【论文阅读笔记|AAAI2022】Unified Named Entity Recognition as Word-Word Relation Classification
论文题目:Unifified Named Entity Recognition as Word-Word Relation Classifification
论文来源:AAAI2022
论文链接:AAAI Press Formatting Instructions for Authors Using LaTeX -- A Guide (arxiv.org)
代码链接:https://github.com/ljynlp/W2NER
0 摘要
到目前为止,命名实体识别(NER)已经涉及到三种主要类型,包括平面(flat)、重叠(overlapped)(或嵌套(nested))和不连续(discontinuous)的NER,它们大多是单独研究的。最近,人们对统一NER的兴趣越来越大,即用一个单一模型同时处理上述三个工作。目前表现最好的方法主要是基于跨度和序列到序列的模型,但是,前者只关注边界识别,后者可能存在暴露偏差。
我们提出了一种新的替代方法,通过将统一的NER建模为词-词关系分类,即![]() 。
。
该体系结构通过有效地对实体词Next-Neighboring-Word(NNW)和Tail-Head-Word-* (THW-*)之间的关系进行建模,解决了统一NER的核心瓶颈。
- 在
中,统一的NER被建模为一个词对的2D网格。
- 然后,我们提出了多粒度的二维卷积,以更好地重新细化网格表示。
- 最后,使用一个协同预测器来充分推理词-词关系。
我们对14个广泛使用的基准数据集、flat、重叠的和不连续的NER(8个英语和6个中文数据集)进行了广泛的实验,其中我们的模型超过了目前所有性能最好的基线,推动了统一NER的最新性能。
1 引言
命名实体识别(NER)长期以来一直是自然语言处理(NLP)的一项基本任务,因为其广泛的基于知识的应用,如关系抽取(Wei等,2020;李等,2021b),实体链接(Le和Titov 2018;侯等,2020)等。NER的研究最初从flat NER (Lample等2016年;斯特鲁贝尔等2017年)到后来的overlapped NER (Yu等2020年;Shen等2021年),最近到discontinuous NER(Dai等2020年;李等2021a)。
- flat NER只是从文本中检测出提及的跨度及其语义类别
- 重叠的实体包含相同的token
- 不连续的实体包含不相邻的span
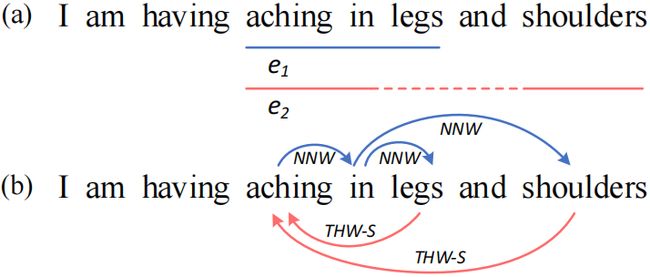
图1: (a)显示三种类型NER的示例。e1是一个flat实体,e1在“aching in”跨度上与不连续实体e2重叠。(b)我们将三个NER的子任务看为词与词的关系分类,Next-Neighboring-Word (NNW)关系表示一个词对连续联合的实体(例如,aching→in),Tail-Head-Word-* (THW-*) 关系意味着的实体的尾词连接头词(例如,legs→aching)作为一个实体“*”类型(例如,Symptom)。
以往的多类型NER方法大致可以分为四类: 1)序列标注,2)基于超图(hypergraph)的方法,3)序列到序列的方法,4)基于跨度(span)的方法。
