【论文阅读13】Hybrid embedding-based text representation for hierarchical multi-label text classification
论文十问十答:
Q1论文试图解决什么问题?
Q2这是否是一个新的问题?
Q3这篇文章要验证一个什么科学假设?
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
Q5论文中提到的解决方案之关键是什么?
Q6论文中的实验是如何设计的?
Q7用于定量评估的数据集是什么?代码有没有开源?
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
Q9这篇论文到底有什么贡献?
Q10下一步呢?有什么工作可以继续深入?
论文相关
论文标题:基于嵌入的混合文本表示,用于分层的多标签文本分类
发表时间:2022年
领域:自然语言处理
发表期刊:Expert Systems With Applications,一区
代码地址:https://github.com/EiraZhang/LACO.
摘要
许多真实世界的文本分类任务通常处理大量以层次结构或分类法组织的密切相关的类别。当分层多标签文本分类(HMTC)需要处理大量密切相关的类别集时,它已经变得相当具有挑战性。整个层次结构中所有类别的结构特征及其类别标签的词语义非常有助于提高大群密切相关类别的文本分类精度,这在大多数现有的HMTC方法中都被忽略了。在本文中,我们提出了一种基于嵌入的混合文本表示HMTC。
- 首先,混合嵌入包括层次结构中类别的
图嵌入和类别标签的词嵌入。利用基于结构深度网络嵌入的图嵌入模型,同时对给定类别的全局和局部结构特征进行编码,使该类别在结构上具有可判性。我们进一步使用词嵌入技术对层次结构中每个类别标签的词语义进行编码,使不同的类别在语义上具有可区分性。 - 其次,我们提出了一种基于
双向门控循环单元网络模型的逐级HMTC方法,并将混合嵌入用于学习分层文本的表示。 - 最后但并非最不重要的,广泛的实验在五个大规模的真实数据集与先进的层次和平面多标签文本分类方法,实验结果表明,我们的方法非常有竞争力的先进方法的分类精度,特别是维护计算成本而实现优越的性能。
1.引言
关键字:
HC:Hierarchical classification层次分类器
HMC: multi-label classification多标签文本分类
随着文本文档数量的急剧增加,现实世界中许多重要的分类问题都由大量的类别组成。这些类别通常非常相似,并被进一步组织成一个层次结构或分类法。大型分层文本存储库的典型例子是web目录(例如,开放目录项目/DMOZ),医学分类方案(例如,医学主题标题),图书馆和专利分类方案,和维基百科的主题分类。当文本分类任务需要处理上述层次结构中的大量密切相关的类别集时,它对于提高分类精度无疑已经变得非常具有挑战性。
层次分类(HC)是一种更为复杂的分类任务,其中类别不是不相交的,而是组织成一个层次结构。在层次结构中,一个对象可以属于一个、多个类别,或者根本不属于任何类别,这通常被称为多标签分类。层次结构以树的形式形式化类别之间的关系,其中类别至少有一个父类别,或者是一个有向无环图,其中一个类别可能有多个父类别,可以进一步作为外部知识引入,以提高分类性能。与HC分类器相比,所谓的平面分类器经常忽略层次结构,将其“扁平”到叶节点的层次,进行多标签文本分类。来自层次结构的不同层次的所有类别都是相互独立的。典型的平面分类器是FastText和结构化自注意分类器。然而,在处理大量类别和属性的情况下,层次结构信息对于构建高效的层次多标签分类(HMC)算法无疑是至关重要的。HMC允许每个对象除了给定的父类别及其子类别之外,还可以进一步关联到类别层次结构或分类法的几个不同路径。如今,HMC已经被广泛应用于一些文本分类任务和生物信息学任务(例如,蛋白质功能预测)。在本文的其余部分,我们将工作局限于HMC的文本分类,即层次多标签文本分类(HMTC)。
