Wav2KWS: Transfer Learning From Speech Representations for Keyword Spotting(2021)
Wav2KWS:基于语音表示的迁移学习用于关键词识别
摘要
随着设备上人工智能的不断发展,人们提出了智能扬声器、可穿戴设备和(其他设备上或边缘处理系统)等支持语音的设备。然而,构建或获取对鲁棒关键词识别(KWS)至关重要的大型训练数据集仍然很麻烦。
为了解决这个问题,我们提出了一种深度神经网络,可以从任意关键字指令集快速建立高性能的KWS系统。
我们使用经过大规模语音语料库预训练的编码器作为骨干网络,然后为KWS设计一个有效的迁移网络。为了证明所提出的网络的可行性,在谷歌语音命令数据集V1和V2上进行了各种实验。
此外,为了验证网络对不同语言的适用性,我们使用三种不同的韩语语音命令数据集进行了实验。在两个实验中,该网络的性能均优于最先进的深度神经网络。此外,即使使用合成的文本到语音数据进行训练,该网络也可以理解真实的人类声音。
索引词:关键词识别、语音命令识别、迁移学习。
研究内容
预训练模型提供了一种解决方案,以克服目标域中的数据稀缺性。最近,Schneider等人[5]表明,LibriSpeech[8]的预训练模型可以(通过微调(具有小训练数据集的)模型来)获得高性能。
关键词识别(KWS)可以识别数量有限的命令,并与识别连续语音[10]-[14]的ASR一起被积极地研究。KWS中的受限命令包括简单的控制关键字,如yes或no。常用命令包括“Hey Siri”[15]、“Alexa”[16]、[17]和“Okay Google”[10],它们触发特定供应商对设备的控制。控制应用程序和服务的命令包括“播放音乐”、“关机”和“明天天气怎么样?”虽然已经证明了神经网络对KWS的适用性,但最近的研究追求性能改善和减少参数数量[18]-[20],其他研究则侧重于提高实时KWS性能[12]、[21]。
谷歌语音命令数据集[22]被视为事实上的KWS标准。
不幸的是,KWS的公开可用数据比ASR少得多,这阻碍了任意关键字的组合和数据准备期间全面KWS系统的构建。因此,由于可用的训练数据较少,神经网络优化变得困难。
为了克服KWS的数据稀缺性问题,使用了预训练头模型和合成数据[23]。Lin等人[23]指出,构建最先进的(SOTA)KWS模型需要每个命令超过4000个记录的人类语音样本。
在本研究中,我们设计了一种方法,通过采用Wav2Vec 2.0框架[5],即使可用的命令样本很少,也能最大限度地识别语音命令话语,这在第三节A中有详细说明。
为了实现高KWS性能,我们采用了合适的编码器用于学习从主干[24]中迁移语音表示,如图1所示。
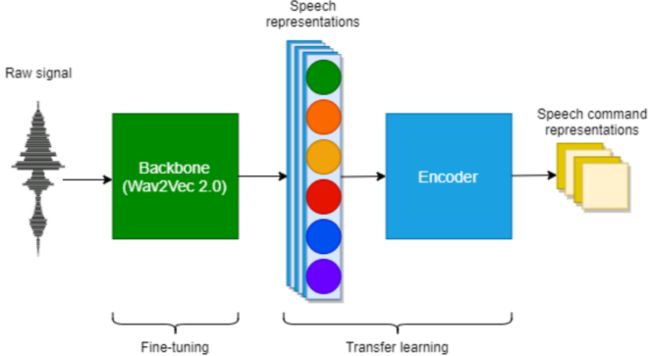
FIGURE 1. 主干使用一个预先训练的Wav2Vec2.0编码器,和一个额外的编码器组合用于KWS。主干经过微调,编码器使用从语音表示转换过来的语音命令表示进行训练。
为了将KWS描述为一个分类问题,我们认为(考虑到)主干中的训练样本比语音命令的短语要长。然后,我们设计了一个编码器,可以实现迁移学习[25]。在微调过程中,主干和编码器对目标KWS域数据集执行优化。
应用于语音命令识别的建议模型提高了在谷歌语音命令数据集V1[26]和V2[27]上的SOTA性能。此外,该模型在我们构建的韩语语音命令数据集中达到了99%以上的准确率。据我们所知,这是第一次尝试证明,在英语语音语料库上预先训练的模型可以成功地应用于使用韩国语音数据的KWS。这些术语与太阳能发电系统、医疗保健和日常活动有关。每个数据集为每个命令包含少于300个样本。
提出的方法&模型架构
A、 WAV2VEC 2.0编码器
Wav2Vec 2.0编码器通过对比损失(1)进行训练,该(1)降低了qt和q~与ct的余弦相似度,用于识别真实的量化潜在语音表示,qt ,在一组K+1量化候选表示q~∈ Qt中。