- 大多数初始工作将NER形式化为序列标注问题(Lample等人2016年;郑等人2019年;唐等人2018年;斯特拉科夫等人2019年),为每个token分配一个tag。然而,很难为所有的NER子任务设计一种标记方案。
- 然后提出了基于超图的模型(Lu和Roth 2015;Wang和Lu 2018;Katiyar和Cardie 2018)来表示所有实体跨度,但这些实体在推理过程中存在虚假结构和结构模糊的问题。
- 最近,Yan等人(2021)提出了一个序列到序列(Seq2Seq)模型来直接生成各种实体,不幸的是,这可能会遭受解码效率问题和Seq2Seq架构的某些常见缺陷,例如,暴露偏差。
- 基于跨度的方法(Luan等人,2019年;Li等人,2021年a)是另一种用于统一NER的先进方法(SoTA),列举了所有可能的跨度并进行跨度级分类。然而,基于跨度的模型可以受到最大跨度长度的影响,并由于枚举的性质而导致相当大的模型复杂性。因此,设计一个有效的统一NER系统仍然具有挑战性。
现有的工作主要集中在如何准确识别实体边界,即NER的核心问题是flat问题。然而,在仔细考虑这三种类型NER的共同特征后,我们发现统一NER的瓶颈在于实体词之间相邻关系的建模。这种邻接相关性本质上描述了部分文本段之间的语义连通性,特别是重叠和不连续段的关键作用。如图1(a)所示,我们可以毫不费力地检测到“aching in legs”,因为它的组成词都是自然相邻的。但是,要检测出“aching in shoulders”的不连续实体,有效地捕捉“aching in”和“shoulders”的相邻节段之间的语义关系是必不可少的。
在此基础上,本文研究了一种新的词与词关系分类结构的统一NER形式,即![]() 。该方法通过有效地对实体边界识别和实体词之间的相邻关系进行建模来解决统一的NER问题。具体来说,
。该方法通过有效地对实体边界识别和实体词之间的相邻关系进行建模来解决统一的NER问题。具体来说,![]() 对两种类型的关系进行了预测,包括Next-Neighboring-Word (NNW)和the Tail-Head-Word-* (THW-*),如图1(b)所示。
对两种类型的关系进行了预测,包括Next-Neighboring-Word (NNW)和the Tail-Head-Word-* (THW-*),如图1(b)所示。
- NNW关系表示实体词标识,指示两个参数词在一个实体中是否相邻(例如,aching→in)
- THW-*关系解释实体边界和类型检测,显示两个参数词是否分别是“*”实体的尾部和头部边界(例如,, legs→aching, Symptom)。
在![]() 方案的基础上,进一步提出了统一NER神经框架的方法。
方案的基础上,进一步提出了统一NER神经框架的方法。
- 首先,使用BERT和BiLSTM提供上下文化的单词表示,在此基础上,我们构建了单词对的二维(2D)网格。
- 然后,我们设计了多粒度的二维卷积来细化词对表示,有效地捕获了近距离和远距离词对之间的交互。
- 最后,共同预测器最终解释词与词之间的关系,并产生所有可能的实体提及,其中biaffine和多层感知机(MLP)分类器是联合使用的互补利益。
我们对14个数据集进行了广泛的实验,包括2个英语和4个中文的flat NER数据集,3个英语和2个中文的重叠NER数据集,3个英语数据集的不连续NER数据集。与flat NER的12个基线、重叠NER的7个基线、不连续NER的7个基线相比,我们的模型在所有数据集上都取得了最好的性能,成为统一NER的新的SoTA方法。我们的贡献包括:
- 提出了一种创新的方法,将统一的NER描述为词与词之间的关系分类,其中实体的边界词和内部词之间的关系都被充分考虑。
- 开发了一个用于统一NER的神经框架,其中,我们提出了一种多粒度的二维卷积方法,以充分捕捉相近词和距离远的词之间的相互作用。
- 我们的模型在总共14个数据集上推动了目前SoTA的NER的表现。在总共14个数据集上的表现。
2. 关于NER的相关工作
序列标注方法
NER通常被认为是一个序列标注的问题,从预先设计的标记方案(例如,BIO)为每个token分配一个标签。当前主流工作结合了CRF和神经结构,如CNN、双向LSTM和transformer。然而,这些方法既不能直接解决重叠的,也不能解决不连续的NER。Ju等人(2018)提出了一种通过动态叠加平面NER层的嵌套NER神经模型。Tang等人(2018)将BIO标签方案扩展到BIOHD,以解决间断提及的问题。
基于跨度的方法
已有几项研究将NER定义为跨级分类,即列举所有可能的跨度,并确定它们是否是有效提及和类型。Yu等人(2020)利用双仿射注意来衡量提及文本跨度的可能性。Li等人(2020a)将NER重新定义为机器阅读理解(MRC)任务,并作为答案的跨度提取实体。Shen等人(2021)实现了一个两阶段标识符,通过一个过滤器和一个回归器生成跨度建议,然后将其分类为相应的类别。Li等人(2021a)将不连续的NER转换为从基于跨度的实体片段图中找到完整的子图,并获得具有竞争力的结果。但是,由于详尽的枚举性质,这些方法存在最大的跨度长度和相当大的模型复杂性,特别是对于大跨度的实体。缺点:可能只关注边界识别,不利于不连续实体的识别。
Hypergraph-based Approaches
序列到序列的方法
Gillick等人(2016)首先对NER应用Seq2Seq模型,作为句子的输入,并输出所有实体的起始位置、跨度长度和标签。Strakova等人(2019年)使用Seq2Seq架构,用于重叠的NER和增强的BILOU方案。Fei等人(2021)采用Seq2Seq与指针网络进行不连续NER。(Yan et al. 2021)的最新尝试通过基于BART的指针网络Seq2Seq模型处理统一NER(Lewis等人. 2020),生成所有可能的实体起止索引和类型的序列。不幸的是,Seq2Seq架构中存在潜在的解码效率问题和暴露偏差问题。
我们的方法和以前的方法之间的区别
现有的NER工作主要考虑更准确的实体边界识别。在这项工作中,我们探索了一种不同的任务建模的统一NER,即,词-词关系分类。该方法可以有效地模拟实体的边界词和内部词之间的关系。此外,我们的二维网格标记方法可以大大避免目前表现最好的基线的缺点,例如,基于跨度和序列到序列的模型。
3 NER作为单词关系分类
flat的、重叠的、不连续的NER可以形式化如下:给定一个由N个token或单词![]() 组成的句子,任务的目的是提取每个token对(xi,xj)之间的关系R,其中R是预定义的,包括Next-Neighboring-Word (NNW) 和 Tail-Head-Word-* (THW-*)。这些关系可以如下解释,为了更好地理解,我们还给出了一个如图2所示的示例。
组成的句子,任务的目的是提取每个token对(xi,xj)之间的关系R,其中R是预定义的,包括Next-Neighboring-Word (NNW) 和 Tail-Head-Word-* (THW-*)。这些关系可以如下解释,为了更好地理解,我们还给出了一个如图2所示的示例。