大多数现有的HMTC方法可分为两大方面:全局HMTC和局部HMTC
- 全局方法为整个层次结构训练单个分类器,并可以同时将对象与层次结构中的相应类别关联起来。全局HMTC方法似乎比局部方法需要更少的训练参数,而且也很少出现错误传播问题。然而,全局方法的训练模型在逻辑上是复杂的,由于丢失了关于类别及其结构关系的先验信息,经常遭受缺乏拟合。
- 相比之下,局部HMTC方法试图以自上而下的方式发现类别层次结构中特定区域的特异性,然后结合之前的预测来提供最终的分类结果。一个特定的区域可能是任何节点或任何层次。全局HMTC方法需要相对较少的训练参数,因此比局部HMTC方法有更低的计算成本,但是,由全局方法构建的分类器不够灵活,无法满足类别结构的变化。对于具有大量通常非常相似的类别标签的大量文本数据的分层多标签分类尤其如此。此外,值得注意的是,一些实验观察表明,并不是所有的HMTC分类器总是比一些平面分类器有更好的精度。即使已经考虑了HMTC的层次结构,如HATC和HDLTex。该现象中所存在的问题值得本文进一步探讨。
然而,根据上面提到的内容,在设计一个有效的HMTC解决方案时,仍然存在许多具有挑战性的固有问题。首先,我们认为类别标签的词语义对于使不同类别的语义可区分性是非常有帮助的。在现实世界的分类系统中,层次结构中的每个类别都有自己的标签名称,具有明确和可区分的语义意义。不幸的是,几乎所有现有的HMTC方法都忽略了层次结构中类别标签的单词语义。其次,应同时考虑一个特定类别在整个层次结构中的全局和局部结构特征,以使其在结构上具有可区分性。关于HMTC的一个明显的事实是,要分类的文本通常与整个层次结构的几个不同路径中的多个类别相关联。对于整个层次结构中的一个类别,其局部结构特征可以通过其直接的父母和子女类别或该类别处于层次结构层次的位置来描述。它的全局结构特征可能是在与整个层次结构中的类别相关的不同路径中的多个类别。然而,现有的全局和局部HMTC方法不能同时捕获这两种结构特征。全局的HMTC可以为整个层次结构建立一个通用的分类。本地HMTC,包括HDLTex和HFT-CNN,只能捕获一些局部结构特征。第三但同样最不重要的是,HMTC应该采用高效的文本表示模型,以在保持较低计算成本的同时实现更好的性能。
为了解决上述问题,在本文中,我们提出了一种基于嵌入的混合文本表示,通过它,我们可以逐级地自动预测最相关的类别。具体来说,本文的贡献如下。 - 首先,提出了一种混合嵌入方法,包括类别的图嵌入和类别标签的词嵌入,采用基于结构深度网络嵌入(SDNE)的图嵌入模型同时对给定类别的全局和局部结构特征进行编码,使类别在结构上具有可判性。我们进一步使用词嵌入技术对层次结构中每个类别标签的词语义进行编码,使不同的类别在语义上具有可区分性。将基于图嵌入的向量和基于词嵌入的向量连接起来,以表示层次结构中一个类别的综合特征。
- 其次,我们提出了一种基于双向门控循环单元(BiGRU)网络模型的分层HMTC方法,以及用于学习逐级的文本表示的混合嵌入。BiGRU是双向长短期记忆(BiLSTM)模型的简化版本,其结构较简单,训练参数较少,收敛性较好。
- 最后但并非最不重要的是,我们在5个规模的真实世界数据集上进行了广泛的实验,并与最先进的层次和平面多标签文本分类方法进行了比较,实验结果表明,该方法在分类精度方面优于现有方法,特别是在保持计算成本的同时提高了计算性能。