特征通过卷积层从输入的原始音频信号中提取,卷积层具有宽核(wide kernel)作为特征提取器,然后通过连续卷积层和后投影将其转换为高级特征。
所编码的特征与由组卷积层计算的相对位置嵌入相结合,然后输入到transformer。
每个卷积层的输出通过高斯误差线性单元(GeLU)[36]激活来增加非线性,并执行层归一化。在包括ASR在内的各种任务中,GeLU匹配或超过了具有修正线性单元(ReLU)或指数线性单元激活的模型的性能。
然后,通过在t个时间步从每个transformer层捕获语音表示,CT:c1,…,ct作为transformer输出,并连接到迁移学习网络中的新编码阶段。
由于上述过程依赖于量化码本[37],因此其被设计为利用可用的码本和使用多样性的损失。多样性损失的权重由其超参数调整。

FIGURE 2. 所提出的Wav2KWS模型的结构。一个主干网络直接连接到迁移网络。主干网络包括卷积层、特征提取、后投影、位置嵌入和transformer。该迁移网络由感受野卷积层、逐点和1D卷积层组成,用于顺序输出。Wav2KWS模型的详细超参数见图3和表1。
B、 迁移学习网络
图2显示了拟议Wav2KWS模型的示意图,其中连接了主干网络和迁移学习网络。基于Wav2Vec 2.0的主干网络在LibriSpeech上预训练960小时。迁移学习网络包括一种新的编码器,该编码器能够将编码语音表示转换为语音命令特征。
在迁移学习网络中,我们考虑了以下两个方面并实现了必要的层:
- 用于主干网络预训练的数据不同于语音命令数据。因此,需要额外的编码来将特定数据特征表示为向量;
2)主干输出的上下文表示是带有时间序列的向量;因此,它们应该表示为一组语音命令,同时缩小时间序列进行分类。
为了解决这两个方面的问题,我们首先通过将transformer输出(CT)转换为C来压缩时间序列信息,同时保持卷积层的上下文信息,其内核大小适合于时间序列向量中的语音采样率。
然后,我们使用逐点卷积层压缩信息,最后使用1D卷积层作为分类器以保留来自主干网络和迁移学习网络的非线性信息。
前两个卷积层的输出经过ReLU激活以增加非线性并执行层归一化。
在迁移学习网络中训练潜在语音命令表示后,Wav2KWS模型通过对k个语音命令集X(x0,…,xk)进行分类,使用softmax函数求解(2)中的Lc。

图3和表1详细说明了拟议的Wav2KWS模型。在主干中每个卷积层的输出使用GeLU激活,在迁移学习网络中每个卷积层的输出使用ReLU激活,并且所有输出都经过层归一化。图3右侧的插图显示了将主干中编码的上下文语音表示转换为语音命令表示。
第一个特征提取器由一个卷积层和一个块组成。在第一卷积层,大小为10的核从原始音频信号中提取特征。表1列出了图3中块A的参数。层Conv2重复三次。然后,层Conv3重复两次。位置嵌入使用大小为128的内核和16组卷积层来编码相对位置信息并添加特征。
FIGURE 3. Wav2KWS模型的架构。(省略的超参数使用其默认值。R,递归层数;Conv,卷积层;BN,批量归一化;ReLU,校正线性单元;GeLU,高斯误差线性单元)。
transformer 具有768个隐藏维度,并为迁移学习网络提供上下文语音表示。然后,两个卷积层Conv4和Conv5构成了一个用于迁移学习的新型编码器。Conv4层使用大小为25的内核来压缩语音时间序列。层Conv5使用逐点卷积。最后一层Conv6用于分类,一维卷积层保留非线性和位置信息。最后一层具有与类数相同的多个通道。

