Spring依赖注入之@Resourcce详解&Bean的销毁
Spring依赖注入之@Resourcce详解&Bean的销毁
- @Resource和@AutoWired
-
- @Resource依赖注入过程
- 源码分析
-
- @Resource、@PostConstruct、@PreDestroy寻找注入点
-
- applyMergedBeanDefinitionPostProcessors
- CommonAnnotationBeanPostProcessor.postProcessMergedBeanDefinition
- InitDestroyAnnotationBeanPostProcessor.postProcessMergedBeanDefinition
- findLifecycleMetadata
- @Resource的依赖注入
-
- getResourceToInject
- autowireResource
- Bean的销毁
-
- bean销毁入口
-
- registerDisposableBeanIfNecessary
- requiresDestruction
- DisposableBeanAdapter构造
- 销毁Bean的过程图
-
-
- Bean的创建和销毁的整个生命周期图
-
@Resource和@AutoWired
Bean的生命周期到这里就差不多结束了,这篇笔记主要记录下Bean的生命周期之销毁过程以及spring的依赖注入之@Resource注解的注入过程,@Resource的注入过程非常简单,如果你懂了@AutoWired的注解过程,那么这个@Resource就简直是喝水那样简单,非常简单,这里简单说下,很多时候都是建议使用@Resource,@Resource在性能上比@AutoWired高很多,原因就在于@AutoWired判断的是在太多,处理起来非常复杂,但是@AutoWired的容错率很高,而且提供的很多依赖注入过程是@Resource是没有的,比如很多spring cloud中提供的一些功能都使用了@AutoWired的强大功能实现的,只是这两个注解用在不同的地方,在实际的开发过程中根据不同的场景来使用这两个注解,比如说一般定义了我们的业务bean,这个业务bean都是非常普通的,就是一个接口一个实现类,每个接口都代表了这种业务的一种职责,而且只有可能被一个实现类去实现,那么这种情况下,我们就用@Resource来,但是也不能说@Resource的性能更好,如果你没有配置name属性,然后容器中这个时候还没有这个bean,也会按照@AutoWired的逻辑走一遍,所以使用得注意,如果加了name属性也更好,匹配性更好,不加也无所谓,spring在依赖注入的时候找寻注入点会生成默认的beanName;这种业务就比较简单,反正就是一个bean一个实现类,而且不存在多个bean的情况,用@resource直接去容器拿了,也就相当于applicationContext.geBean(beanName)的方式当然非常快,如果这个时候还是去用@AutoWired,要经过一系列的判断,可以说是山路十八弯,看了前两篇笔记就知道@AutoWired的过程很复杂,判断很多,所以在某种意义上说@Resource的性能较好;还有一种场景就是一个接口被多个实现类实现,比如在一个负载均衡的服务器上,我们又一个顶级类LandBlance,那么它的子类Random和Round都是它的子类,那么如果我们用@Resource也可以实现,只是比较麻烦,这个时候我们把注解@Qualifier包装一下,@AutoWired就会很智能的找到我们启用了负载均衡器。
其实在spring中代码的执行效率是很高的,所以不管用那种依赖注入,那么都是非常快的,而且只是在启动阶段,启动完成了,那么性能也不受影响;最近公司有个平台没有办法集成spring,我自己以及根据spring的思想,基本上按照它的过程写了一个阉割版的spring架构,也有bean的注册器,bean工厂的后置处理器、Bean生命周期的过程、factoryBean,包括bean的实例化前后后置处理器,@AutoWired依赖注入过程,反正就是麻雀虽小,五脏俱全。
@Resource依赖注入过程
@Resouce的过程非常简单,在看了@AutoWired的过程过后,@Resouce就非常简单了,但是也有@AutoWired的大致过一样,手续寻找注入点,找到注入点然后加入到缓存中,然后初始化前调用后置处理器进行注入。
源码分析
@Resource、@PostConstruct、@PreDestroy寻找注入点
@Resource的注入点寻找和@AutoWired的入口一模一样,也是在creatBean的实例化过后调用的,具体的在createBean的下图中:
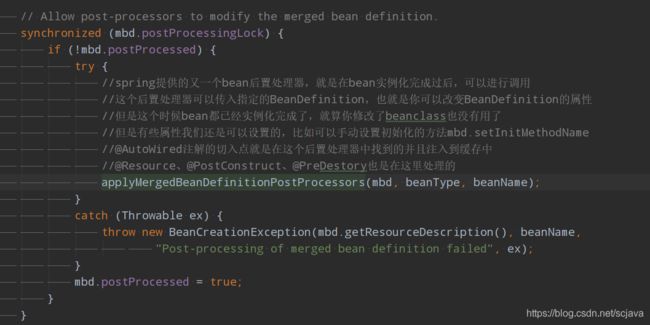
applyMergedBeanDefinitionPostProcessors
/**
* Apply MergedBeanDefinitionPostProcessors to the specified bean definition,
* invoking their {@code postProcessMergedBeanDefinition} methods.
* @param mbd the merged bean definition for the bean
* @param beanType the actual type of the managed bean instance
* @param beanName the name of the bean
* @see MergedBeanDefinitionPostProcessor#postProcessMergedBeanDefinition
* 这个方法我个人的理解是可以被叫做合并bean过后的bean后置处理器
* @AutoWired注解和@Value以及@Inject注解都是在这个后置处理器中实现的
* 具体的后置处理器是AutowiredAnnotationBeanPostProcessor,在里面调用了postProcessMergedBeanDefinition
* 这里面其实还有一个功能就是找到所有的声明周期方法,初始化方法和销毁方法,就是配置了@PostConstuct 和@PreDestroy的方法
* 是在CommonAnnotationBeanPostProcessor.postProcessMergedBeanDefinition中实现的
* 在这个后置处理器中还实现了@Resource的注解
* 总结:
* 1.AutowiredAnnotationBeanPostProcessor处理了@AutoWired 、@Value注解和依赖注入
* 2.CommonAnnotationBeanPostProcessor处理了声明周期回调方法(@PostConstuct、@PreDestroy)
* 3.CommonAnnotationBeanPostProcessor处理了@Resource的依赖注入
*
* a.后置处理器AutowiredAnnotationBeanPostProcessor中是对bean依赖注入的注入点进行查找,查找成功过后放入缓存,后置的初始化前会对缓存中的依赖注入点就行依赖注入
* b.CommonAnnotationBeanPostProcessor寻找@Resource的注入点和@PreDestory @PostConstrut注解的方法并放入缓存
*
*/
protected void applyMergedBeanDefinitionPostProcessors(RootBeanDefinition mbd, Class<?> beanType, String beanName) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof MergedBeanDefinitionPostProcessor) {
MergedBeanDefinitionPostProcessor bdp = (MergedBeanDefinitionPostProcessor) bp;
bdp.postProcessMergedBeanDefinition(mbd, beanType, beanName);
}
}
}
这个方法做了那些事儿,我在上面的代码注释中已经说的很清楚了。我们关心的是这些后置处理器是啥时候注册进去的,这个会在spring启动哪里记录,这里就只要知道这个后置处理器列表中有两个后置处理器:AutowiredAnnotationBeanPostProcessor和CommonAnnotationBeanPostProcessor,其中CommonAnnotationBeanPostProcessor还继承了InitDestroyAnnotationBeanPostProcessor
AutowiredAnnotationBeanPostProcessor: 处理@AutoWired @Value注解
CommonAnnotationBeanPostProcessor: 处理@Resource
InitDestroyAnnotationBeanPostProcessor:处理@PostConstruct、@PreDestory
上面的处理包括注入点的注入和真正的注入;AutowiredAnnotationBeanPostProcessor在前两篇笔记中记录了,今天这篇笔记就记录下@Resource和生命周期的销毁
CommonAnnotationBeanPostProcessor.postProcessMergedBeanDefinition
/**
* 这个后置处理方法处理两个过程
* 1.找到所有的声明周期回调方法(@PostConstruct、 @PreDestroy)
* 2.处理@Resource注解
* @param beanDefinition
* @param beanType
* @param beanName
*/
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
//调用父类找到所有的声明周期回调方法(@PostConstruct、 @PreDestroy)
super.postProcessMergedBeanDefinition(beanDefinition, beanType, beanName);
//处理@Resource注解
InjectionMetadata metadata = findResourceMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}
super.postProcessMergedBeanDefinition(beanDefinition, beanType, beanName)是调用父类的InitDestroyAnnotationBeanPostProcessor找到@PostConstruct、@PreDestory注解的方法
InitDestroyAnnotationBeanPostProcessor.postProcessMergedBeanDefinition
/**
* 这个是找到所有的声明周期回调方法(@PostConstruct、 @PreDestroy)
* @param beanDefinition the merged bean definition for the bean
* @param beanType the actual type of the managed bean instance
* @param beanName the name of the bean
*/
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
LifecycleMetadata metadata = findLifecycleMetadata(beanType);
metadata.checkConfigMembers(beanDefinition);
}
findLifecycleMetadata
private LifecycleMetadata findLifecycleMetadata(Class<?> clazz) {
if (this.lifecycleMetadataCache == null) {
// Happens after deserialization, during destruction...