据我们所知,这是第一次综合尝试同时使用基于类别结构的图嵌入和基于标签语义的词嵌入来解决层次多标签文本分类问题。
本文的组织结构如下:
- 第2节是相关的工作。
- 第3节中,我们给出了HE-HMTC方法的框架,讨论了如何为文本表示编码结构特征和标签语义,以及如何对文本进行分类。
- 第4节中,我们进行了广泛的实验,并讨论了结果。
- 第5节是结论
2.相关工作
在过去的几十年里,基于深度学习的分类器已经开发出来,用于自动文本分类。这说明了它们在处理大规模语料库方面的巨大潜力,以及它们在自动特征提取方面的鲁棒性。基于深度学习的文本分类将文本表示和分类器集成起来,用反向传播算法更新模型参数,自动选择特征,最终完成分类。文本词通常用单词嵌入来表示。预先训练好的单词嵌入是自然语言处理领域中每个深度学习模型的重要组成部分之一。广泛使用的单词嵌入方法包括word2vec、 Glove和Elmo。它们将文本中的单词映射到一个低维的密集向量上,并且具有相似语义的单词具有接近的向量。许多基于卷积神经网络(CNN)、递归神经网络(RNN)或其变体的深度学习模型已经被提出,例如:fastText,BiLSTM,structured self-attention model。基于神经网络的方法对传统的平面分类问题有显著的影响,并成功地说明了它们在文本分类任务中的潜力。近年来,层次多标签文本分类(HMTC)在需要处理在层次结构或分类法中组织的大量密切相关的类别集时,在提高文本分类精度方面受到了越来越多的关注。早期的分层文本分类工作是基于贝叶斯模型等一些模型和支持向量机(SVM),其中,多类文本分类经常被探索,而不是使用层次文本分类(HMTC)。HMTC通常大致可以分为两种方法:全局和局部的方法。
全局HMTC方法同时为整个层次结构/分类法中的所有类别建立一个单一的全局模型。使用单一的全局模型的好处是,它们缓解了模型参数的爆炸问题,而且所有类别的所有参数都远远低于局部方法。由于全局方法以平面模型为主干,因此它们通常很难捕获不同的类别层,而且训练过的分类器不够健壮,无法解释类别组成的变化。由于较低水平的每组训练样本数量要比较高水平的训练样本数量小得多,因此父类别的判别特征在子类别中可能无法区分。最先进的全局HMTC方法是基于层次神经注意的文本分类器(HATC)。HATC通过引入注意机制来处理上述全局方法的缺点,该注意机制可以编码类别的层次结构,以提高文本分类性能。它提出了一个端到端全局神经注意的模型,并在两个基准数据集上以较低的计算成本优于大多数现有的HMTC分类器。
与全局方法相比,目前关于局部方法的研究越来越多。局部方法通常会充分利用层次结构中的结构特征来训练多个分类器。局部方法可以采用自上而下的方法为层次结构中的每个节点或每个层次级别训练局部分类器,但根节点除外。针对每个节点或每个层次级别的文本分类任务通常分别基于二值分类器或多类分类器。在测试阶段使用局部层次分类器时,这种自上向下的局部方法基本上有一种策略来防止类级的矛盾。然而,局部方法通常比全局方法有更高的计算成本,因为来自许多局部分类器的巨大参数变量可能会导致参数爆炸。当自顶向下的文本分类深入到层次结构中的较低层次时,从较高级别的错误传播到较低级别的错误传播也可能会导致严重的性能下降。
