微服务生产实战-基于Prometheus的监控体系
Spring Cloud下基于Prometheus的监控体系
当线上部署了大量的微服务后, 就会有越来越多的以下问题:
1、如何快速知道某些服务实例下线?
2、如何快速知道某些服务内存、CPU等异常?
3、如何知道各个服务的请求量等信息?
4、如何排查对应的服务异常?
5、如何自定义监控元素和面板?
完整的监控体系是一套生产线部署的微服务所必须组成的部分
我们基于Prometheus+Grafana搭建线上的监控告警体系, Prometheus作为比较新的监控组件, 在Spring Cloud微服务体系中能够很好的集成和使用, 关于Promethues的描述和使用方式可以详见其官网. Spring Boot Actuator 提供了常用的监控和检查接口, 如health、env、info等, 我们通过集成micrometer-registry-prometheus来增加prometheus端点接口.
监控告警结构设计
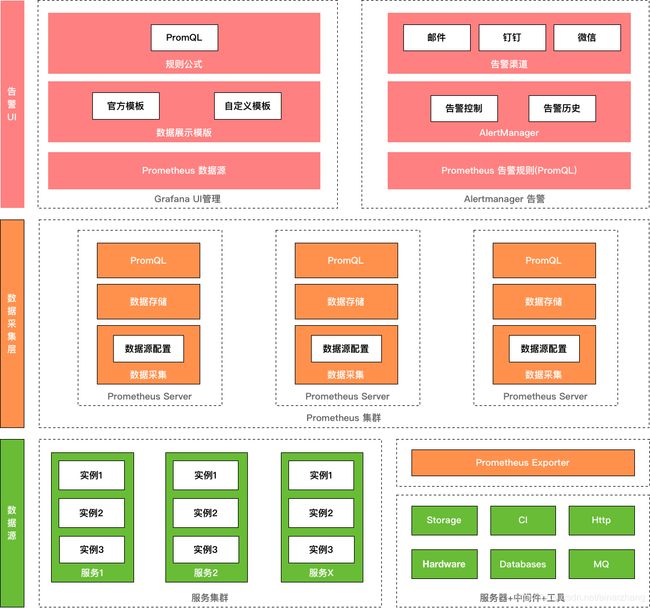
服务提供prometheus端点
Spring Cloud项目需要集成如下组件来支持提供prometheus端点:
org.springframework.boot
spring-boot-starter-actuator
io.micrometer
micrometer-registry-prometheus
并通过yml或者properties开启prometheus接口:
management.endpoint.web.exposure.include=info, health, prometheus普通的服务即可通过访问服务的actuator/prometheus接口查看监控信息, 如果是Zuul网关的请求监控, 我们可以通过如下方式设置URI监控, 但是注意下当你的zuul并发请求量过大时, 要注意URI监控的性能问题.
public class ZuulWebMvcTagsProvider implements WebMvcTagsProvider {
@Override
public Iterable getTags(HttpServletRequest request, HttpServletResponse response, Object handler, Throwable exception) {
return Tags.of(WebMvcTags.method(request), getUri(request), WebMvcTags.exception(exception),
WebMvcTags.status(response));
}
@Override
public Iterable getLongRequestTags(HttpServletRequest request, Object handler) {
return Tags.of(WebMvcTags.method(request), getUri(request));
}
private Tag getUri(HttpServletRequest request) {
return Tag.of("uri", request.getRequestURI());
}
} 线上额外备注:
因为Spring Boot Actuator提供了较多的接口, 一般生产环境涉及到权限和安全等, 会关闭到一些接口, 仅配置一些我们想要开放的普通权限接口, 这里我列举一个简单的配置供参考:
# 仅开启最小需要的接口
management.endpoint.web.exposure.include=info, health, prometheus
management.endpoint.jmx.exposure.include=info, health, prometheus
management.endpoint.health.enabled=true
management.endpoint.health.show-details=always
生产可以关掉health里面的所有其他监控, 如果开启的话, 服务里面链接的第三方中间件每次都会去检查, 比如kafka, mysql, redis等, 可能会导致一次的health检查过于重. 如果认为需要某个中间件是服务必须的功能检查也可以单独开启, 不过整体建议还是通过中间件独立的监控进行处理, 具体示例如下:
management.health.defaults.enabled=false
management.health.redis.enabled=true. # 单独开启health中的redis监控
management.health.binders.enabled=false
服务启动好后, 我们可以通过health检测服务在线状态, 通过prometheus接口监控jvm、请求量等信息, 当然也可以自定义监控指标到prometheus接口, 非常方便. 为了描述方便, 我们这里假设所有服务实例不通过docker等容器, 直接部署在物理虚拟机上, 这样我们可以通过类似链接直接访问到端点: 如http://192.168.1.1:8080/actuator/health
中间件提供prometheus端点
不管是监控服务器CPU本身还是类似kafka、Redis这种中间件, 要想通过prometheus进行采集, 需要部署官方提供的exporter实例, 用于将数据源信息采集为prometheus能够识别的格式.