return buildLifecycleMetadata(clazz);
}
// Quick check on the concurrent map first, with minimal locking.
/**
* 这个方法的过程和之前依赖注入的类似,就是找到@PostConstruct、 @PreDestroy注解,然后加入缓存
*/
LifecycleMetadata metadata = this.lifecycleMetadataCache.get(clazz);
if (metadata == null) {
synchronized (this.lifecycleMetadataCache) {
metadata = this.lifecycleMetadataCache.get(clazz);
if (metadata == null) {
metadata = buildLifecycleMetadata(clazz);
this.lifecycleMetadataCache.put(clazz, metadata);
}
return metadata;
}
}
return metadata;
}
private LifecycleMetadata buildLifecycleMetadata(final Class<?> clazz) {
if (!AnnotationUtils.isCandidateClass(clazz, Arrays.asList(this.initAnnotationType, this.destroyAnnotationType))) {
return this.emptyLifecycleMetadata;
}
/**
* 定义了两个集合,初始化方法的集合和销毁方法的集合
*/
List<LifecycleElement> initMethods = new ArrayList<>();
List<LifecycleElement> destroyMethods = new ArrayList<>();
Class<?> targetClass = clazz;
//下面这段逻辑非常简单,在依赖注入@AutoWired就是这样写的,只是这里是找方法,没有属性的说法,所合一这里就是
//循环本类,然后一直往上找,看是否有符合条件的方法加入
do {
final List<LifecycleElement> currInitMethods = new ArrayList<>();
final List<LifecycleElement> currDestroyMethods = new ArrayList<>();
//和@AutoWired一样,找到注入点一样,这里只是找到加了@PostConcurst,@PreDestroy注解的方法
//并且加入到集合中,最后放入缓存中
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
if (this.initAnnotationType != null && method.isAnnotationPresent(this.initAnnotationType)) {
LifecycleElement element = new LifecycleElement(method);
currInitMethods.add(element);
if (logger.isTraceEnabled()) {
logger.trace("Found init method on class [" + clazz.getName() + "]: " + method);
}
}
if (this.destroyAnnotationType != null && method.isAnnotationPresent(this.destroyAnnotationType)) {
currDestroyMethods.add(new LifecycleElement(method));
if (logger.isTraceEnabled()) {
logger.trace("Found destroy method on class [" + clazz.getName() + "]: " + method);
}
}
});
initMethods.addAll(0, currInitMethods);
destroyMethods.addAll(currDestroyMethods);
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
return (initMethods.isEmpty() && destroyMethods.isEmpty() ? this.emptyLifecycleMetadata :
new LifecycleMetadata(clazz, initMethods, destroyMethods));
}
也就是说找到的所有初始化方法和销毁方法都在LifecycleMetadata对象中,最后放入缓存lifecycleMetadataCache中,lifecycleMetadataCache存放的是ResouceElement,@Resource的注入点信息
然后这里回到CommonAnnotationBeanPostProcessor中开始找寻@Resource注入点
//处理@Resource注解
InjectionMetadata metadata = findResourceMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
findResourceMetadata这个方法就是去找到@Resource的注入点,然后放入缓存injectionMetadataCache中,和上面的生命周期方法的找到和@AutoWired的找寻一模一样,我这里就不写了,也不贴代码了,一模一样,不清楚可以翻下前两篇笔记@AutoWired的是如何找寻注入点的。
@Resource的依赖注入
@Resource的依赖注入和@AutoWired的依赖注入的入口都是一模一样的,都是在populateBean这个方法的进行的,具体的在代码
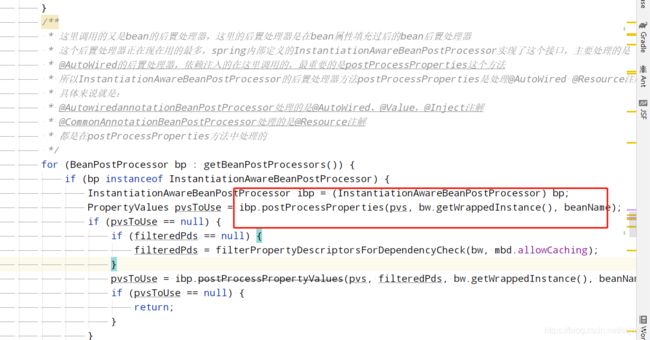
后置处理器的方法postProcessProperties,这里执行的是CommonAnnotationBeanPostProcessor中的postProcessProperties方法
/**
* 这个方法是处理@Resource依赖注入的,和@AutoWired一样,在实例化前先找到@Resource注解信息
* 然后这里实例化过后,开始进行依赖注入,就是说spring中的依赖注入分为两部分,@AutoWired和@Resource
* 从性能上来说,@Resource的性能更好
* @param pvs the property values that the factory is about to apply (never {@code null})
* @param bean the bean instance created, but whose properties have not yet been set
* @param beanName the name of the bean
* @return
*/
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
InjectionMetadata metadata = findResourceMetadata(beanName, bean.getClass(), pvs);
try {
metadata.inject(bean, beanName, pvs);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of resource dependencies failed", ex);
}
return pvs;
}
findResourceMetadata就是去缓存中获取,根据beanName获取注入点列表,然后调用inject注入
这里的@Resource的注入和@AutoWired注入有点不同,是直接调用父类的InjectionMetadata的inject方法进行注入,这个方法里面就直接根据if判断是Field还是Method
/**
* 这个是InjectMetadata中的注入方法,其中有@AutoWired和@Resource都是调用的这个方法注入
* 其中@AutoWired的注入是:AutowiredFieldElement和AutowiredMethodElement
* @Resouorce的子类是ResourceElement
* 也就是说@Resource的属性注入和方法注入都是ResourceElement
* @param target
* @param beanName
* @param pvs
* @throws Throwable
*/
public void inject(Object target, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Collection<InjectedElement> checkedElements = this.checkedElements;
Collection<InjectedElement> elementsToIterate =
(checkedElements != null ? checkedElements : this.injectedElements);
if (!elementsToIterate.isEmpty()) {
for (InjectedElement element : elementsToIterate) {
if (logger.isTraceEnabled()) {
logger.trace("Processing injected element of bean '" + beanName + "': " + element);
}
// 这里的调用就要区分是属性还是方法,至于调用属性的注入和方法的注入就要根据你放入缓存的时候放入的是缓存AutowiredFieldElement
//还是AutowiredMethodElement,而这两个类都是InjectedElement的子类,所以这再一次说明了java的面向对象的好处
element.inject(target, beanName, pvs);
}
}
}
/**
* Either this or {@link #getResourceToInject} needs to be overridden.
