从集异壁理解ChatGPT的成功与局限

终其一生,人类都在探寻认知这个世界的方式。
音乐、绘画和人工智能是三个看似无关的领域,但是它们都是人类这次伟大尝试的绚烂明珠。
在这三个领域,追根溯源,底层的结构,都简洁且美丽。
图片由Midjourney生成,prompt:“Through a picture describing the underlying commonality of music, painting and computer, it shows that they all describe the world by composing complex structures from simple structures(通过一幅描述音乐、绘画和计算机潜在共性的图片,表明它们都是通过简单结构组成复杂结构来描述世界的)”
《哥德尔·艾舍尔·巴赫》这本书,便是揭示了这个道理,复杂结构是如何构造出来的,引出了一个关键概念,就是递归,不断不断地指向中心,简单叠加简单,创造复杂。
如果你开始记住这个概念,那么我们可以一起打开《哥德尔·艾舍尔·巴赫》这本书开启一段旅程。
了解这些,你会更加深刻地理解:
ChatGPT 为什么成功?
ChatGPT 最大的局限在哪里?
(以下为文因互联鲍捷博士在腾讯云TVB组织AI读书分享会上的演讲,分享书为《哥德尔·艾舍尔·巴赫》)
![]()
这本书是1979年发布的,在目前我们都非常关注代表前沿的ChatGPT时,或许有人会问,为什么一本1979年的书仍然有意义呢?
本书中有一章的名字叫做《G弦上的咏叹调》,里面用很长篇幅探讨了人类在不同领域中的创造,包括音乐、绘画以及我们的计算机科学。在这些创造中,作者发现了一些核心的共性,让我们感到神奇而美妙。
因此,在阅读侯世达写的这本书时,我获得了许多新的思考。尤其是结合书中所提及的观点,再审视当今这个ChatGPT,更激发了我更多的思考。今天与大家分享阅读过程中的一些收获。
01
万物合一——音乐、绘画、计算机
侯世达在 1979 年写这本书时人工智能处于第一个冬天,连第二个春天还没到来。
即使在人工智能第一个春天时,也没有机器学习、深度学习、知识图谱,后来知道的所有的这一切东西都没有。
在1979年的时候,人们普遍认为人工智能是一种形式化的逻辑系统。然而,随着时间的推移,这种看法被证明是有历史局限的。尽管如此,其中有一些看法至今仍未被突破,例如人工智能到底是什么。
人工智能是关于知识的科学,但每个时代都有自己不同的知识表达方法,因而均对知识表达的边界和知识表达的能力有理论相关的深刻认知。这些认知甚至在计算机科学产生出来前就存在了,所以那些认知本身并没有被突破。
要理解今天的人工智能系统,我们必须回溯到40年甚至60年前。去回答“GPT为什么如此成功?GPT到底有哪些边界?”这些让人们非常好奇问题。
坦白说,对于上述问题,我并没有答案。在阅读这本书的过程中,我做了一些大胆的猜想,但它们仍需验证。整本书的内容虽然长达1000页,几乎可用作防身武器,但我认为可以用庄子的话来概括它:“吾生也有涯,而知也无涯”。
也就是说,如何用有涯的资源去表达无涯的知识。

这本书从头到尾引领我们游览了多个领域,包括了巴赫的音乐、艾舍尔的绘画以及其他诸多内容。音乐本质上就是一种符号体系,与我们的大脑认知结构密切相关。因此,从自然语言处理的角度来看,音乐实质上就是另一种自然语言。当作者讲到巴赫的音乐时,提到了其中一段副歌,这是一种循环的音乐,被称为国王的音乐。它一开始是一种节奏,然后是一个中间的调,最后回到了开始的部分。这部分论证使作者想到艾舍尔的画作,尤其是他的名作《瀑布》,通过一系列视觉错觉的手法,创造了水从上往下流,最终回到原点的效果,艾舍尔因此画了许多类似的作品。
无论是音乐还是绘画,都拥有一种类似的结构,即在某一点上回到原点。我们发现世界上大多数复杂的事物最终都存在这样一种被称为“自指”的结构。
02
生也有涯——万物与底层结构
在我攻读研究生期间,尽管我研究的领域是人工智能,但我的应用研究方向却是生物学,尤其是在蛋白质基因和基因表达方面的研究。我曾经花费了很长时间来研究这个领域,因为我们人类只有两万多个基因,却需要表达数万种蛋白质,这些蛋白质数量甚至可以达到几十万,从而支撑着我们每个人独特的外貌和形态。
这种编码能力并不仅仅只存在于人类,事实上,我们每个人的身体中约有三分之一是蘑菇,这意味着我们的基因中也有三分之一是与蘑菇相同的。这是一件非常神奇的事情,因为我们的生物可以通过如此少量的基因,演化出世界上各种看起来独特的生物形态。
那么,如何通过有限的基因序列编码出无限的表现型呢?其实这就是基因的奇妙之处,在编码过程中,基因利用了一个非常复杂的表达网络来完成这一任务。这个过程就像音乐和绘画一样,具备了一种自我表达的能力。
在更基础的物理层面上,也可能存在着这样的机制。在理论物理学中,有一种称为费曼图的东西,它描述了粒子之间的相互转换。即使是真空,我们所处的这个世界也不是真实的,因为它不停地涌现出粒子,并在几乎瞬间消失。这些粒子会相互吸收、分裂,最终会产生新的粒子。费曼图是一种描述粒子运动的图形,通过它我们可以看到用有限的61种基本粒子构造出万物的算法结构,这也是自指存在的过程。

