YOLOv3
YOLOv3
-
-
- 论文信息
-
- 论文标题:
- 论文作者:
- 收录期刊/会议及年份:
- 论文学习
-
- YOLOv3 网络架构:
- YOLO 输出特征图解码(前向过程):
- 训练策略与损失函数(反向过程):
- 精度与性能:
-
论文信息
论文标题:
YOLOv3: An Incremental Improvement
论文作者:
Joseph Redmon, Ali Farhadi
收录期刊/会议及年份:
CVPR, 2018
论文获取地址
论文学习
YOLOv3 网络架构:
Darknet-53:
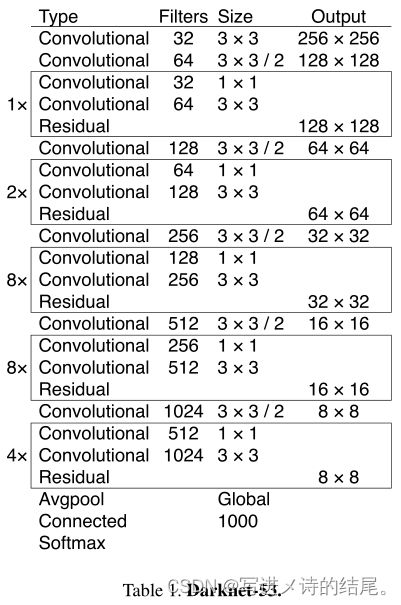
backbone 部分由 YOLOv2 时期的 Darknet-19 进化至 Darknet-53,加深了网络层数,引入了 Resnet 中的跨层加和操作。原文列举了 Darknet-53 与其他网络的对比:
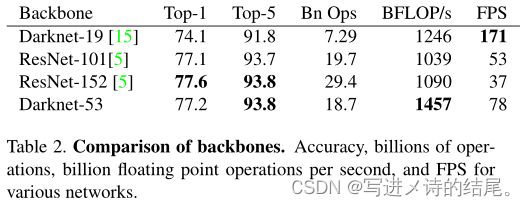
Darknet-53 每秒能处理 78 张图,比 Darknet-19 慢不少,但是比同精度的 ResNet 快很多。YOLOv3 依然保持了高性能。
这里解释一下 Top1 和 Top5:模型在 ImageNet 数据集上进行推理,按照置信度排序总共生成 5 个标签。按照第一个标签预测计算正确率,即为 Top1 正确率;前五个标签中只要有一个是正确的标签,则视为正确预测,称为 Top5 正确率。
YOLOv3 使用 Darknet-53 作为整个网络的骨干,在论文中并未给出全部的网络结构。根据代码,整理数据流图如下:
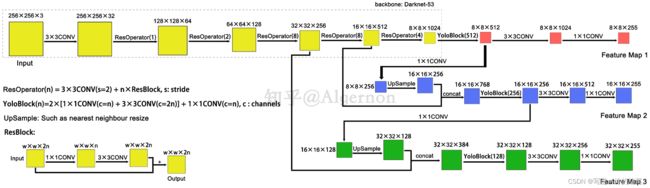
网络结构解析:
- YOLOv3 中只有卷积层,通过调节卷积步长来控制输出特征图的尺寸,所以对于输入图片的尺寸没有特别限制。在流程图中,输入图片以 256*256 作为样例。
- YOLOv3 借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图则用来检测小尺寸物体。特征图的输出维度为 N×N×[3×(4+1+80)],N×N 为输出特征图的格点数,一共 3 个 Anchor 框,每个框有 4 个预测框数值 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th,1 为预测框置信度,80 为物体类别数。所以特征图的输出维度为 8×8×255。
- YOLOv3 总共输出 3 种特征图,第一种特征图下采样 32 倍,第二种特征图下采样 16 倍,第三种特征图下采样 8 倍。输入图像经过 Darknet-53(无全连接层),再经过 YoloBlock 生成特征图,此时得到的特征图一方面经过 3*3 卷积和 1*1 卷积之后生成特征图一;另一方面经过 1*1 卷积后进行上采样,得到的特征图再与 Darnet-53 网络的中间层输出结果进行拼接,产生特征图二。同样的循环之后产生特征图三。
- concat 操作与加和操作的区别:加和操作来源于 ResNet 思想,将输入的特征图与输出的特征图对应维度进行相加,即 y = f ( x ) + x y=f(x)+x y=f(x)+x;而 concat 操作源于 DenseNet 网络的设计思路,它将特征图按照通道维度直接进行拼接,例如 8*8*16 的特征图与 8*8*16 的特征图拼接后生成 8*8*32 的特征图。