* 这个方法只有@Resource的注入才会调用,而@AutoWired的注入是调用其相对应的子类
*/
protected void inject(Object target, @Nullable String requestingBeanName, @Nullable PropertyValues pvs)
throws Throwable {
/**
* 因为@Resource的注入都是ResourceElement,所以它的注入都是一个方法
* 只是在这个inject方法中分了是属性还是方法
*/
if (this.isField) {
Field field = (Field) this.member;
ReflectionUtils.makeAccessible(field);
field.set(target, getResourceToInject(target, requestingBeanName));
}
else {
if (checkPropertySkipping(pvs)) {
return;
}
try {
Method method = (Method) this.member;
ReflectionUtils.makeAccessible(method);
method.invoke(target, getResourceToInject(target, requestingBeanName));
}
catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
}
}
这个注入过程很简单,其他的没有啥可说的,主要关注下getResourceToInject,获取bean的过程,前面写@AutoWired的时候,那个获取的bean过程可以说写一篇论文都嫌少,这里我们主要关注下是如何获取bean的,性能的差别也在这里;
getResourceToInject
/**
* 这里是@Resouce来找bean的方法
* 这里判断是否加了@Lazy注解,也就是说在方法上或者属性上加了@Lazy注解过后,那么这里会生成一个代理对象,
* 等真正使用的时候通过代理对象获取真实的对象,如果没有加@Lazy注解,那么就从容器中获取对象
* 如果是代理对象的话和@Autowired一模一样
* @param target
* @param requestingBeanName
* @return
*/
@Override
protected Object getResourceToInject(Object target, @Nullable String requestingBeanName) {
return (this.lazyLookup ? buildLazyResourceProxy(this, requestingBeanName) :
getResource(this, requestingBeanName));
}
}
/**
* Obtain the resource object for the given name and type.
* @param element the descriptor for the annotated field/method
* @param requestingBeanName the name of the requesting bean
* @return the resource object (never {@code null})
* @throws NoSuchBeanDefinitionException if no corresponding target resource found
* 这里是@Resource的getBean逻辑过程,我这里我们只关注autowireResource,其中的jndi的获取和
* mappedName的获取现在基本上没有用了吧,所以我这里就直接忽略,只关心autowireResource的过程
*/
protected Object getResource(LookupElement element, @Nullable String requestingBeanName)
throws NoSuchBeanDefinitionException {
if (StringUtils.hasLength(element.mappedName)) {
return this.jndiFactory.getBean(element.mappedName, element.lookupType);
}
if (this.alwaysUseJndiLookup) {
return this.jndiFactory.getBean(element.name, element.lookupType);
}
if (this.resourceFactory == null) {
throw new NoSuchBeanDefinitionException(element.lookupType,
"No resource factory configured - specify the 'resourceFactory' property");
}
return autowireResource(this.resourceFactory, element, requestingBeanName);
}
autowireResource
protected Object autowireResource(BeanFactory factory, LookupElement element, @Nullable String requestingBeanName)
throws NoSuchBeanDefinitionException {
Object resource;
Set<String> autowiredBeanNames;
String name = element.name;
/**
* 我们的依赖注入的触发点是在createBean过来的,所以factory肯定是AutowireCapableBeanFactory
* 所以代码的逻辑会进入下面的if
*/
if (factory instanceof AutowireCapableBeanFactory) {
AutowireCapableBeanFactory beanFactory = (AutowireCapableBeanFactory) factory;
DependencyDescriptor descriptor = element.getDependencyDescriptor();
//这个if的逻辑判断分为3块,每一块的执行如果是false都不会进行下一个逻辑判断
//首先fallbackToDefaultTypeMatch默认是true,如果没有手动介入的设置值的话,那么它的值是true
//第二个判断element.isDefaultName什么 意思呢?就是说我们在使用@Resource的时候,如果你传入了name属性的话
//那么element.isDefaultName就是false,比如@Resource(name="xxxx")那么isDefaultName=false,这个是构造方法
//构造的时候设置的,就是在找寻注入点的时候,构造ResourceElement的时候设置的
//name是表示属性@Resource(name="xxx")如果设置了name属性,那么name就是@resource中name的值
//如果没有设置就是属性或者方法参数的名字生成的beanNaem,比如 Introspector.decapitalize(field.getName)
//或者 Introspector.decapitalize(method.getSettMethod().substring(3))
/**
* 这个if的代码逻辑就是说如果fallbackToDefaultTypeMatch=true的情况下,注入点@Resource没有设置bean的名字
* 然后单例池中也没有这个bean
* 那么如果满足这个条件,@Resource的逻辑也就和@AutoWired差不多了
*
*/
if (this.fallbackToDefaultTypeMatch && element.isDefaultName && !factory.containsBean(name)) {
autowiredBeanNames = new LinkedHashSet<>();
resource = beanFactory.resolveDependency(descriptor, requestingBeanName, autowiredBeanNames, null);
//如果还是没有找到,就报错
if (resource == null) {
throw new NoSuchBeanDefinitionException(element.getLookupType(), "No resolvable resource object");
}
}
else {
//上面的条件只要不满足其中一个,就进入这个方法
//这个就比@AutoWired中的resolveDependency性能好很多,直接通过name属性和字段类型去容器找bean
resource = beanFactory.resolveBeanByName(name, descriptor);
autowiredBeanNames = Collections.singleton(name);
}
}
else {
//直接通过name属性和字段类型去容器找bean
resource = factory.getBean(name, element.lookupType);
autowiredBeanNames = Collections.singleton(name);
}
//spring的默认bean工厂DefaultListableBeanFactory是最全的,肯定也是ConfigurableBeanFactory
//所以这里是注册依赖,就是说bean注入过后,要记录这个bean依赖那些bean,autowiredBeanName就是注入的Field或者
//Methdod 参数,这里做依赖记录,和@Autowired一样的