在物理世界、生物世界以及人类的精神世界中,存在一个普遍的现象,即我们需要利用有限的基础结构来表达无限的知识。这种现象的核心在于递归,是一种能够作用于自身的法则,我们称它为递归。
本书的核心内容在于讲解如何构建逻辑体系。一旦我们掌握了递归的能力,就可以表达非常复杂的结构,这是人工智能领域一直在探索的成功核心问题之一。就是我们是否能够找到一种成本低、效率高、计算速度快的递归方法,与经过45亿年自然进化而产生的人类智慧进行一场PK。
其实到目前为止没有找到,虽然有人会问ChatGPT不是吗?不是的。就像我们每个人在中小学时都学过的四则运算,其中加法和减法就是典型的递归系统,可以通过一条简单的公理来描述。如果想要建立一个不太严谨的数学体系,可能只需要一条公理就可以了,例如加法和减法。在这本书中,我们可以通过基础公理来建立理论体系,进而建立整个数学的运算体系。
但如果想建立一些更加严谨的数学体系,就需要更多的公理,例如自然数。我们需要通过多条公理来描述自然数,例如1+1=2,2+1=3等等。虽然看起来很简单,但是如果要非常严谨地描述,可能需要5条公理才能做到。
数学代数并不像算数那样简单,那么更加复杂的数学是否能够被严谨地描述呢?大家可能听说过罗素悖论,其中最经典的表达方式是理发师悖论。一个理发师发誓说不会为自己刮胡子的人刮胡子,但最后他却不知道要为自己刮胡子还是不刮胡子。这个问题很难被解决,但是罗素通过集合论的方式最终解决了这个悖论。虽然这个问题在数学上比较难懂,这里不详细阐述。

总之,罗素在1900年前后提出了一个观点,即科学可以被形式化,通过将科学转化为一种逻辑结构,我们可以实现更强大的理性,不需要使用非常模糊的自然语言。希尔伯特在1900年提出了他著名的23个问题,这是理性主义的黄金时代。那个时候,物理学正在突飞猛进,1905年爱因斯坦发现了狭义相对论。
那时,人们相信所有的问题都是物理问题,而所有的物理问题都是数学问题。如果我们能够形式化地描述所有的数学问题,那么我们就能实现人类整个知识体系的形式化,即实现完全无漏洞,甚至可以自动化执行人类的认知能力。当时人们相信这一点是可以达到的。
在这种思想的影响下,一系列科学家开始探索。一开始,他们仅仅只是为了寻找理性的星辰大海,但这一切工作却莫名其妙地导致了一种奇怪的机器——计算机的发明。图灵和丘奇是两位著名的计算机科学家,他们分别发明了图灵机和Lambda演算。作为奥地利人的哥德尔是位杰出的数学家,从数学角度证明了两个不完备定理。这三个人(图灵、邱奇、哥德尔)几乎在同一时间证明了同样的事情,就是人类的理性是有边界的。
哥德尔证明,不管你有多少公理,最终总有一些问题,既没有办法证明,也没有办法证伪。即使你把全部的知识都公理化了,也一定会有一个定理,是没有办法证明的,也没有办法证否的,你就是不知道。因为人类的认知边界是有限的,甚至可以说整个世界的理性都有不可逾越的边界。在物理学上,我们还没有很好的解释,但是在数学上,我们证明了有一些东西是无法计算的。无论你用尽全宇宙的能量去计算,你都无法得出结果,因为你做不到。
03
知也无涯——ChatGPT与未来
ChatGPT 为什么能够取得成功呢?其中一个重要的原因在于它的开发者们无意中利用了“认知剩余”的概念。
这是早在十多年前,克莱•舍基在他的著作《认知盈余》中提出的一种理论,即我们想要构建一个庞大的协作系统去改变世界,就需要考虑每个人的认知剩余,并最终汇聚起来。因为大多数时间,我们每个人都在做出决策,比如,你在过马路时遇到了红灯,你会停下来,这就是一个决策。
那么我们如何将日常生活中积累下来的大量认知剩余聚集起来呢?ChatGPT 的出现为我们提供了一个全新的可能性。Linus曾有句名言:“Talk is cheap, show me the code.”,而 ChatGPT 出现后,这句话也许可以改为:“Code is cheap, show me the talk.”。因为现在我们可以通过和 ChatGPT 对话来获取信息,而无需编写复杂的代码。

