多模态预训练阅读总结
加※:开头,这是我自己的总结,可能不一定你能看得懂,建议还是自己读读论文,深入理解
总结了b站zhu老师的视频多模态串讲。
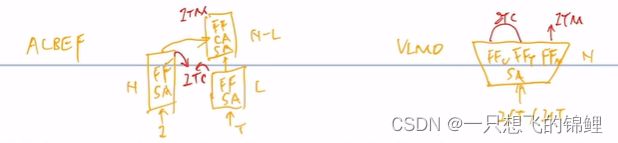
ALBEF
摘要
1.这篇工作的 visual encoder 不仅diss 之前的效率不高(之前是目标检测),更重要的一点是,在它看来,之前预先提取好的目标检测的物体特征 因为已经提取好了,不是end-to-end,所以导致多模态融合那块或者说多模态匹配那块,很可能会得到不好的结果。(multimodal encoder 学不好)
how to do? 它们决定 先 align 再 fuse,方法: 使用一个对比学习loss——ITC(看到这里感觉这个不是之前有的吗?)
2.第二个就是最新的贡献,怎么能从noisy的从网上爬下来的数据学到东西呢? 方法是: 提出了一个momentum distillation方法,即自训练的方法去学习 (伪标签)
3.所有的东西和loss以及第二点提出的,理论化分析是给数据进行了增强
4.效率高,且效果好,开源,8卡
主题方法:
1.模型总览:
- vision transformer 标准的,借鉴了 DEIT论文里面的模型
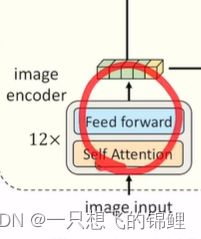
- 使用了之前的最优配比,text encoder 和 multimodal encoder
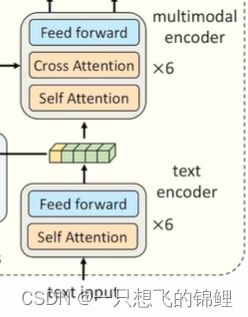
- MoD
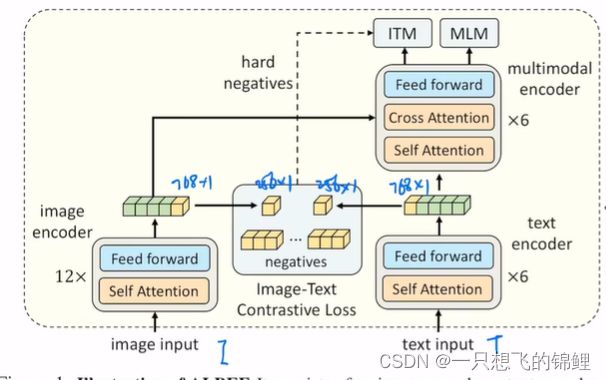
这个整个流程对应了前面说的先align再fuse
2.loss 训练:
- ITC:利用 momentum方法负样本(参考m论文)
- ITM:二分类loss,太简单了于是在负样本的时候选择最难的那些样本,和ITC配合。hard negatives(难上加难)
- MLM:Bert利用的完形填空,特别好用,各种论文证明了它的有效性
ps: 做了两次 forward,训练时间很长(多模态预训练时间长)
3.Momentum Distillation
Noisy web data,从数据的角度进行优化
主要是干扰了各种训练loss

文中这句话就能清楚知道,最后利用了MD是在MLM和ITC两个部分,因为有时候那个 gt 并不是最好的。
实验部分
- 4 M 和 12 M 的数据集(现在更多数据集了,不是一般人玩得动了= =)
总结
怎么从一个noisy data 学表征是一个很好的方向
VLMO
摘要
VR/VE/VQA
- 训练方法改进 —— 两阶段
- 模型改进——mixture of experts
主题
1.clip:双塔模型 + cos similarity = 大规模的 数据
缺点是交互太少了
2. 交互变成 transformer
缺点是嗯复杂
3.各个模态有各个模态的experts去解决,想要哪个要哪个
4.分阶段是因为 两个模态各自有自己非常大的数据集,想用!所以就先分阶段各自训练各自的encoder,用自己模态那边的数据集。(nlp用自己的,cv用自己的,多模态数据集没有这么大当时)
5.用的一个self attention 图像还是文本(不懂为什么这样效果好)
3. 分阶段训练图
图中,第二个阶段,冻住了self-attention(神奇的操作,有没有什么原理?)而且必须是第二个阶段冻住!(很多工作证明了,这里可以深挖)
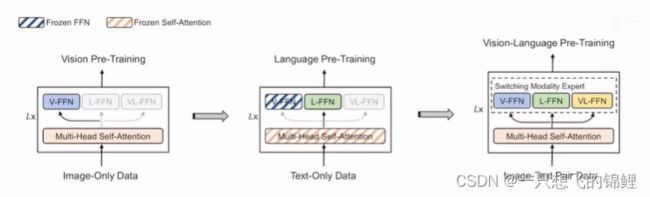
4. 很小的改动,就是 FFN 改成三种,效果就很好
总结
主要是灵活,它把每个模块拆分了,训练量更多比起ALBEF
BEIT-v3 : 下游任务更多了(多模态、单模态)- 变成了Encoder和Decoder。模型更大
Unimodality-Multimodality

维持计算量不变左边,
SA都不变,只有FFN才变区分不同的modality右边
BLIP
摘要
- 数据noisy怎么弄好和unify
- suboptimal (数据大能解决但是还是不好)- caption filter
- 左边借鉴了 ALBEF但是 SA借鉴了 VLMO
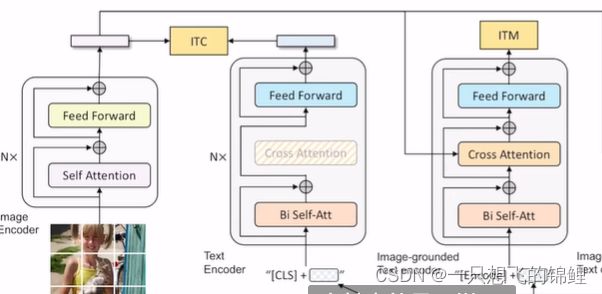
4. SA变了 为了生成 LM

5. decoder效果太好了,所以后面用它新生成的数据来加入训练,具体是设计了一个filter,选择到底是 gt好还是 生成的caption好。
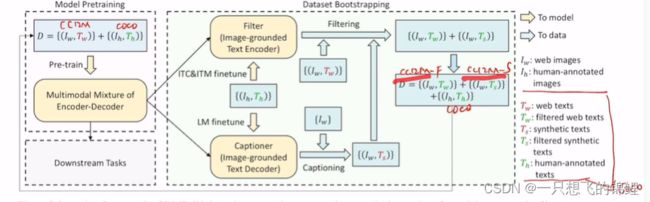
6. capfilter 很好,因为它相当于得到了一个生成更好数据的方法,是modal agonotic
COCA

看起来很像 ALBEF ,区别:
- 一开始就用 causal sa,为了少forward
- learned pooling
- 两个loss——一个是captionning(LM) 一个是 contrastive loss ITC
BEIT-v3
全部统一: 把图片也变成文字 (imglish),loss就能只用一个了——MLM loss
论文引言写的很好
总结
1.language interface:metalm、pali
2.generalist modal:模型监督

真卷:Unipercever