if (factory instanceof ConfigurableBeanFactory) {
ConfigurableBeanFactory beanFactory = (ConfigurableBeanFactory) factory;
for (String autowiredBeanName : autowiredBeanNames) {
if (requestingBeanName != null && beanFactory.containsBean(autowiredBeanName)) {
beanFactory.registerDependentBean(autowiredBeanName, requestingBeanName);
}
}
}
return resource;
}
上面的就是@Resource获取Bean的过程,过程简单描述就是:
1.如果@Resource没有设置name对应的值,并且spring的单例工厂中没有这个bean(根据bean类型生成的beanName),然后和@AutoWired的获取bean过程一模一样,所以不要说@Resource的性能就一定比@AutoWired好,就是有可能@Resource也会转成@AutoWired的模式;
2.如果条件不满足,就是说你设置了name属性对应的beanName,那么就会直接getBean去spring容器中获取。
我们简单用一个图来描述下@Resource的注入过程:
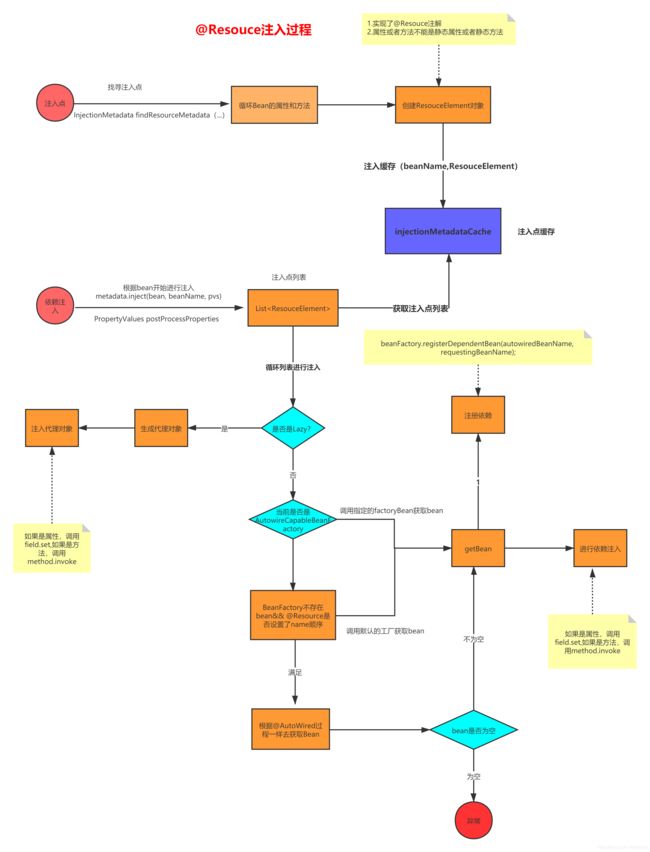
Bean的销毁
当容器进行关闭的时候需要对bean和bean工厂以及一系列的容器进行销毁,这个时候销毁只是对容器的bean对象进行销毁,不意味着对对象进行销毁;销毁分为两种,手动销毁和自动销毁,手动销毁需要调用容器的close方法进行销毁,而自动销毁是向jvm注册一个钩子线程,当容器进行关闭的时候会自动调用销毁的钩子线程进行销毁,比如我们的jvm关闭的时候会自动来调用你的钩子线程来销毁容器的bean,我们来看自动会手动的方式。
手动方式:
先定义一个bean,在bean中定义一个销毁的方法:
@Component
public class UserService {
@PreDestroy
public void preDestory(){
System.out.println("@PreDestroy");
}
}
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(AppConfig.class);
System.out.println(ac.getBean(UserService.class));
ac.close();
}
输入如下:
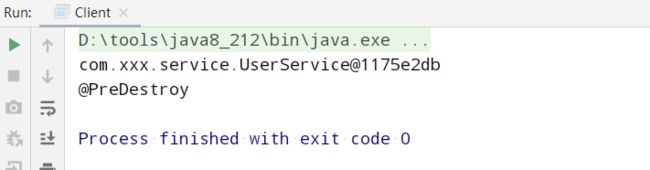
当手动的调用容器的close方法,会调用销毁的方法;
自动的方式向jvm添加一个钩子,如下:
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(AppConfig.class);
ac.registerShutdownHook();
System.out.println(ac.getBean(UserService.class));
}
上面这个也是可以的,但是这个是在jvm关闭的时候会来调用这个钩子方法的,下面我们就来分析下容器的销毁的整个过程。
bean销毁入口
public void registerShutdownHook() {
if (this.shutdownHook == null) {
// No shutdown hook registered yet.
this.shutdownHook = new Thread(SHUTDOWN_HOOK_THREAD_NAME) {
@Override
public void run() {
synchronized (startupShutdownMonitor) {
doClose();
}
}
};
Runtime.getRuntime().addShutdownHook(this.shutdownHook);
}
}
上面的代码就是向jvm注册一个钩子线程,当jvm关闭的时候会来调用我们的钩子线程,执行doClose方法,下面来就详细分析下doClose方法。
protected void doClose() {
// Check whether an actual close attempt is necessary...
if (this.active.get() && this.closed.compareAndSet(false, true)) {
if (logger.isDebugEnabled()) {
logger.debug("Closing " + this);
}
LiveBeansView.unregisterApplicationContext(this);
try {
// Publish shutdown event.向spring容器发布一个事件,表示容器即将关闭
publishEvent(new ContextClosedEvent(this));
}
catch (Throwable ex) {
logger.warn("Exception thrown from ApplicationListener handling ContextClosedEvent", ex);
}
// Stop all Lifecycle beans, to avoid delays during individual destruction.
//生命周期进程关闭
if (this.lifecycleProcessor != null) {
try {
this.lifecycleProcessor.onClose();
}
catch (Throwable ex) {
logger.warn("Exception thrown from LifecycleProcessor on context close", ex);
}
}
// Destroy all cached singletons in the context's BeanFactory.
//销毁bean,只是销毁bean,不是销毁对象
destroyBeans();
// Close the state of this context itself.
//关闭工厂,设置beanFactory为null
closeBeanFactory();
// Let subclasses do some final clean-up if they wish...
onClose();
// Reset local application listeners to pre-refresh state.
//清除所有的监听器
if (this.earlyApplicationListeners != null) {
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
// Switch to inactive.
//将容器设置为非激活
this.active.set(false);
}
}
这里重点来分析下destroyBeans销毁bean的过程,只有这个过程最复杂
protected void destroyBeans() {
getBeanFactory().destroySingletons();
}
public void destroySingletons() {
//销毁单例池
super.destroySingletons();
updateManualSingletonNames(Set::clear, set -> !set.isEmpty());
clearByTypeCache();
}
public void destroySingletons() {
if (logger.isTraceEnabled()) {
logger.trace("Destroying singletons in " + this);
}
synchronized (this.singletonObjects) {
this.singletonsCurrentlyInDestruction = true;
}
//拿到所有的销毁方法,就是在spring的bean中定义了销毁bean的时候需要回调的
//方法;disposableBeans中包含的销毁方法有三种:
//1.实现了DisposableBean和AutoCloseable(java的接口)
//2.用xml或者@Bean定义的bean都有一个destroyMethod默认的方法,这个默认的方法是不要实现的,直接回调用
//比如会自动调用bean中的close 、shutdown方法
//3.使用了注解 @PreDestroy注册的方法
//4.在BeanDefinition中手动添加了或者xml中手动配置的销毁方法
String[] disposableBeanNames;
//拿到所有的disposableBeans销毁方法
synchronized (this.disposableBeans) {
disposableBeanNames = StringUtils.toStringArray(this.disposableBeans.keySet());
}
//循环进行销毁
for (int i = disposableBeanNames.length - 1; i >= 0; i--) {
destroySingleton(disposableBeanNames[i]);
}
this.containedBeanMap.clear();
this.dependentBeanMap.clear();
this.dependenciesForBeanMap.clear();
clearSingletonCache();
}
public void destroySingleton(String beanName) {
// Remove a registered singleton of the given name, if any.