最先进的局部HMTC方法的技术水平是HDLTex,HFT-CNN,用于分层微调CNN网络,和HARNN用于基于层次注意的递归神经网络。HDLTex是一种局部HMTC方法,它在每个节点上训练一个分类器,并比传统的具有自上而下结构的非神经基础模型表现出优越的性能,但是,由于子模型的数量随着子树的数量呈指数增长,它可能随着类别的数量而降低。HARNN是一种逐层次的HMTC方法,它开发了一个基于层次注意的层次循环层来捕获文本和层次结构之间的关联。HFT-CNN最初是专注于HMTC的短篇文本。它使用单词嵌入和卷积层作为参数来学习类别层次结构的下一层次。采用微调技术,使上层分类结果对下层分类有贡献。在本文中,我们对最先进的HMTC方法进行了简要的分析和比较,如表1所示。

在表中,HMTC Type是指定HMTC方法是全局的还是局部的。训练分类器是表示一个分类器是为整个层次结构、每个节点还是每个层次进行训练的。结构依赖信息是用来描述HMTC使用了哪些结构依赖信息。我们可以发现,所有列出的方法都利用了两个相邻层次之间对父母/孩子的直接依赖。标签语义是为了显示HMTC方法是否考虑了类别标签的词语义。分类器类型用于指定从二值分类器、多类分类器和多标签分类器中选择的训练后的分类器的类型。最后一列告诉我们,相应方法的源代码可以在网上找到。以HFT-CNN为例,HFT-CNN是一种局部HMTC方法,训练每个层次训练多类分类器;自顶向下的文本分类利用了两个相邻级别之间的父母/孩子的直接依赖关系;它不考虑类别标签的词语义,其源代码可以在网上找到和获得。重要的是,我们可以发现:
- 1)这些HMTC方法无法学习类别标签的单词语义。然而,我们认为类别标签的词语义对于使不同类别的语义可区分性是非常有帮助的。为了提高HMTC的性能,应考虑类别标签的Word语义。
- 2)所有这些方法都只考虑类别层次结构中的局部结构信息,如直接父母和子女类别之间的依赖关系。我们认为,应该考虑与整个层次中类别相关的不同路径上的全局结构信息,使不同类别在结构上具有可区分性。
现有的与我们的方法最相似的工作是HDLTex和HFT-CNN,在这些最先进的HMTC方法中提到上述。HDLTex和HFT-CNN两种方法都采用逐层次分类,设计多类分类器对每个层次的文本进行分类。因此,分层的多标签文本分类被简化为为从根到叶的每条路径中的文本找到一组标签。另一方面,我们的方法与HDLTex和HFT-CNN都有明显的区别。也就是说,我们采用了全局和局部的基于类别结构的图嵌入和基于类别标签语义的词嵌入来解决HMTC问题。
3.建议的方法
3.1方法框架
我们提出了一种基于嵌入的混合文本表示,缩短为HE-HMTC。它是一种逐层的局部HMTC方法,在分类层次结构或分类法的每个级别上以自上而下的方式训练分类模型。我们的HE-HMTC方法的框架如图1所示,它总体由四个主要部分组成。

图1 在层次结构的第1级上的文本分类的框架
- 1)基于BiGRU的文本表示。我们使用双向GRU模型(BiGRU)对文本信息进行编码,以获得第l级文本的向量表示,记为 h l h_l hl。我们使用BiGRU进行原始文本表示的原因是,BiGRU是广泛用于文本表示的BiLSTM的简化版本,而且它的网络结构相对较简单,与BiLSTM模型相比,训练少且参数具有更好的收敛性。
h l h_l hl是通过连接 h 1 ⃗ \vec{h_1} h1和 h n ⃗ \vec{h_n} hn来构造的,其中 h n ⃗ \vec{h_n} hn和 h 1 ⃗ \vec{h_1} h1分别表示通过向前和向后输入单词嵌入而获得的文本表示. - 2)一个预先获得的图嵌入集,其中包括在层次结构中的每个类别标签的特征嵌入.类别嵌入同时考虑了类别标签的结构特征和词语义。类别中嵌入的特征包括类别在整个层次中的图形嵌入和类别标签中的单词嵌入。采用基于SDNE的图嵌入和word2vec词嵌入,分别捕获类别层次的结构特征和每个类别标签的语义特征。类别嵌入的向量是低维的、密集的,可以包含相应类别的全局和局部结构特征及其词语义.