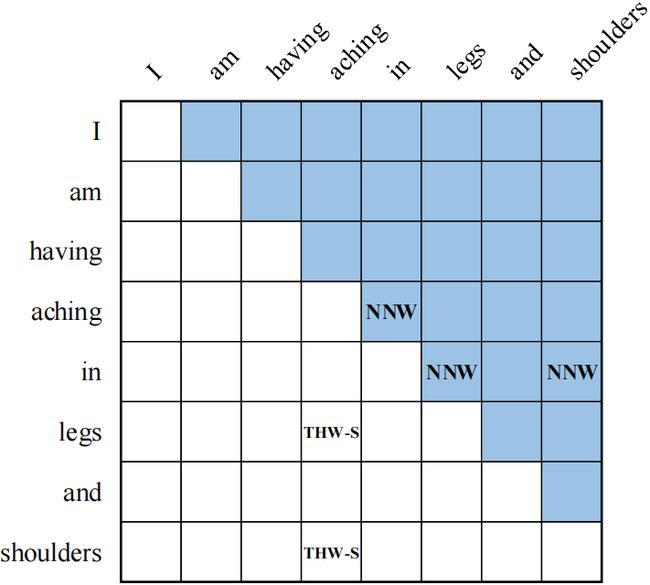
- NONE:表示单词对在本文中没有定义任何关系。
- Next-Neighboring-Word: NNW关系表示单词对属于一个实体的提及,并且在网格的某一行中的单词在网格的某一列中有一个连续的单词。
- Tail-Head-Word-*: THW关系表示网格中某一行中的单词是实体提及的尾部,而网格中某一列中的单词是实体提及的头部。“*”表示实体类型。
通过这样的设计,我们的框架能够同时识别flat、重叠和不连续的实体。
如图2所示,通过解码出“aching in legs”和“aching in shoulders”两个实体的NNW关系(aching→in), (in→legs) 和 (in→ shoulders),THW关系(legs→aching, Symptom) 和(shoulders→aching, Symptom)。
此外,NNW和THW关系还有对NER的其他影响。例如,NNW关系将同一个不连续实体的部分(例如,“aching in”和“shoulders”)联系起来,它们也有利于识别实体词(相邻)和非实体词(非相邻)。THW关系有助于识别实体的边界,这在最近的NER研究中起着重要的作用。
4 统一NER框架
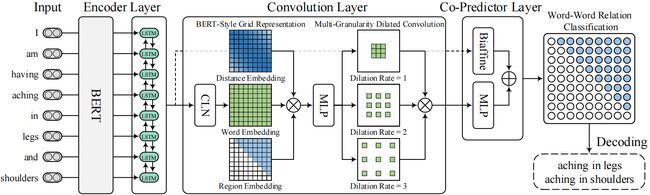
我们的框架的体系结构如图3所示,它主要由三个组件组成。首先,使用预训练语言模型BERT和双向LSTM作为编码器,从输入的句子中生成上下文化的单词表示。然后利用卷积层建立和细化单词对网格的表示,用于以后的词-词关系分类。最后,利用一个包含biaffine分类器和多层感知机的共配器层来联合推理所有词对之间的关系。
4.1 Encoder Layer
我们利用BERT作为我们模型的输入。给定一个输入句子![]() ,将每个token或单词xi转换为单词块,然后将其输入到预训练过的BERT模块中。在BERT计算之后,每个句子词可能涉及几个片段的向量表示。我们使用最大池化来产生基于单词块表示的单词表示。为了进一步增强上下文建模,采用双向LSTM来生成最终的单词表示,其中,
,将每个token或单词xi转换为单词块,然后将其输入到预训练过的BERT模块中。在BERT计算之后,每个句子词可能涉及几个片段的向量表示。我们使用最大池化来产生基于单词块表示的单词表示。为了进一步增强上下文建模,采用双向LSTM来生成最终的单词表示,其中,![]() ,dh表示一个单词表示的维数。
,dh表示一个单词表示的维数。
4.2 卷积层
目的:建立和细化单词对网格的表示,用于以后的字-词关系分类。
采用卷积神经网络(CNNs)作为representation refiner,因为CNNs自然适合于网格上的二维卷积,并且在处理关系确定作业方面表现得非常突出。卷积层包括三个模块,
- 即条件层归一化(Conditional Layer Normalization),生成单词对网格的表示形式
- bert-style网格表示(BERT-Style Grid Representation Build-Up),丰富单词对网格的表示
- 多粒度扩张卷积(Multi-Granularity Dilated Convolution ),捕获近距离和远距离单词之间的交互
4.2.1 conditional Layer Normalization
目的:生成一个高质量的单词对表示对网格