//将这个bean从单例池中移除,一二级缓存中移除,还有就是一些spring内部容器的缓存中全部移除
removeSingleton(beanName);
// Destroy the corresponding DisposableBean instance.
DisposableBean disposableBean;
synchronized (this.disposableBeans) {
//disposableBeans是一个map,为什么它可以直接转成DisposableBean,在map中的对象类型是object
//其实这里使用的是适配器模式,这个要在加入这个bean的时候才能知道是什么原理
disposableBean = (DisposableBean) this.disposableBeans.remove(beanName);
}
destroyBean(beanName, disposableBean);
}
protected void destroyBean(String beanName, @Nullable DisposableBean bean) {
// Trigger destruction of dependent beans first...
Set<String> dependencies;
//在依赖bean的map中移除
synchronized (this.dependentBeanMap) {
// Within full synchronization in order to guarantee a disconnected Set
dependencies = this.dependentBeanMap.remove(beanName);
}
if (dependencies != null) {
if (logger.isTraceEnabled()) {
logger.trace("Retrieved dependent beans for bean '" + beanName + "': " + dependencies);
}
//这里是一个递归调用,就是如果这个bean在容器中有依赖的bean,那么在移除这个bean前,要先把依赖的bean全部移除,
//递归调用destroySingleton方法进行移除
for (String dependentBeanName : dependencies) {
destroySingleton(dependentBeanName);
}
}
// Actually destroy the bean now...
if (bean != null) {
try {
/**
* 这里才是调用销毁的方法,但是如果你这样认为,你就错了,你想哈,我们的
* disposableBeans是value是一个Object,那么取出来的就直接转成DisposeBean,然后调用destory方法
* 但是你没有没想过,刚刚在前面说的disposableBeans这个bean中存在不同的销毁方法,如果是xml或者@Bean的方式
* 那么默认方法是close、shutdown或者BeanDefinition中指定的默认方法
* 所以这里直接调用destroy不是直接调用的我们bean中的销毁方法,这里使用的是适配器模式
* 就是说在添加到disposableBeans的时候,将销毁的bean封装成一个对象,然后这个对象实现了DisposeBean的方法
* 每次调用销毁其实是调用到了适配器中的destroy方法,适配器中根据销毁方法的类型去调用指定的销毁方法
* DisposableBeanAdapter.destroy()
*/
bean.destroy();
}
catch (Throwable ex) {
if (logger.isWarnEnabled()) {
logger.warn("Destruction of bean with name '" + beanName + "' threw an exception", ex);
}
}
}
// Trigger destruction of contained beans...
Set<String> containedBeans;
synchronized (this.containedBeanMap) {
// Within full synchronization in order to guarantee a disconnected Set
containedBeans = this.containedBeanMap.remove(beanName);
}
if (containedBeans != null) {
for (String containedBeanName : containedBeans) {
destroySingleton(containedBeanName);
}
}
// Remove destroyed bean from other beans' dependencies.
synchronized (this.dependentBeanMap) {
for (Iterator<Map.Entry<String, Set<String>>> it = this.dependentBeanMap.entrySet().iterator(); it.hasNext();) {
Map.Entry<String, Set<String>> entry = it.next();
Set<String> dependenciesToClean = entry.getValue();
dependenciesToClean.remove(beanName);
if (dependenciesToClean.isEmpty()) {
it.remove();
}
}
}
// Remove destroyed bean's prepared dependency information.
this.dependenciesForBeanMap.remove(beanName);
}
上面的代码中我们重点来看destroyBean销毁bean的方法,其他的我没有写的太细,就是对spring在启动和创建的过程设置好多的map和集合对象,这些对象都会有用的,所以在创建的过程是没有销毁的,这里需要销毁。不是太重要,重要的是把destroyBean这个方法的逻辑弄清楚;
在上面的代码中有一个缓存非常重要disposableBeans,这个集合缓存存储了就是每个bean中定义的所有的销毁方法,这些销毁方法包括了很多,具体包括了:
1.BeanDefinition中定义的或者xml中定义销毁方法;
2.@Bean中定义的默认销毁方法;
3.实现了DisposableBean,AutoCloseable而需要实现了销毁方法;
4.@PreDestroy定义的销毁方法
所以这个缓存集合disposableBeans中存储了每个bean对应的这些销毁方法,但是要你的bean定义了这些中的一个或者多个销毁方法,disposableBeans集合缓存中才会有,而我们看到disposableBeans这个map其实是一个
synchronized (this.disposableBeans) {
//disposableBeans是一个map,为什么它可以直接转成DisposableBean,在map中的对象类型是object
//其实这里使用的是适配器模式,这个要在加入这个bean的时候才能知道是什么原理
disposableBean = (DisposableBean) this.disposableBeans.remove(beanName);
}
直接强制转换的,这里我就直接说了,其实disposableBeans中添加value的时候这个value是一个适配器,也就是说销毁bean使用的是适配器模式,将上面的所有的销毁方法的实现都封装在了一个适配器中,当你调用适配器的销毁方法时,适配器会根据当前bean中定义的销毁方法类型来调用,就是你定义了3个就调用3个,所以spring在销毁这一块采用的是适配器模式,不晓得这样说大家能不能够懂它设计的原理;
我们来看destroyBean方法的bean.destroy()这里,首先bean是DisposableBean,DisposableBean中是存在销毁方法destroy的,上面我已经说了销毁这里是采用的适配器设计模式,所以这里的destroy方法不是调用DisposableBean的销毁方法,而是调用了适配器的destroy方法,而这个适配器是DisposableBean的子类,所以这些在java中是可以的,而这个适配器是什么呢?它就是DisposableBeanAdapter,它的定义如下:
/**
* 销毁bean的适配器类,这个类封装了销毁bean的所有可执行的方法的集合
* 适配器模式的概念就是说我适配所有的操作,由我来决定怎么来调用,这是我瞎说的哈,哈哈
* 反正spring在销毁bean的这块,销毁bean前会将每个bean中定义的销毁方法都通过则适配器进行注册
* 也就是说某个bean中有三个销毁的方法,
*不管这三个销毁的方法是在BeanDefinition中定义的,还是默认指定的
* 都会封装到这个适配器中,然后放入到缓存中,当容器关闭的时候,那么就会找到这个销毁的缓存集合,然后循环调用来执行销毁的方法
*/
@SuppressWarnings("serial")
class DisposableBeanAdapter implements DisposableBean, Runnable, Serializable {
//当定义的bean的销毁方法模式是(inferred)的时候,那么销毁的默认方法就是close或者shutdown,spring会自动匹配
private static final String CLOSE_METHOD_NAME = "close";
private static final String SHUTDOWN_METHOD_NAME = "shutdown";
private static final Log logger = LogFactory.getLog(DisposableBeanAdapter.class);
private final Object bean;
private final String beanName;
private final boolean invokeDisposableBean;
private final boolean nonPublicAccessAllowed;
......