- 3)基于l级分类器的混合嵌入式文本表示。将l-1级文本的分类类别记为 p l − 1 p_{l−1} pl−1,然后通过查找预先获得的类别嵌入集,可以得到与 p l − 1 p_{l−1} pl−1对应的类别嵌入。这里与 p l − 1 p_{l−1} pl−1对应的类别嵌入表示为 c l − 1 i c^i_{l−1} cl−1i,用于协助下一个较低的l级的分类。然后,我们将 h l h_l hl与 c l − 1 i c^i_{l−1} cl−1i连接起来,以获得一个新的文本表示 d l d_l dl,它将被用作当前级别l的分类器的输入。
- 4)采用全连接层(FC)加上softmax层来对第l级的文本进行分类。l级文本的分类类别 p l p_l pl被记录下来,并将进一步用于下一个较低的l + 1的分类,直到在叶节点级进行分类。然后,通过多个非线性变换对y进行解码操作,尝试恢复输入数据,解码结果为x。
3.2 混合类别嵌入
我们分别使用结构深度网络嵌入(SDNE)模型和word2vec方法进行图嵌入和单词嵌入,我们选择SDNE的原因是它可以同时学习和捕获层次结构的局部和全局结构特征。SDNE是一种设计用于在低维空间中表示图的图嵌入方法并且尽可能保留图形属性信息。
3.2.1.类别结构的图形嵌入
我们使用SDNE方法来学习类别层次结构中每个节点的结构特征。我们选择SDNE的原因是它可以同时学习和捕获层次结构的局部和全局结构特征。SDNE使用一个深度自动编码器来学习图的局部和全局结构特征。深度自动编码器是一种数据压缩算法。首先,通过多个非线性变换将输入数据x编码到一个低维表示空间中(例如,一个多层完全连接的神经网络),并得到了数据的低维表示y。然后,通过多个非线性变换对y进行解码操作,尝试恢复输入数据,解码结果为 x ^ \hat{x} x^.深度自动编码器通过最小化x和 x ^ \hat{x} x^之间的差异,确保在低维表示y中保留了足够的原始数据信息.
在这里,我们给出了一个数学符号的统一表示,如下。我们使用x的粗体斜体小写字母表示向量,X的粗体大写字母表示矩阵,H的斜体大写字母表示一个集合,标量变量的形式x的斜体小写字母,拉丁字母形式的α,β,ϑ表示系数。
在本文中,一个类别层次可以记为H =(V,E),其中,V={v1,⋯,vn}表示节点集,E = {ei,j}n i,j=1表示边集。每个边 e i , j e_{i,j} ei,j都有一个权重 w e i g h t i , j = 1 weight_{i,j}=1 weighti,j=1。如果在 v i v_i vi和 v j v_j vj之间没有边,那么 s i , j s_{i,j} si,j就等于0。深度自编码器的损失函数定义为Eq.

其中,X是图的邻接矩阵, X ^ \hat{X} X^是重构的邻接矩阵。符号⊙表示阿达玛乘积。符号B是一个用于处理图过于稀疏的问题的矩阵。对于B中的任何元素 b i , j b_{i,j} bi,j,如果 s i , j = 0 s_{i,j}=0 si,j=0,这时的 b i , j = 1 b_{i,j}=1 bi,j=1,否则, b i , j b_{i,j} bi,j被分配了一个超参数β。 符号F表示矩阵的弗罗比尼乌斯范数。损失函数包含三个附加部分。
- 第一部分是减小X和 X ^ \hat{X} X^之间的差值,以确保具有相似邻居的节点具有相似的节点向量,因此,保留了图的全局结构特征. y i y_i yi和 y j y_j yj分别是第i个节点和第j个节点的向量表示.α是一个人为指定的系数.