- 上采样层(UpSample):作用是将小尺寸特征图通过插值等方法,生成大尺寸特征图。例如使用最近邻插值算法,将 8*8 的特征图变换为 16*16。上采样层不改变特征图的通道数。
YOLOv3 的整个网络吸取了 Resnet、Densenet、FPN 的精髓,可以说是融合了目标检测当前业界最有效的全部技巧。
YOLO 输出特征图解码(前向过程):
根据不同的输入尺寸,会得到不同大小的输出特征图,以上图中输入图片 256 × 256 × 3 为例,输出的三种特征图分别为 8 × 8 × 255、16 × 16 × 255、32 × 32 × 255。在 YOLOv3 的设计中,每个特征图的每个格子都配置 3 个不同的先验框,所以三种特征图可以 reshape 为 8 × 8 × 3 × 85、16 × 16 × 3 × 85、32 × 32 × 3 × 85,这样更容易理解,在代码中也是 reshape 成这样之后更容易操作。
三种特征图就是整个 YOLOv3 输出的检测结果,检测框位置(4维)、检测置信度(1维)、类别(80维)都在其中,加起来正好是 85 维。下面详细描述怎么将检测信息解码出来。
先验框:
在 YOLOv1 中,网络直接回归检测框的宽和高,这样做效果有限。所以在 YOLOv2 中,改为了回归基于先验框的变化值,这样网络的学习难度降低,整体精度提升不小。YOLOv3 沿用了 YOLOv2 中关于先验框的技巧,并且使用 k-means 对数据集中的标签框进行聚类,得到类别中心点的 9 个框作为先验框。在 COCO 数据集中(原始图片全部 resize 为 416 × 416),九个框分别为 (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326),顺序为 w × h。
注意:先验框只与检测框的 w、h 有关,与 x、y 无关。
检测框解码:
有了先验框与输出特征图,就可以解码检测框的 x,y,w,h。
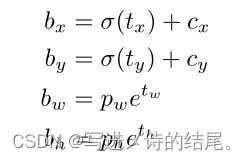
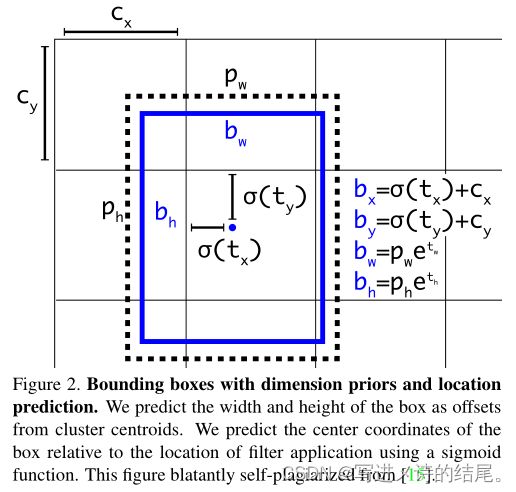
如上图所示, σ ( t x ) , σ ( t y ) σ(t_x), σ(t_y) σ(tx),σ(ty) 是基于矩形框中心点所属格点左上角坐标的偏移量,σ 是激活函数,论文中作者使用的是 sigmoid, p w , p h p_w, p_h pw,ph 是先验框的宽和高,通过上述公式能够计算出实际预测框的宽和高( b w , b h b_w, b_h bw,bh)。
举个具体的例子,假设对于第二种特征图 16 × 16 × 3 × 85 中的第 [5,4,2] 维,上图中的 C y C_y Cy 为 5, C x C_x Cx 为 4,第二种特征图对应的先验框为 (30×61),(62×45),(59×119),prior_box 的 index 为 2,那么取最后一个(59,119)作为先验 w 和先验 h。这样计算之后的 b x , b y b_x, b_y bx,by 还需要乘以特征图二的采样率 16,以得到真实检测框的 x,y。
检测置信度解码:
物体的检测置信度在 YOLO 设计中非常重要,关系到物体检测的正确率与召回率。置信度在输出的 85 维中占固定一维,由 sigmoid 函数解码即可,解码之后的数值在区间 [0,1] 中。
类别解码:
COCO 数据集有 80 个类别,所以类别数在 85 维的输出中占了 80 维,每一维独立代表一个类别的置信度。使用 sigmoid 激活函数替代了 YOLOv2 中的 softmax,取消了类别之间的互斥,可以使网络更加灵活。
三种特征图一共可以解码出 8 × 8 × 3 + 16 × 16 × 3 + 32 × 32 × 3 = 4032 个 box 以及相应的类别和置信度。这 4032 个 box 在训练和推理时,使用的方法不一样。
- 训练时,4032 个 box 全部送入打标签函数,进行后一步的标签以及损失函数的计算。
- 推理时,选取一个置信度阈值,过滤掉低于阈值的 box,再经过非极大值抑制(NMS),就可以输出整个网络的预测结果了。
训练策略与损失函数(反向过程):
YOLOv3 的训练策略尤为重要,深刻理解 YOLOv3 之后,训练策略总结如下。
训练策略:
- 预测框一共分为三种情况:正例(positive)、负例(negative)、忽略样例(ignore)。
- 正例:任取一个 ground truth,与 4032 个框进行 IoU 计算,IoU 值最大的预测框即为正例,并且一个预测框只能分配给一个 ground truth。例如第一个 ground truth 已经匹配了一个正例检测框,那么下一个 ground truth 就在余下的 4031 个检测框中寻找 IoU 值最大的框作为正例,ground truth 的先后顺序可忽略。正例产生置信度 loss、检测框 loss、类别 loss。预测框为对应的 ground truth box 标签(需要反向编码,使用真实的 x、y、w、h 计算出 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th);类别标签对应类别为 1,其余类别为 0;置信度标签为 1。
- 忽略样例:正例除外,与任意一个 ground truth 的 IoU 值大于阈值(论文中使用 0.5)的预测框,则为忽略样例,忽略样例不产生任何 loss。
- 负例:正例除外(与 ground truth 计算后 IoU 值最大的检测框,但是 IoU 小于阈值,仍为正例),与全部 ground truth 的 IoU 都小于阈值(0.5)的检测框,则为负例。负例只有置信度产生 loss,置信度标签为 0。
Loss函数:
特征图一的损失函数抽象表达式表示如下:

YOLOv3 的 Loss 为三种特征图的 Loss 之和:
L o s s = l o s s N 1 + l o s s N 2 + l o s s N 3 Loss = loss_{N_1} + loss_{N_2} + loss_{N_3} Loss=lossN1+lossN2+lossN3
- λ \lambda λ 为权重常数,控制检测框 loss、obj置信度 loss、noobj置信度 loss 之间的比例,通常负例的个数是正例的几十倍以上,可以通过权重超参控制检测效果。
- 1 i j o b j 1_{ij}^{obj} 1ijobj 若为正例,则输出1,否则为0; 1 i j n o o b j 1_{ij}^{noobj} 1ijnoobj 若为负例,则输出1,否则为0;忽略样例都输出 0。
- x、y、w、h 使用 MSE 作为损失函数,也可以使用 smooth L1 loss(出自 Faster R-CNN)作为损失函数。smooth L1 可以使训练更加平滑。置信度、类别标签由于是 0,1 二分类,所以使用交叉熵作为损失函数。
训练策略解释:
ground truth 为什么不按照中心点来分配对应的预测 box?