所以destroyBean方法的bean.destroy()这里要知道的话,我们还要翻过去,跳到disposableBeans这个map是在哪里添加进去的;在本编文章最开始的,先记录的是@Resource,但是有没有发现,spring在寻找@Resouce注入点的时候其实在一个方法里面先寻找了@PostConconstrut @PreDestroy的注解方法的,所以在spring创建bean的时候就把这些注解的方法找出来放在了缓存中了,所以这里我们只需要关心这个disposableBeans是在什么时候put进去的;如果要知道是什么时候如何put进去的,我们用脚指头想都想的到肯定是在创建bean的时候找到的,上面@PostConconstrut @PreDestroy只是其中的一种销毁方法的找寻方式,那么还有好几种的销毁方法在哪里找的呢?我们还需要回到createBean的过程里面,我们看下creatBean的最后一个代码片段
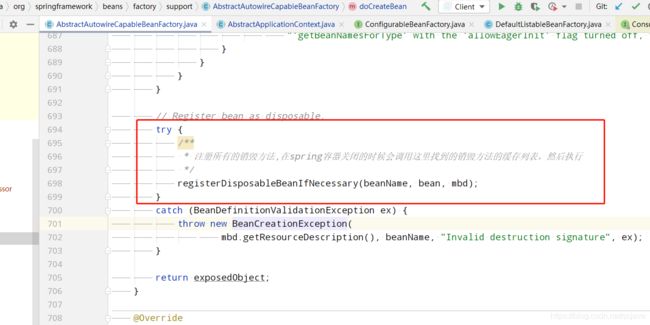
所以就先来分析了这个方法,在回头去看是如何销毁的
registerDisposableBeanIfNecessary
protected void registerDisposableBeanIfNecessary(String beanName, Object bean, RootBeanDefinition mbd) {
AccessControlContext acc = (System.getSecurityManager() != null ? getAccessControlContext() : null);
//这里判断是销毁的方法所在的bean是单例的,并且符合了解的才能加入到销毁方法的队列中
if (!mbd.isPrototype() && requiresDestruction(bean, mbd)) {
if (mbd.isSingleton()) {
// Register a DisposableBean implementation that performs all destruction
// work for the given bean: DestructionAwareBeanPostProcessors,
// DisposableBean interface, custom destroy method.
//满足条件就将一系列的销毁方法封装到销毁bean的适配器中,这里就是使用的适配器模式
//在容器关闭的时候,就会获取disposableBeans这集合,这个集合里面就存储了DisposableBeanAdapter
//而这个DisposableBeanAdapter又是DisposeBean的子类,所以DisposableBeanAdapter重写了
//DisposeBeann的destory方法,那么在容器close的时候会调用DisposableBeanAdapter的destory方法
//在DisposableBeanAdapter中会根据是那种destory类型去调用指定的销毁方法
/**
* 比如:
* 1.BeanDefinition中的定义的销毁方法(包括手动定义和自动默认定义的)
* 2.实现了DisposeBean或者AutoClosed接口的销毁方法
* 3.后置处理器中实现了的销毁方法,在后置处理器InitDestroyBeanPostProcessor找到的@PostConstruct
* 或者@preDestroy注解的方法
* 这些销毁方法都会在容器调用DisposableBeanAdapter这种的destroy方法是去判断是那种销毁方法从而调用
*/
registerDisposableBean(beanName,
new DisposableBeanAdapter(bean, beanName, mbd, getBeanPostProcessors(), acc));
}
else {
//这里应该是web使用的
// A bean with a custom scope...
Scope scope = this.scopes.get(mbd.getScope());
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + mbd.getScope() + "'");
}
scope.registerDestructionCallback(beanName,
new DisposableBeanAdapter(bean, beanName, mbd, getBeanPostProcessors(), acc));
}
}
}
/**
* Add the given bean to the list of disposable beans in this registry.
* Disposable beans usually correspond to registered singletons,
* matching the bean name but potentially being a different instance
* (for example, a DisposableBean adapter for a singleton that does not
* naturally implement Spring's DisposableBean interface).
* @param beanName the name of the bean
* @param bean the bean instance
* 将找到的销毁方法放入缓存
*/
public void registerDisposableBean(String beanName, DisposableBean bean) {
synchronized (this.disposableBeans) {
this.disposableBeans.put(beanName, bean);
registerDisposableBean这个方法看到没有,就是去注册一个销毁的适配器方法的,所以到这里就都明白了刚刚开始的调用的销毁方法destory就是调用的这个适配器中的销毁方法,在研究这个DisposableBeanAdapter的时候,我们先来看下满足什么条件会加到注册到disposableBeans;看上面的一个条件requiresDestruction(bean, mbd),这个条件比较重要,看具体的代码实现:
requiresDestruction
protected boolean requiresDestruction(Object bean, RootBeanDefinition mbd) {
/**
* 这里的判断分了好几块
* 1.首先这个bean不能使NullBean
* 2.bean中需要包含destroy方法
* 3.后置处理器中包含了destory方法,也就是通过@PreDestory注解的方法
* 4.如果实现了InitDestroyAnnotationBeanPostProcessor生命周期回调的接口,那么是会有初始化的方法和销毁方法
* spring默认添加了InitDestroyAnnotationBeanPostProcessor这个后置处理器,而这个后置处理器是表示
* 如果找到了@PreDestroy注解的方法也会返回true(这个判断很简单,判断是否是实现了DestructionAwareBeanPostProcessor
* 这个后置处理器,如果实现了,那么就去生命周期回调的销毁缓存中找,如果找到了销毁方法,那么就表示有销毁方法)
* 反正逻辑都比较严谨,需要你结合上下文来理解
*/
return (bean.getClass() != NullBean.class &&
(DisposableBeanAdapter.hasDestroyMethod(bean, mbd) || (hasDestructionAwareBeanPostProcessors() &&
DisposableBeanAdapter.hasApplicableProcessors(bean, getBeanPostProcessors()))));
}
/**
* Check whether the given bean has any kind of destroy method to call.
* @param bean the bean instance
* @param beanDefinition the corresponding bean definition
* 这个是判断是否有销毁方法的代码逻辑
* 分为两段逻辑:
* 1.如果实现了 DisposableBean或者AutoCloseable则直接返回;
* 2.否则看是否有初始化方法,这个初始化方法是从BeanDefinition中获取的getDestroyMethodName
* 如果getDestroyMethodName是默认的 (inferred),则判断是否有close或者shutdown方法,有的话返回true
* 否则直接返回程序员手动设置的初始化方法
*/
public static boolean hasDestroyMethod(Object bean, RootBeanDefinition beanDefinition) {
//如果bean实现了DisposableBean或者AutoCloseable则表示这个bean有销毁的方法,直接返回true
if (bean instanceof DisposableBean || bean instanceof AutoCloseable) {
return true;
}
/**
* 否则进入下面的逻辑
* 首先获取BeanDefinition中的销毁方法,如果这个销毁方法不为空,一般在xml中或者@Bean可以设置一个销毁方法
* 在xml中要自己去设置销毁方法,而@Bean如果你不设置,会生成一个默认的方法
* String destroyMethod() default AbstractBeanDefinition.INFER_METHOD
* 还有一个地方可以设置,前面说了有一个bean的后置处理器,叫合并bean的后置处理器
* 只要你实现了MergedBeanDefinitionPostProcessor,那么你可以实现它的方法
* postProcessMergedBeanDefinition来获取BeanDefinition设置销毁和初始化方法
* 这里的判断
* 1.首先如果destroyMethodName==‘(inferred)’,那么就只需要在bean中添加一个close或者shutdown的方法
* 那么spring的销毁的时候会自动调用close或者shutdown方法
*/
String destroyMethodName = beanDefinition.getDestroyMethodName();
if (AbstractBeanDefinition.INFER_METHOD.equals(destroyMethodName)) {
return (ClassUtils.hasMethod(bean.getClass(), CLOSE_METHOD_NAME) ||
ClassUtils.hasMethod(bean.getClass(), SHUTDOWN_METHOD_NAME));
}
return StringUtils.hasLength(destroyMethodName);
}
基本上每一行比较重要的代码我都按照自己的理解写上去了,如果你翻看到这篇笔记文章的时候请仔细看,如果看懂了那么我相信spring你也就能够理解了。
上面的代码的意思就是符合哪些条件的可以加入到销毁方法缓存列表的条件,我总结了下:
1.实现了DisposableBean的bean;
2.BeanDefinition中添加了销毁方法;
3.@Bean中添加的默认方法((inferred));
4. @PreDestroy注解方法;
我们再看下销毁的适配器DisposableBeanAdapter的具体实现细节
DisposableBeanAdapter构造
public DisposableBeanAdapter(Object bean, String beanName, RootBeanDefinition beanDefinition,
List<BeanPostProcessor> postProcessors, @Nullable AccessControlContext acc) {
Assert.notNull(bean, "Disposable bean must not be null");
//销毁方法所在的bean对象
this.bean = bean;
this.beanName = beanName;
//这个属性invokeDisposableBean是表示你的销毁方法是否是实现了DisposableBean并且bean中存在destroy方法
this.invokeDisposableBean =
(this.bean instanceof DisposableBean && !beanDefinition.isExternallyManagedDestroyMethod("destroy"));
//是否允许非public的构造或者普通方法执行
this.nonPublicAccessAllowed = beanDefinition.isNonPublicAccessAllowed();
this.acc = acc;
//inferDestroyMethodIfNecessary是找到BeanDefinition中定义的销毁方法或者是默认定义的close或者shutdown方法,也或者是
//实现了AutoClosed中的close方法
String destroyMethodName = inferDestroyMethodIfNecessary(bean, beanDefinition);
/**
* 这个if条件的意思就是说:在上面找到的销毁方法不为空,并且bean没有实现了DisposableBean以及bean中不包含destroy方法
* 和BeanDefinition中包含上面找到的方法,那么这个条件到底是什么意思呢?