因为我们的框架的目标是预测单词对之间的关系,重要的是生成一个高质量的单词对表示网格,可以视为一个三维矩阵,![]() ,Vij表示单词对的表示(xi,xj)。因为NNW和THW关系都是方向性的,如图2所示从特定行中的单词xi到特定列中的单词xj(例如,aching→in 和 legs→aching),单词对的表示(xi,xj)可以被认为是xi的表示hi和xj的表示hj的组合,其中,组合表示xj以xi为条件。受Liu等人(2021)的启发,我们采用条件层归一化(CLN)来计算Vij:
,Vij表示单词对的表示(xi,xj)。因为NNW和THW关系都是方向性的,如图2所示从特定行中的单词xi到特定列中的单词xj(例如,aching→in 和 legs→aching),单词对的表示(xi,xj)可以被认为是xi的表示hi和xj的表示hj的组合,其中,组合表示xj以xi为条件。受Liu等人(2021)的启发,我们采用条件层归一化(CLN)来计算Vij:
![]()
其中,hi是生成层归一化的增益参数![]() 和偏置
和偏置![]() 的条件。µ和σ为hj各元素的平均值和标准差,记为:
的条件。µ和σ为hj各元素的平均值和标准差,记为:
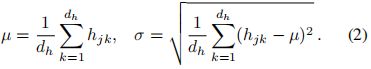
其中,hjk表示hj的第k个维数。
4.2.2 BERT-Style Grid Representation Build-Up
目的:丰富单词对网络的表示
BERT的输入由三部分组成,即标记嵌入、位置嵌入和片段嵌入,分别建模单词、位置和句子信息。受bert的启发,我们使用类似的想法来丰富单词对网络的表示
- 张量
 代表单词信息
代表单词信息 - 张量
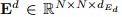 代表每对单词之间的相对位置信息
代表每对单词之间的相对位置信息 - 张量
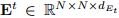 表示用于区分网格中的上下三角形区域的区域信息。
表示用于区分网格中的上下三角形区域的区域信息。
然后,我们将三种嵌入连接起来,并采用多层感知机(MLP)来减少它们的尺寸,并混合这些信息,得到网格![]() 的位置区域感知表示。整个过程可表述为:
的位置区域感知表示。整个过程可表述为:
![]()
4.2.3 Multi-Granularity Dilated Convolution
目的:捕捉不同距离的单词之间的相互作用
受TextCNN的启发,采用了不同膨胀率l(如 l∈[1,2,3])的多重二维膨胀卷积(DConv)来捕捉不同距离的单词之间的相互作用,因为我们的模型是为了预测这些单词之间的关系。在一个展开卷积中的计算可以表述为:
![]()
其中![]() 表示膨胀速率 l 的输出,σ是GELU激活函数。然后,我们可以得到最终的单词对网格表示
表示膨胀速率 l 的输出,σ是GELU激活函数。然后,我们可以得到最终的单词对网格表示![]()
![]() 。
。
4.3 Co-Predictor Layer
目的:联合推理所有词对之间的关系
在卷积层之后,我们得到了单词对网格表示Q,它用于使用MLP预测每对单词之间的关系。先前的工作已经表明,MLP预测器可以通过与biaffine predictor合作进行关系分类来增强。因此,我们同时取这两个预测因子来计算单词对的两个独立的关系分布(xi,xj),并将它们合并作为最终的预测。
4.3.1 Biaffine Predictor
目的:使用双仿射分类器计算一对subject和object词之间的关系分数
输入:编码器层的输出