- 在 YOLOv3 的训练策略中,不再像 YOLOv1 那样,每个 cell 负责中心点落在该 cell 中的 ground truth。原因是 YOLOv3 一共产生 3 个特征图,这 3 个特征图上的 cell,中心是有重合的。训练时,可能最契合的是特征图一的第 3 个 box,但在推理时可能特征图二的第 1 个 box 置信度最高。所以 YOLOv3 的训练不再按照 ground truth 中心点来分配指定的 cell,而是根据预测值寻找 IoU 最大的预测框作为正例。
- 笔者实验结果:第一种,ground truth 先从 9 个先验框中确定最接近的先验框,这样可以确定 ground truth 所属第几个特征图以及第几个 box 位置,之后根据中心点进一步分配;第二种,全部 4032 个输出框直接与 ground truth 计算 IoU,取 IoU 值最高的 cell 来分配 ground truth。第二种计算方式的 IoU 数值往往要比第一种高,w、h、x、y 的 loss 较小,网络可以更加关注类别和置信度的学习;其次在推理时,是按照置信度排序,再进行 NMS 筛选,通过第二种训练方式,每次给 ground truth 分配的 box 都是最契合的 box,给这样的 box 置信度打 1 的标签更加合理,最接近的 box 在推理时更容易被发现。
YOLOv1 中的置信度标签是预测框与真实框的 IoU 值,在 YOLOv3 中为什么变成了 1?
- 置信度意味着该预测框是或者不是一个真实物体,这是一个二分类问题,所以标签用 1、0 来表示更加合理。
- 笔者实验结果:第一种,置信度标签取预测框与真实框的 IoU 值;第二种,置信度标签取 1。第一种在训练时,有些预测框与真实框的 IoU 值的极限就是在 0.7 左右,因此置信度就以 0.7 为标签,而置信度在学习时会产生一定的偏差,最后学到的数值可能是 0.5、0.6,假设推理时的激活阈值为 0.7,那么这个检测框就被过滤掉了。但是 IoU 为 0.7 的预测框,其实已经是比较好的学习样例了。尤其是 COCO 中的小像素物体,几个像素就可能在很大程度上影响 IoU 的计算,所以在第一种训练方法中,置信度的标签始终很小,无法很好的有效学习,导致检测召回率不高。此外,检测框趋于收敛,IoU 收敛至 1,置信度就可以学习到 1,这样的设想太过理想化。而使用第二种方法,召回率明显提升了不少。
为什么有忽略样例?
- 忽略样例是 YOLOv3 中的点睛之笔。由于 YOLOv3 使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图一的第三个 box,IoU 值高达 0.98;此时,恰好特征图二的第一个 box 与该 ground truth 的 IoU 值高达 0.95,也检测到了该 ground truth,如果此刻给其置信度强行打上 0 的标签,那么网络学习的效果会不理想。
- 笔者实验结果:如果给全部的忽略样例置信度标签打上 0,那么最终的 loss 函数会变成 L o s s o b j Loss_{obj} Lossobj 与 L o s s n o o b j Loss_{noobj} Lossnoobj 的拉扯,不管两个 loss 数值的权重怎么调整,网络预测要么趋向于大多数预测为负例,要么趋向于大多数预测为正例。而加入了忽略样例之后,网络才可以学习区分正负例。
优化器:
作者在文中没有提及优化器,Adam、SGD 等都可以用,github 上的 YOLOv3 项目中,大多使用 Adam 优化器。
精度与性能:

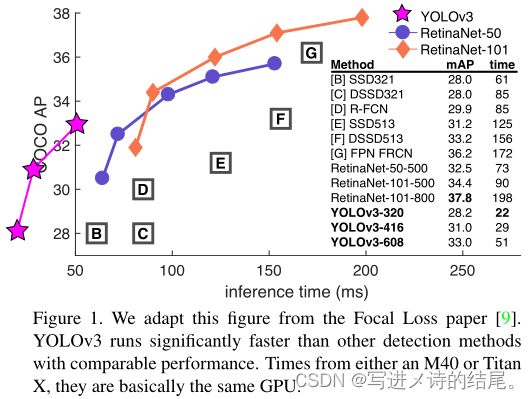
YOLOv3 的精度与 SSD 相比略有小优,与 Faster R-CNN 相比略有逊色,比 RetinaNet 差。但是速度上至少是 SSD、RetinaNet、Faster R-CNN 的 2 倍以上。输入尺寸为 320*320 的 YOLOv3,单张图片处理仅需 22ms,简化后的 YOLOv3 tiny 还可以更快。