pytorch2.0 起步
参考:https://pytorch.org/get-started/pytorch-2.0/#ask-the-engineers-20-live-qa-series
总览
特性
- faster
- more pythonic
- as dynamic as ever
torch.compile,部分零件由C++迁移到Python,加强torch.compile的新技术有TorchDynamo, AOTAutograd, PrimTorch and TorchInductor。
benchmarks 分成三类
-
HuggingFace Transformers46个模型
-
TIMM 61个模型
-
TorchBench 56个模型
精度:float32/Automatic Mixed Precision (AMP)
动机
第一:保持易用性,可编程性
第二:性能
致力:
1.高性能执行
2.内部python式
3.好的抽象用于分布式/Distributed,自动差分/Autodiff,数据加载/Data loading,加速器/Accelerators…
为什么会用C++:2017年建设Pytorch,计算上硬件加速快了15倍,内存快了2倍,所以把PyTorch内部部分转移到C++,导致它可编程性变差,也增加了代码贡献的障碍。
技术概述
Pytorch内部有好几个编译项目,
- graph acquisition
- graph lowering
- graph compilation
Graph acquisition 是过去五年我们建立PyTorch编译器的一个挑战,我们建立了torch.jit.trace, TorchScript, FX tracing, Lazy Tensors 都没有实现目标,有些灵活但是慢,有些很快但是不够灵活,有些既不灵活也不慢。TorchScript 曾经很有前景,但是它需要你的代码和代码依赖的代码发生实质性变化,所以不是一个好的PyTorch用户启动器。
TorchDynamo:寻求图可靠和快速
今年开头我们开始致力于 TorchDynamo,一种使用CPython特性的框架验证API(the Frame Evaluation API).我们使用数据驱动验证了图捕获的有效性.用了七千个用Pytorch 写Github项目作为验证集,TorchDynamo在99%的时间内正确、安全地获取了图表,开销可以忽略不计-不需要对原始代码有任何改变。我们终于突破得到了易用性和速度
TorchInductor:使用运行定义的IR快速生成代码
受到用户编写高性能custom kernels(增加使用Triton语言)启发。我们也想要一个编译后端,它使用PyTorch相似的抽象,并且足够通用以支持 PyTorch 中的广泛功能。
TorchInductor 使用一个python式 define-by-run循环级别IR,在GPUS,CPU上的C++/OpenMP(单线程多线程并行实现的方法) 自动化映射PyTorch模型到生成Triton代码。TorchInductor的核心循环级别IR包含了仅仅50个处理器,使用Python实现它,让它更容易和扩展性高。
AOTAutograd: 复用AutoGrad于超前图
如果要加速训练,不仅要捕捉用户级别的代码,也要捕捉反向传播。所以我们想再用,存在的久经考验的PyTorch autograd system,它可以提前帮我们捕捉到反向,所以可以前向和反向传递计算加速
PrimTorch: 稳定主要的operators
Pytorch有1200多个操作符,再PrimTorch项目里,我们定义一个更小,稳定的算子集合。PyTorch项目连续下降因为这些算子集合。我们目标是定义2种算子集合。
- Prim算子,大概250个,很底层,需要重新融合在一起获取更好性能
- ATen 算子,大概750个规范的算子,这些适用于已经在 ATen 级别集成的后端或无法编译以从较低级别的运算符集(如 Prim ops)恢复性能的后端。
用户体验
torch.compile函数,返回一个编译模型
compiled_model = torch.compile(model)
compiled_model保存对模型的引用,并将前向函数编译为更优化的版本。编译模型时,我们给几个knobs来调整它
def torch.compile(model: Callable,
*,
mode: Optional[str] = "default", #默认模式是尝试高效编译的预设,而不会花费太长时间进行编译或使用额外的内存。其他模式(如 reduce-overhead)可将框架开销减少更多,但会消耗少量的额外内存。Max-Autotune编译了很长时间,试图为您提供它可以生成的最快代码。
dynamic: bool = False,# 指定是否启用Dynamic Shapes的代码路径。某些编译器优化不能应用于Dynamic Shapes的程序。明确说明是要使用dynamic Shapes还是static shapes的已编译程序,有助于编译器提供更好的优化代码
fullgraph:bool = False, # 类似于Numba的nopython。它将整个程序编译成一个图形,或者给出一个错误来解释为什么它不能这样做。大多数用户不需要使用此模式。如果你非常注重性能,那么你就会尝试使用它。
backend: Union[str, Callable] = "inductor", # 指定要使用的编译器后端。默认情况下,使用TorchInductor,但还有其他一些可用
# advanced backend options go here as kwargs
**kwargs
) -> torch._dynamo.NNOptimizedModule

编译经验,默认模式倾向传递最多的好处和易用性,compile模型如上图指明了得失
import torch
import torchvision.models as models
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
模式