输出:
预定义的关系分数
双仿射预测器的输入是编码器层的输出![]() ,这可以被认为是一个残差连接,在目前的深度学习研究中被广泛使用。给定单词表示H,使用两个mlp分别计算subject(xi)和object(xj)单词表示,si和oj。然后,使用双仿射分类器计算一对subject和object词之间的关系分数(xi,xj):
,这可以被认为是一个残差连接,在目前的深度学习研究中被广泛使用。给定单词表示H,使用两个mlp分别计算subject(xi)和object(xj)单词表示,si和oj。然后,使用双仿射分类器计算一对subject和object词之间的关系分数(xi,xj):
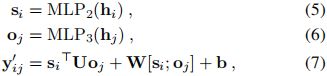
其中U、W、b为可训练参数,si和oj分别表示第i个词和第j个词的subject和object表示。这里![]() 是R中预定义的关系的分数。
是R中预定义的关系的分数。
4.3.2 MLP预测器
目的:计算最终的关系得分
输入:卷积层的输出词对网格表示Q
输出:
词对网格表示Q的预定义关系得分。
将
在词对网格表示Q的基础上,我们采用MLP,利用Qij计算词对(xi, xj)的关系得分:
![]()
其中![]() 为R中预定义的关系的得分。单词对(xi,xj)的最终关系概率yij是通过结合双仿射和MLP预测器的分数来计算的:
为R中预定义的关系的得分。单词对(xi,xj)的最终关系概率yij是通过结合双仿射和MLP预测器的分数来计算的:
![]()
4.4 Decoding
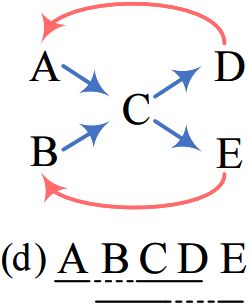
我们的模型是预测单词及单词对之间的关系,可以看作是一个有方向的词图。解码对象是利用NNW关系找到图中从一个单词到另一个单词的特定路径。每个路径都对应于一个实体的提及。除了NER的类型和边界识别外,THW关系也可以作为消歧的辅助信息。图4说明了从容易到困难的解码的四种情况。

- 在示例(a)中,两条路径“A→B”和“D→E”对应于平面实体,而THW关系表示它们的边界和类型。
- 在示例(b)中,如果没有THW关系,我们只能找到一条路径,因此缺少“BC”。相比之下,借助THW关系,很容易确定“BC”是嵌套在“ABC”中的,这说明了THW关系的必要性。
- 案例(c)显示了如何识别不连续的实体。可以找到两条路径“A→B→C”和“A→B→D”,并且NNW关系有助于连接不连续的跨度“AB”和“D”。
- 考虑到一个复杂而罕见的情况(d),我们不可能解码正确的实体“ACD”和“BCE”,因为我们可以在这种模糊的情况下只使用NNW关系找到4条路径。相比之下,只有使用THW关系才能识别连续实体(例如,“ABCD”),而不是纠正不连续实体(例如,“ACD”)。因此,我们可以通过协同使用这两种关系来得到正确的答案。
4.5 Learning
对于每个句子![]() ,我们的训练目标是最小化对应gold label的负对数似然损失,形式化为:
,我们的训练目标是最小化对应gold label的负对数似然损失,形式化为:
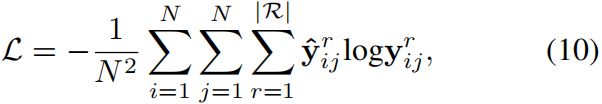
其中N为句子中的单词数,![]() 为二进制向量,表示单词对(xi,xj)的gold relation label,yij为预测的概率向量。R表示预定义的关系集R的第r个关系。
为二进制向量,表示单词对(xi,xj)的gold relation label,yij为预测的概率向量。R表示预定义的关系集R的第r个关系。