* 意思就是找到没有实现DisposableBean并且又可能实现了Autoclosed或者定义了默认的销毁方法:
* 1.实现了AutoClosed的销毁方法close
* 2.定义了当BeanDefinition中销毁方法是(inferred)中的close或者shutdown方法
* 3.BeanDefinition中定义了销毁方法
*/
if (destroyMethodName != null && !(this.invokeDisposableBean && "destroy".equals(destroyMethodName)) &&
!beanDefinition.isExternallyManagedDestroyMethod(destroyMethodName)) {
this.destroyMethodName = destroyMethodName;
//找到这个方法
Method destroyMethod = determineDestroyMethod(destroyMethodName);
if (destroyMethod == null) {
if (beanDefinition.isEnforceDestroyMethod()) {
throw new BeanDefinitionValidationException("Could not find a destroy method named '" +
destroyMethodName + "' on bean with name '" + beanName + "'");
}
}
else {
//这边定义了销毁方法的参数只能为一个,并且不能是Boolean的参数
Class<?>[] paramTypes = destroyMethod.getParameterTypes();
if (paramTypes.length > 1) {
throw new BeanDefinitionValidationException("Method '" + destroyMethodName + "' of bean '" +
beanName + "' has more than one parameter - not supported as destroy method");
}
else if (paramTypes.length == 1 && boolean.class != paramTypes[0]) {
throw new BeanDefinitionValidationException("Method '" + destroyMethodName + "' of bean '" +
beanName + "' has a non-boolean parameter - not supported as destroy method");
}
destroyMethod = ClassUtils.getInterfaceMethodIfPossible(destroyMethod);
}
this.destroyMethod = destroyMethod;
}
//这里是找到后置处理器中定义的销毁方法,也就是@PreDestroy
this.beanPostProcessors = filterPostProcessors(postProcessors, bean);
}
private String inferDestroyMethodIfNecessary(Object bean, RootBeanDefinition beanDefinition) {
/**
* 这个方法的大概意思就是找到BeanDefinition中定义了销毁方法或者spring为bean生成的默认销毁方法或者是实现了AutoCloseable
* 下面的if两个判断,第一个if判断默认的方法是否是“(inferred)”,如果默认的方法是(inferred),那么代表是spring默认产生的
* spring默认产生的情况下会自动识别close和shutdown
* 如果第一个条件不满足,那么就看下是否实现了AutoCloseable,这个条件的前置条件是BeanDefinition中没有定义销毁的方法,如果定义了
* 就直接返回直接定义的默认销毁方法,否则检查是否实现了AutoCloseable接口,记住的是AutoCloseable中的默认实现关闭方法也是close
* 所以第二个条件只需要判断BeanDefinition中没有定义销毁方法但是bean实现了AutoCloseable的情况下
* 会去看下这个bean中有没有close或者shutdown方法
* 那么我们可以得出一个结论就是:
* 1.当BeanDefinition中定义了初始化方法和实现了
* AutoCloseable或的情况下,只会执行BeanDefinition中定义的销毁方法
* 2.当BeanDefinition中定义了初始化方法和实现了
* DisposableBean或的情况下,都会执行
*/
String destroyMethodName = beanDefinition.getDestroyMethodName();
if (AbstractBeanDefinition.INFER_METHOD.equals(destroyMethodName) ||
(destroyMethodName == null && bean instanceof AutoCloseable)) {
// Only perform destroy method inference or Closeable detection
// in case of the bean not explicitly implementing DisposableBean
if (!(bean instanceof DisposableBean)) {
try {
return bean.getClass().getMethod(CLOSE_METHOD_NAME).getName();
}
catch (NoSuchMethodException ex) {
try {
return bean.getClass().getMethod(SHUTDOWN_METHOD_NAME).getName();
}
catch (NoSuchMethodException ex2) {
// no candidate destroy method found
}
}
}
return null;
}
return (StringUtils.hasLength(destroyMethodName) ? destroyMethodName : null);
}
上面的构造就是在注册销毁集合缓存的时候调用的构造方法,其实这个构造简单来说就是我上面写的很清楚的就是将哪几种销毁的类型定义好,等spring调用销毁的时候,适配器才能知道你的bean中定义了那些销毁的方法,需要怎么来调用,比如你定义了3个,那么这3个是否符合条件可以在销毁的时候被调用,上面的代码简单来说就是:
1.如果实现了DisposableBean ,单独拿出来;
2.后置处理器的@PreDstroy的单独拿出来;
