GPT系列学习笔记:GPT、GPT2、GPT3GPT系列学习笔记:GPT、GPT2、GPT3
内容整理自:【白嫖攻略】国内如何免费使用Chat GPT?两个小时快速啃透,引爆AI聊天机器人领域
大家有时间还是去看唐宇迪大佬讲,才一个半小时,收获很多~~~
总结
GPT、GPT2、GPT3的共同点是其结构都基于Transformer的Decoder层。
区别在于:
模型一个比一个大,数据量一个比一个多。
GPT为常规语言模型
GPT2卖点指向zero-shot
GPT3卖点指向Few-shot
GPT: Improving Language Understanding by Generative Pre-Training
论文:链接(使用通用的预训练模型来提升语言理解能力)
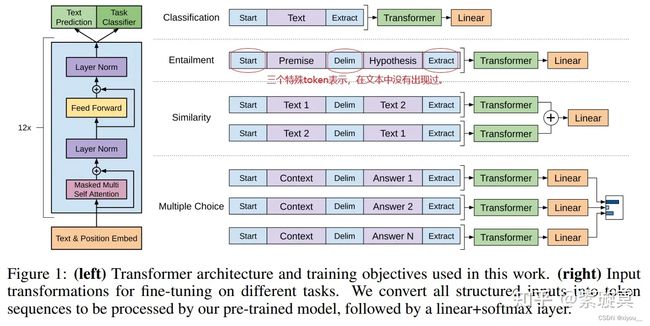
目前NLU(Natural Language Understanding)方向的局限性:有标签的数据相对较少,限制了模型性能的提升。
- 基本思想:
先在没有标签的数据集上训练预训练语言模型,再在子任务上微调(自监督学习)。与之前的任务(word2vec也是在没有标签的数据集上预训练语言模型)不同,微调时只需要改变模型输入的形式,而不需要对模型结构进行改变。模型结构选用的是12层的Transformer的decoder。
- 无监督的预训练过程
给定一个序列,使用一个标准的语言模型目标来最大化下面的似然函数:
其中,为上下文窗口大小, 代表模型参数。即给定一个模型(GPT中指的是Transformer decoder),给定前个词,预测当前词。
预训练阶段是没有Start,Delim,Extract这些这些特殊符号的,模型通过微调阶段学习这些特殊token。
- 有监督的微调阶段
有标签的数据集上每个样本包含一个句子 和对应的标签 。将 输入预训练模型,获取decoder最后一层的 对应的编码 ,将它传入一个额外的线性输出层来预测:
最大化下列的目标函数:
在微调阶段引入预训练任务,效果更佳:
其中, λ \lambda λ为可调节的超参数。
GPT和BERT的区别:①GPT使用的Transformer的Decoder层(目标函数为标准的语言模型,每次只能看到当前词之前的词,需要用到Decoder中的Masked attention),BERT使用的Transformer的Encoder层(目标函数为带[Mask]的语言模型,通过上下文的词预测当前词,对应Encoder);
为什么GPT的性能比BERT差:①GPT预训练时的任务更难(BERT的base就是为了和GPT对比,参数设定几乎一样);②BERT预训练用的数据集大小几乎是GPT的四倍;
GPT-2: Language Models are Unsupervised Multitask Learners
论文:链接(语言模型是无监督的多任务学习器)
计了四个量级的模型
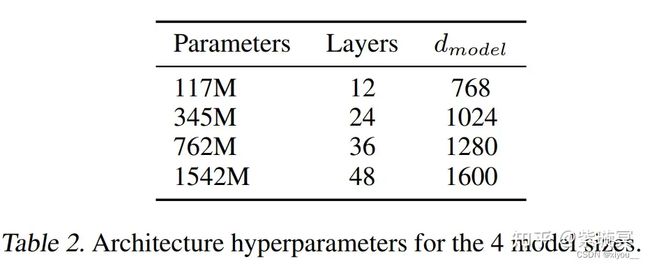
相较于GPT的改进:更大的数据,更大的模型,将卖点指向zero-shot。
能做的task:阅读理解、翻译、总结、问答。
- 无监督的预训练阶段
同GPT
- zero-shot的下游任务
下游任务转向做zero-shot而放弃微调,相较于GPT,出现一个新的问题:样本输入的构建不能保持GPT的形态,因为模型没有机会学习Start,Delim,Extract这些特殊token。因此,GPT-2使用一种新的输入形态:增加文本提示,后来被称为prompt(不是GPT-2第一个提出,他使用的是18年被人提出的方案)。
For example, a translation training example can be written as the sequence (translate to french, English text, french text). Likewise, a reading comprehension training example can be written as (answer the question, document, question, answer).
GPT-3: Language Models are Few-Shot Learners
论文:链接
GPT-3的可学习参数达到1750亿,是之前的非稀疏语言模型的10倍以上,并在few-shot的设置上测试它的性能。对于所有子任务,GPT-3不做任何的梯度更新或者是微调。GPT-3的模型和GPT-2一样。

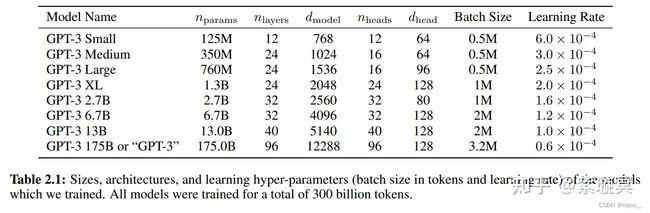
设计了8个不同大小的模型
- few-shot
GPT-3是不做梯度更新的few-shot,即下图的左下。将一些有标签的样例放在预测文本的上下文。

- 数据集的生成
对抗学习(将GPT2数据集中的样本作为正例,CommonCrawl数据集中的样本作为负例,训练一个线性分类模型,然后对于CommonCrawl中的其他样本,去预测它属于正例还是负例,如果属于正例,则采纳他作为GPT3的数据集)+去重(lsh)
lsh算法:主要用于大数据规模时,计算两两之间的相似度。基本思想:基于一个假设,如果两个文本在原有数据空间是相似的,那么他们分别经过哈希函数转换以后的他们也具有很高的相似度。
- 局限性
- 文本生成上的效果较弱。
- 结构和算法的局限性。只能看当前词之前的信息(decoder);每个词都均匀地预测下一个词,没有哪一个词更重要。
- 只学习文本。未涉及其他模态
- 样本的有效性不够
- 无法解释