5 实验设置
为了评估我们的三个NER子任务的框架,我们在14个数据集上进行了实验。
- Flat NER Datasets CoNLL-2003(英文),OntoNotes 5.0(英文),OntoNotes 4.0(中文),MSRA(中文),Weibo(中文),Resume(中文)
- Overlapped NER Datasets ACE 2004(中文和英文),ACE 2005(中文和英文),GENIA
- Discontinuous NER Datasets CADEC,ShARe13,ShARe14
Baselines
- Tagging-based methods 基于tag的方法,指定具有不同标记方案的每个token,如BIO (Lample等2016年)、BIOHD(Tang等2018年)和BIEOS(Li等2020b;Ma等2020年)。
- Span-based methods 基于跨度的方法,枚举所有可能的跨度并将它们合并为实体(Yu等,2020;Li等,2021a)。
- Hypergraph-based approaches 基于超图的方法,利用超图来表示和推断实体提及(Lu和Roth 2015;Wang和陆2018;Katiyar和Cardie 2018)。
- Seq2Seq methods,在解码器端生成实体标签序列(Strubell等2017)、索引或词序列(Yan等2021;Fei等20212)。
- Other methods 其他方法与上述方法不同,如基于过渡的(Dai et al. 2020)和基于clique的(Wang et al. 2021)方法。
6 实验结果
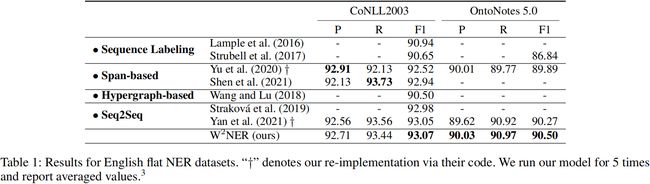
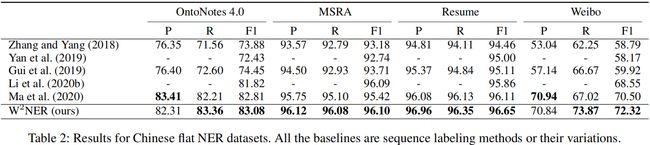

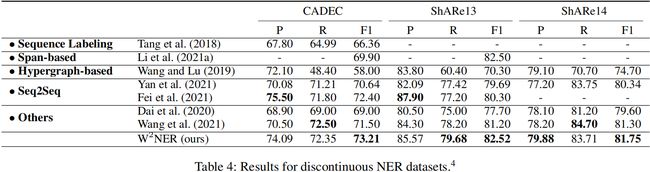
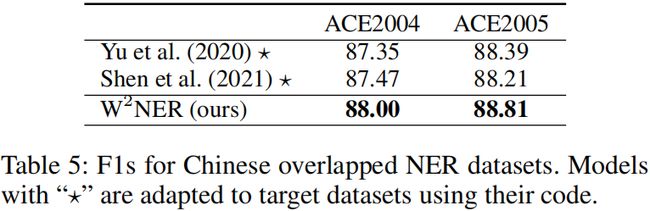
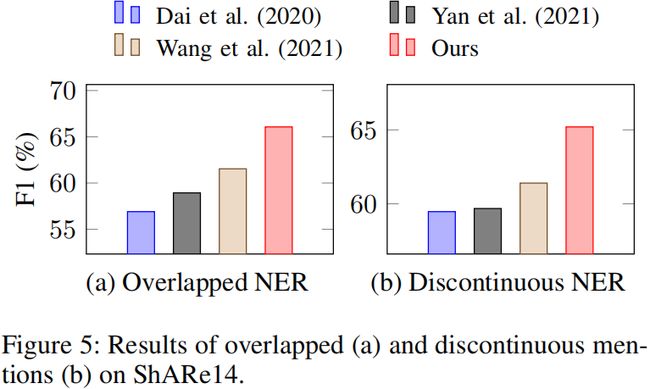
消融研究
- 首先,在没有region和距离嵌入的情况下,我们观察到三个数据集的性能略有下降。
- 通过去除所有的卷积,性能也明显下降,这验证了多粒度扩展卷积的有用性。
- 此外,在去除不同扩张率(dilation rate)的卷积后,性能也会下降,特别是为扩张率(dilation rate)为2的卷积。
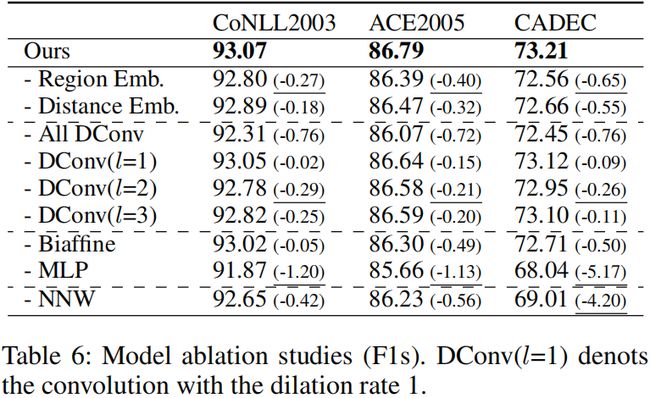
因此,NNW关系的消融研究结果表明了NNW关系的重要性。
7 结论
本文提出了一种新的基于词-词关系分类的统一NER框架来同时解决统一NER问题。词对之间的关系被预定义为next-neighboring-word关系和tail-head-word词关系。我们发现,我们的框架对各种NER都非常有效,它在14个广泛使用的基准数据集上实现了SOTA性能。此外,我们提出了一种新的主干模型,该模型包括一个BERT-BiLSTM编码器层,一个用于构建和细化字对网格表示的卷积层,以及一个用于联合推理关系的协同预测器层。通过消融研究,我们发现我们的convolution-centric模型表现良好,并且提出的一些模块,如协同预测器和grid representation enrichment也是有效的。我们的框架和模型易于遵循,这将促进NER研究的发展。