3.实现了AutoCloseable和spring默认生成的销毁方法以及BeanDefinition中定义的销毁方法单独拿出来,分为三类做好记录(因为spring默认创建的销毁方法是close或者shutdown,而AutoCloseable实现的接口方法也是close,所以我猜spring这里是单独拿出来的)。
我们知道了spring是在创建bean的时候把所有的销毁方法都拿出来然后通过DisposableBeanAdapter适配器来封装好,当你spring容器关闭调用销毁方法的时候destory就会调用到适配器的destory方法,而这个适配器已经做好了封装,就等你调用了,你调用它就知道有哪些销毁方法或者销毁的逻辑可以使用了;所以我们再看下适配器DisposableBeanAdapter中的销毁方法
/**
* 这个是适配器中的销毁方法
* 这个销毁方法处理的是所有的销毁方法
* 销毁方法有:
* 1.BeanDefinition中手动定义的
* 2.@Bean或者xml中定义的默认销毁方法
* 3.@PreDestroy定义的销毁方法
* 4.实现了DisposableBean或者Autoclosed的销毁方法
*
*/
@Override
public void destroy() {
//这里调用的是销毁bean的后置处理器中定义的销毁方法,也就是@PreDestroy注解的销毁方法
if (!CollectionUtils.isEmpty(this.beanPostProcessors)) {
for (DestructionAwareBeanPostProcessor processor : this.beanPostProcessors) {
processor.postProcessBeforeDestruction(this.bean, this.beanName);
}
}
//这里调用实现了DisposableBean中的销毁方法,实现了DisposableBean的方法是destroy
if (this.invokeDisposableBean) {
if (logger.isTraceEnabled()) {
logger.trace("Invoking destroy() on bean with name '" + this.beanName + "'");
}
try {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () -> {
((DisposableBean) this.bean).destroy();
return null;
}, this.acc);
}
else {
((DisposableBean) this.bean).destroy();
}
}
catch (Throwable ex) {
String msg = "Invocation of destroy method failed on bean with name '" + this.beanName + "'";
if (logger.isDebugEnabled()) {
logger.warn(msg, ex);
}
else {
logger.warn(msg + ": " + ex);
}
}
}
/**
* 下面就是处理
* 1.BeanDefinition中或者xml手动定义的销毁方法
* 2.@Bean中定义的默认销毁方法
* 3.实现了AutoClosed的销毁close方法
*/
if (this.destroyMethod != null) {
invokeCustomDestroyMethod(this.destroyMethod);
}
else if (this.destroyMethodName != null) {
Method methodToInvoke = determineDestroyMethod(this.destroyMethodName);
if (methodToInvoke != null) {
invokeCustomDestroyMethod(ClassUtils.getInterfaceMethodIfPossible(methodToInvoke));
}
}
看到上面的方法是不是感觉逻辑一下子就清晰了,我们在回头看下销毁bean调用的方法:
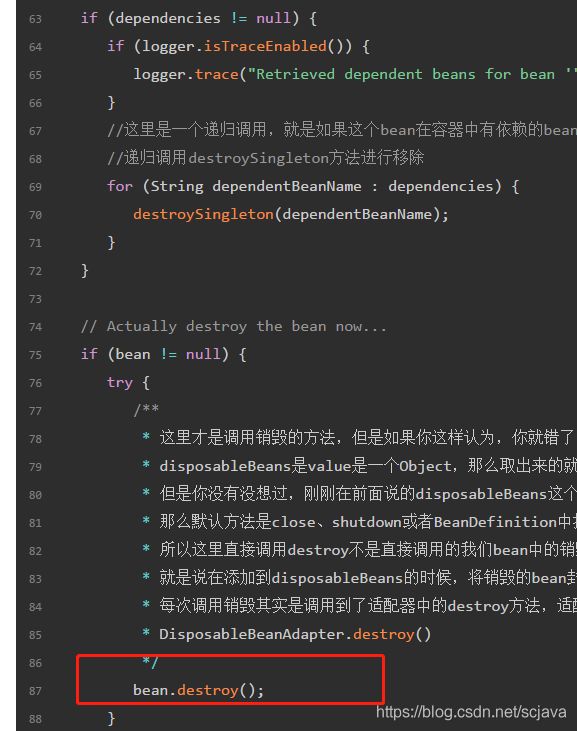
红框框这里就是调用的上面的适配器的destroy方法,它来调度,分为三类,上面我已经说了,是不是就很清晰spring的容器关闭清理bean的流程了。spring最复杂也就是销毁bean的这个步骤,其他的就是一些map的清理,map太多,我就不一一去解释这些map有什么用,比较重要的map有单例池singltonObjects,还有一二三级缓存,bean定义的map,依赖的map,beanName的map,还有后置处理器的缓存等,反正很多map的清楚,spring的销毁主要是看bean的销毁流程,bean销毁的流程要清晰,你就理解了它的思想和设计原则。
这里需要重点,有个结论:
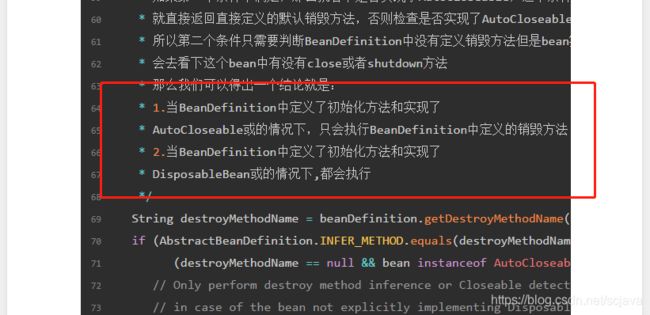
就是当你实现了DisposableBean,AutoCloseable的情况下其实是只会调用DisposableBean中的销毁的,不会调用AutoCloseable中的销毁的,这个是从源码的实现得出的结论,就不要怀疑了;
上面的结论还不够清楚,如果你定义了自己的销毁方法,通过xml方式、@Bean的方式、实现了DisposableBean方式、@PreDestory的方式,Beand中添加的销毁方法,这个时候你再实现AutoCloseable,那么是不会调用AutoCloseable中的close方法的;
还有个结论就是如果使用spring默认的方法,那么如果这个时候你实现了DisposableBean也是不会调用默认的那个close或者shutdown的方法的,这些我做了实验了,已经是得到验证的,这里就不贴了,反正这个也比较绕,再说在实际应用中,大家也不会在一个bean中定义太多销毁的方法,知道怎么取定义销毁的方法即可,我这里总结下怎么定义销毁的方法:
1.xml中添加销毁的方法参数;
2.beanFactory的后置处理器中可以对BeanDefinition进行操作,可以添加;
3.bean的后置处理器中(MergedBeanDefinitionPostProcessor)可以对BeanDefinition进行操作,可以添加;
4.@PreDestory注解可以;
5.实现DisposableBean,AutoCloseable可以实现销毁方法;
6.@Bean中默认就有,需要你自己定义close或者shutdown方法。
spring搞出这么多销毁方法的方式,大家在实际应用中可以根据实际情况使用,我觉得用的最多的应该是注解的方式,其他,大家有兴趣的可以去试一试。
销毁Bean的过程图
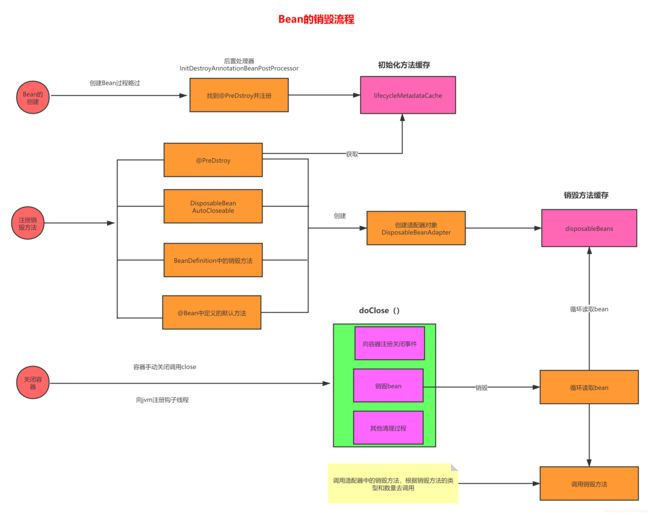
Bean的创建和销毁的整个生命周期图
Bean的生命周期到这里就差不多了,这里我按照自己的理解画了一张图,我画的图在processon上,地址是https://www.processon.com/diagraming/5f943b5af346fb06e1ea0cc5,有兴趣的可以去看下