train_f = train_f.join(pd.get_dummies(train_f.叶子类目, prefix= '叶子类目'))
#建模特征
train_f_y=train_f['价格力等级']
train_f_x=train_f.drop(['叶子类目','价格力等级'],axis=1)

测试集
#处理是否尖货
test['是否尖货']=(test['是否尖货']=='非尖货').astype('int')
#处理价格力等
test['价格力等级']=test['价格力等级'].apply(lambda x : labels.index(x))
test.drop(['商品id'],axis=1,inplace=True)
#对叶子类目做二值化分列处理
test= test.join(pd.get_dummies(test.叶子类目, prefix= '叶子类目'))
#建模特征
answer_y=test['价格力等级']
test_x=test.drop(['叶子类目','价格力等级'],axis=1)
建模(训练集得分)
forest=RandomForestClassifier(n_estimators=100,random_state=0,n_jobs=-1)
forest.fit(train_f_x,train_f_y)
test_y=forest.predict(test_x)
train_score=forest.score(train_f_x,train_f_y)
print(train_score)

特征重要性
feature_imp_sorted_rf = pd.DataFrame({'feature': list(train_f_x), 'importance': forest.feature_importances_}).sort_values('importance', ascending=False)
feature_imp_sorted_rf

测试集得分
方1
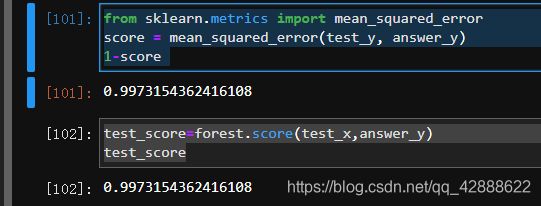
test_score=forest.score(test_x,answer_y)
test_score
方2
from sklearn.metrics import mean_squared_error
score = mean_squared_error(test_y, answer_y)
1-score
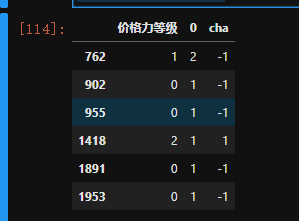
查看预测错误的(有6个)
answer_y=pd.DataFrame(answer_y)
pred=pd.DataFrame(test_y.tolist())
sco=pd.concat([answer_y,pred],axis=1)
sco['cha']=sco['价格力等级']-sco[0]
sco[sco['cha']!=0]