# API NOT FINAL
# default: optimizes for large models, low compile-time
# and no extra memory usage
torch.compile(model)
# reduce-overhead: optimizes to reduce the framework overhead
# and uses some extra memory. Helps speed up small models
torch.compile(model, mode="reduce-overhead")
# max-autotune: optimizes to produce the fastest model,
# but takes a very long time to compile
torch.compile(model, mode="max-autotune")
读取和更新属性
# optimized_model works similar to model, feel free to access its attributes and modify them
optimized_model.conv1.weight.fill_(0.01)
# this change is reflected in model
序列化
可以序列化模型的字典(等价),但不能序列化编译的模型
torch.save(optimized_model.state_dict(), "foo.pt")
# both these lines of code do the same thing
torch.save(model.state_dict(), "foo.pt")
torch.save(optimized_model, "foo.pt") # Error
torch.save(model, "foo.pt") # Works
推理和导出
生成一个编译模型后,真实模型部署前,使用热启动warm up步骤,缓解初始服务期间的延迟峰值
torch.export导出,该模式会仔细导出整个模型和保护基础结构,以用于需要保证和可预测延迟的环境。
# API Not Final
exported_model = torch._dynamo.export(model, input)
torch.save(exported_model, "foo.pt")
debugging问题
编译错误,很有可能是你代码有错。
使用The Minifier.工具,自动将问题减少至小片代码,你可以提交到GitHub上。
如果你的代码没有加速,使用torch._dynamo.explain工具可以解释哪一部分代码出现了 “graph breaks”。 “graph breaks”会阻碍编译器加速代码
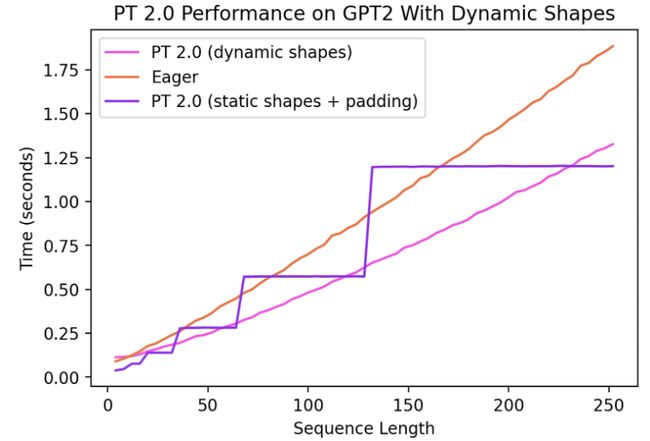
Dynamic Shapes
PyTorch代码的共性就是都支持 dynamic shapes。允许模型接受不同大小的张量,而不会在每次形状更改时引起重新编译。
如今,对Dynamic Shapes 支持还很有限并且在进行种,会在稳定版全部集成。
分布式
与eager模式相比,DistributedDataParallel (DDP) , FullyShardedDataParallel (FSDP) 两种wrapper在编译模型上提供了显著性能和内存利用。
DDP 依赖反向传播计算时AllReduce通信重叠,并将较小的 per-layer AllReduce操作分组到“buckets”中以提高效率。
由TorchDynamo编译的AOTAutograd函数在防止通信重叠(使用原生DDP编译时),但是通过为每个“bucket”编译单独的子图,并允许通信操作在子图外部和之间发生来恢复性能。编译模式下的 DDP 支持目前也需要 static_graph=False。
FSDP是Pytorch测试版, 抽象级别更高,可以调整子模块,有更普遍的配置选项。有一定兼容性问题,之后会改善
模型
参考:https://pytorch.org/blog/Accelerating-Hugging-Face-and-TIMM-models/
Hugging Face models
从hugging face下载一个预训练模型,并优化
import torch
from transformers import BertTokenizer, BertModel
# Copy pasted from here https://huggingface.co/bert-base-uncased
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased").to(device="cuda:0")
model = torch.compile(model) # This is the only line of code that we changed
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt').to(device="cuda:0")
output = model(**encoded_input)
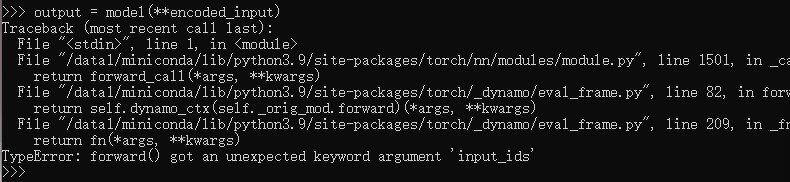
再试一次,恢复

TIMM模型
import timm
import torch
model = timm.create_model('resnext101_32x8d', pretrained=True, num_classes=2)
opt_model = torch.compile(model, backend="inductor")
opt_model(torch.randn(64,3,7,7))
个人感想
1.一种技术进步可能依赖另一种技术。比如TorchDynamo实现了易用性和速度,依赖了CPython的特性
2.Pytorch框架背后站了大佬看好,huggface,等 。强强联合,彼此成就
3.通过系统学习Pytorch,HuggingFace可以一定程度上补全知识框架,知道比如各种领域的经典模型有哪些,还有更为基础的底层知识(比如浮点对于速度的影响)