有一个历史梗“每开除一名语言学家,语音识别系统的错误率降低一个百分点”。今天其实也可以说类似的话,就是每开除一个计算语言学家,机器的识别率就会上升。也就是说,ChatGPT已经发生了很多变化。这也是一些人认为ChatGPT非常神奇的原因,他们认为它一定找到了某些东西,因此会问ChatGPT是否具有意识?是否真正超越了人类的自我学习能力?然而,我强烈不认同这种观点。如果你仔细观察 ChatGPT 的成功之处,就会发现,尽管它在进行长程知识的联想,但实际上它是在利用大量无标注语料库中隐藏的监督指令。我们人类的语言中存在许多这种监督指令,比如,当我说“good morning在中文中的意思是早上好”,当中“在中文中的意思”这个连接词,就是一个监督指令。
事实上,在语言当中,许多上下文相关任务都存在这样的监督指令。因此,ChatGPT 通过阅读大量文本,找到并汇总这些隐藏且非完全形式化的指令,进行泛化。这是人类在人工智能领域第一次能够大规模地找到并应用隐藏在自然语言文本中的监督指令。
图片由Midjourney生成,prompt:“In a bright office, a robot uses pincer hands to pluck data from financial statements, each floating in midair(在一间明亮办公室里,机器人用钳子似的手从财务报表中提取数据,每个数据漂浮在半空中)”
我们以前经常说,“有多少人工就有多少智能”,因为在进行数据标注时,人工是隐藏在数据标注中的,这本身就是一种人工监督。但现在,ChatGPT 通过大规模无标注语言模型进行训练,我认为,这是 ChatGPT 成功最核心的因素之一。不过,这里的“无标注”并不是真正的无监督学习,依然是有监督的,只是这个监督隐藏在文本里。当然,还有一些更加明显的人类监督,如指令学习和RLHF。
ChatGPT带来了人工智能的第二次突破,即认知剩余产生的监督知识。这次的突破与历史上首次突破有关,那就是机器学习的突破,也称为认知剩余产生的数据。首次突破是由于互联网的出现而引起的,因为互联网带来了大量的在线数据,使得我们第一次能够利用这些数据来获取认知剩余。
这次ChatGPT 带来的突破不仅能够收集认知剩余带来的数据,还可以收集由认知剩余产生的监督知识。这些知识包括大量未标注的自然语言数据,这些数据实际上是人类智慧的结晶。现在,我们可以使用 ChatGPT 来提取这些隐藏的监督信息,进而产生更加丰富的结构。
有人可能会问,什么是数据?什么是知识?这又回到了本书最核心的主题,即递归结构。当我们询问 ChatGPT 时,经常会发现它在基本的四则运算上有时偏离了实际,有时是正确的,有时是错误的。
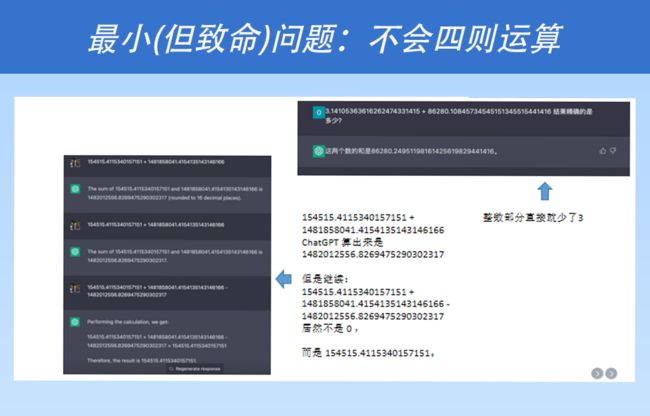
这是因为 ChatGPT 作为一个大型语言模型,迄今为止还不能很好地在其原生的语言模型内部学习递归结构。对于所有其他需要进行复杂递归结构表示的事物,ChatGPT 的表现都不太好。因此,这给我们提供了一个启示,即如果我们未来想要进行第三次突破,那么我们就应该考虑如何更好地实现低成本的递归结构学习。我认为,谁能够做到这一点,谁就能够取得比 ChatGPT 更令人惊叹的成就。
![]()