prometheus官方提供了非常多的exporter: https://prometheus.io/docs/instrumenting/exporters/, 如果没有你想要的, 也可以自己定制.
服务分批采集
prometheus通过服务提供的actuator/prometheus的http接口采集数据信息, 每个采集规则需要配置多久轮询一次, 如果大量的服务通过一个prometheus实例进行采集就会出现监控机器过于繁忙的问题, 所以如果现在存在大量的微服务, 可以考虑将不通服务进行分组配置到不通的prometheus里面. 同一个prometheus为了更好错开不通实例的请求, 每个服务的实例刷新时间尽量保证不存在共同期, 比如采用2、3、7、11等这种容易错开的轮询秒. 在这种多个prometheus采集的情况, 也可以通过互相进行监控实例的监控告警. Prometheus官方提供了高可用的方案, 我们这里仅设计出分批采集和互相监控的图:

Grafana配置对应的监控面板
prometheus自己也提供了dashboard, 不过过于简单, 我们通过grafana设置更加丰富的监控面板. 1、在Grafana上面创建部署的所有prometheus数据源
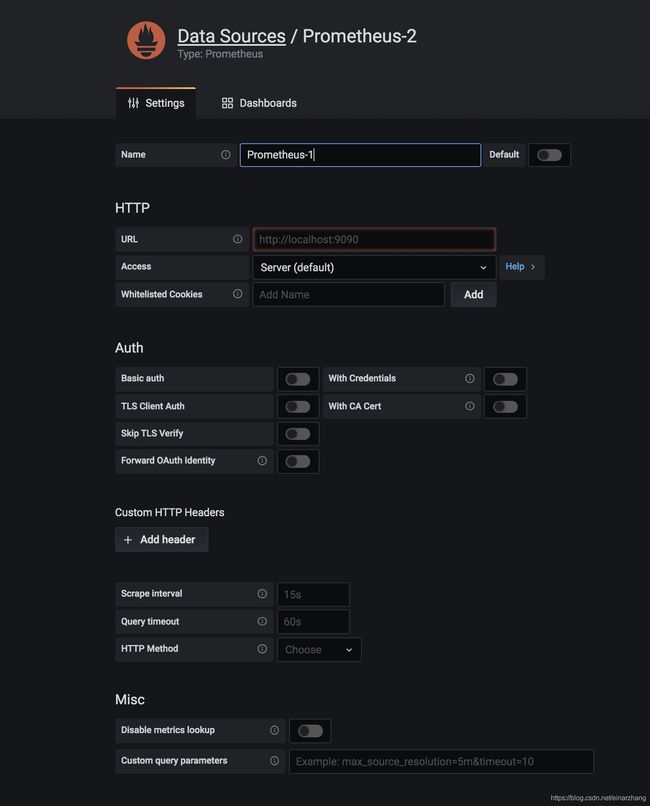
2、在Grafana官方找到对应的prometheus监控模板, 基本上想要的都有, 当然也可以自定义模板, 更加灵活.
3、模板导入到Grafana, 然后将数据源设置为prometheus数据源即可. 你也可以对单个面板进行数据源设置
4、通过PromQL进行个性化面板设计, 比如常见的5XX监控, 请求量环比增长等
AlertManager告警
Prometheus官方推荐Alertmanager作为告警服务, 我们这里就不设置Grafana的告警, 仅通过alertmanager进行管理. 具体使用方式详见官网AlertManager, 这里我们简单说下告警规则的大致配置:
groups:
- name: Instances
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
# Prometheus templates apply here in the annotation and label fields of the alert.
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.'
summary: 'Instance {{ $labels.instance }} down'
alert:告警规则的名称。
expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
整个告警的核心就是在配置expr, 丰富的语法可以让你构造很多类型的告警规则
如果要将通知告警到钉钉或者微信, 需要部署对应的发送服务, Github上有开源的可以直接部署, 部署后只需要在alertmanager这里配置webhook地址即可. 也可以自己编写接收发送服务.