TABLE 1. Wav2KWS模型的超参数。(K,核大小(kernel size);S/D/G,步长,扩张和组(stride, dilation, and groups);R,循环层数)。
文章贡献
本研究的贡献总结如下:
1) 使用基于大型ASR语料库的预训练模型作为主干,我们提出了一种将wav表示向量转换为KWS表示(Wav2KWS)的模型。
2) 提出的Wav2KWS模型实现了SOTA性能,优于谷歌语音命令数据集V1和V2以及三个韩国语音命令数据集的现有模型。
3) 我们表明,通过使用文本-语音(TTS)合成数据,可以在一个小的语音命令数据集上实现高性能的KWS。
4) 我们还表明,通过应用迁移学习,在英语语音语料库上预训练的主干可以用于其他语言(如韩语)的KWS。
补充内容
A、 ASR
ASR正在快速发展,新兴模型不断提高SOTA性能。最近,Wav2Vec 2.0[5]在自动语音识别中实现了SOTA性能,与自然语言处理中的BERT[9]相当。Wav2Vec 2.0在LibriSpeech语料库上进行了预训练[8]。在自然语言处理中,使用掩码语言建模[28]、[29]对BERT进行预训练,然后针对各种下游任务进行微调[30]-[32]。另一方面,Wav2Vec 2.0依赖于端到端微调[5]、[6]、[33]。
B、 KWS
随着边缘计算的出现,基于深度学习的知识仓库研究致力于通过实现更快的推理或减少参数数量来提高性能[19]、[20]。时间卷积[19]可以减少现有模型的参数数量,一维时间通道可分离卷积神经网络[20]进一步简化了模型。同样,通过使用数据扩充(增强)[34],可以防止减少ResNet模型大小后的性能下降。
最近对KWS的研究考虑了各种问题,例如在现实环境下的识别和对噪声的鲁棒性,以及参数数量的减少。多头注意力递归神经网络在Google语音命令数据集V1和V2[21]上分别达到了97.2%和98.0%的高精度,从而克服了流KWS和测试数据集之间的模型性能差距。虽然正确训练神经网络取决于训练数据的可用性,但解决数据匮乏可能会很麻烦且成本高昂。
头部模型显示了嵌入的好处,它是建立在学习许多短话语的基础上[23]。头部模型从预训练嵌入的共享权重快速收敛到模型。如果没有头部模型,训练需要4000个真实样本,而使用头部模型时,在谷歌语音命令数据集V2上仅需要500个样本就可以达到97.7%的准确性。虽然KWS有改进的端到端模型[21](例如QuartzNet[35]),但在大规模语音语料库上的预训练模型尚未用于KWS。
即使没有额外的合成数据,我们也可以通过一个小的训练数据集实现精确的KWS。通过使用预训练模型作为主干,我们提出了一种简单而有效的结构来有效地学习语音命令表示。
实验
A. 数据扩充(增强)和预处理
将每个语音样本的采样率转换为16 kHz。为了从每个语音样本中提取具有最大均方根(rms)值的代表性1秒段,我们在Python中实现了最响亮(最大段)的部分提取[39](图4)。为此,分析了重叠1ms的1s窗口。
在训练期间,应用了以下三种数据增强操作:
1) 通过从均匀分布中选择的时间ts对信号进行时间偏移[−100100)毫秒。
2) 使用从[0,0.7][12]、[40]中均匀分布中选择的功率p合成背景噪声。
3) 类似于SpecAugment(…)[41],根据信号的均匀分布,将信号值从时间m到m+100 ms设置为0,从而使信号静音[−100100)ms(图5)。
我们以0.5的概率应用每个数据增强操作,与任何操作组合的应用相比,当应用所有操作时,实现了最高的性能。
FIGURE 4. 语音信号(a)和(c)与他们各自的最响亮的声音片段(b)和(d).
FIGURE 5.语音信号(a)和(c),各自掩码信号(b)和(d).
B.在语音命令数据集v1和v2上的实验
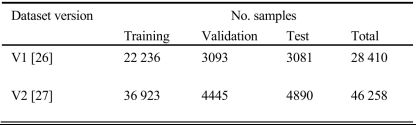
TABLE 2. 本研究中使用的谷歌语音命令数据集V1和V2的特征。

TABLE 3. 考虑到谷歌语音命令数据集V1和V2的12个共享命令,基线模型和拟议Wav2KWS模型的准确性。
C.在韩国进行的与太阳能发电系统相关的指令实验

TABLE 4. 谷歌语音命令数据集V2及其22条命令上基线模型和拟议Wav2KWS模型的准确性。
D.在韩国进行的与医疗保健和日常活动相关的指挥实验
TABLE 5. 被动记录和由TTS合成的语音样本数,对应于与太阳能发电系统相关的韩语命令。

TABLE 6. 基线模型和拟议Wav2KWS模型的准确性,考虑了来自具有TTS数据的solar语音命令数据集的25个命令。

TABLE 7. 考虑到与医疗保健和日常活动相关的14个关键词,基线模型和拟议Wav2KWS模型的准确性。
E.根据kws的训练样本的数量

FIGURE 6. 当训练每个数据集迁移学习的一个epoch时,拟议Wav2KWS模型的KWS精度。
FIGURE 7. 根据谷歌语音命令数据集V2和太阳能发电系统数据集上每个类的话语数确定准确性。

FIGURE 8. 谷歌语音命令数据集V2和太阳能发电系统数据集上的学习曲线。
我们提出了Wav2KWS模型,该模型在很少的训练样本下实现了鲁棒和准确的KWS。
该模型在谷歌语音命令数据集V1和V2以及三个韩国语音命令数据集上建立了新的SOTA性能。现有研究主要使用SOTA轻量级模型或高级深度学习架构,但需要数百个训练样本。
另一方面,通过利用预训练编码器,所提出的Wav2KWS模型可以在少量可用样本的情况下获得高KWS性能,在特定情况下实现完美的准确性。
具体来说,每个命令大约有40个英文训练样本和20个韩文训练样本,可以实现具有拟议Wav2KWS模型的高性能KWS。
此外,英语语料库上的预训练模型可以直接应用于韩语语音,同时保持比基线模型更高的性能。在未来的工作中,我们计划通过在自然语言处理中采用蒸馏和模型简化技术来减少模型权重。
我们还打算在边缘设备上实现拟议的Wav2KWS模型。