- 第二部分旨在减少与一条边相关联的两个节点的向量表示之间的差异,以确保具有边连接的两个节点的向量表示是相似的.因此,该图的局部结构特征也被保留了下来。
- 在第三部分中, L r e g L_{reg} Lreg是一个防止过拟合的L2-范数正则化器,而ϑ是正则化系数。
对于具有m个层次的类别层次结构H, v l i v^i _l vli表示H中第l级的第i个节点,其中1 ≤ l ≤ m,1 ≤ i ≤ n l n_l nl,而 n l n_l nl是指在层次结构H的第l级上的类别数.首先,H中的每个节点都可以用SDNE编码为一个低维致密向量,用Eq表示。

其中 g l i g^i _l gli为节点 v l i v^i_l vli的结构嵌入向量,H是类别层次结构,由SDNE算法生成的节点向量 g l i g^i_l gli保留了层次结构中与节点 v l i v^i_l vli对应的类别的全局和局部结构信息,它反映了类别在层次结构中的位置信息以及类别之间的结构关系。
3.2.2 Word嵌入的类别标签
Word嵌入技术作为类别嵌入的有用补充.它可以进一步区分兄弟节点中的一个节点和另一个节点,这是SDNE很难区分的。Word嵌入可以捕获类别标签的单词语义,这些标签描述了与类别关联的语言上下文。例如,由于相同的父节点,层次结构中的兄弟节点/类别往往具有相似的位置和结构信息,所以SDNE方法不能区分这些兄弟姐妹类别。在自然语言处理领域,单词嵌入保留了一个单词的语义信息,因此,我们利用类别名称的词嵌入来计算类别的语义信息向量。
对于类别节点 v l i v^i_l vli,其标签名称由k个单词word1、word2、⋯、wordk组成.假设k个单词对应的单词嵌入为(w1、w2、⋯、wk),然后我们可以计算出方程Eq中 v l i v^i_l vli的语义信息向量.

对于只包含一个单词的类别标签,它的语义信息向量只是其标签名称的单词嵌入。
3.2.3 类别信息混合嵌入
一旦我们得到了图嵌入向量 g l i g^i_l gli和单词嵌入 s l i s^i_l sli,通过将向量 g l i g^i_l gli与向量 s l i s^i _l sli连接起来,我们可以得到节点 v l i v^i_l vli的混合嵌入,这可以在Eq中定义.

其中,符号⊕表示两个向量的串联操作。
3.3 分类模型
假设有一个文本用n个单词进行分类(分别表示为word1、word2、⋯、wordn,它们对应的单词嵌入向量分别为(w1、w2、⋯、wn).HE-HMTC方法将对文本进行逐级分类,以进行分层的多标签文本分类。第l级的分类模型如下。首先,使用双向GRU来学习第l级文本的表示,如方程式所示。

在第1级的文本的向量表示 h l h_l hl是通过连接 h 1 ⃗ \vec{h_1} h1和 h n ⃗ \vec{h_n} hn来构造的,也就是说, h l ⃗ = h 1 ⃗ ⊕ h n ⃗ \vec{h_l}=\vec{h_1}⊕\vec{h_n} hl=h1⊕hn, h 1 ⃗ \vec{h_1} h1和 h n ⃗ \vec{h_n} hn分别表示通过向前和向后输入单词嵌入而获得的文本表示。在HE-HMTC中,l级的分类器需要考虑之前的l-1级的分类结果 p l − 1 p_{l−1} pl−1。假设 p l − 1 p_{l−1} pl−1是与类别节点 v l − 1 i v^i_{l−1} vl−1i关联的类别,通过查找预先获得的类别嵌入集,我们可以在l-1级得到文本的类别嵌入 c l − 1 i c^i_{l-1} cl−1i。
然后,我们通过将旧的文本表示 h l h_l hl与 c l − 1 i c^i_{l−1} cl−1i连接起来,得到一个新的文本表示 d l d_l dl,即 d l = c l − 1 i ⊕ h l dl=c^i_{l−1}⊕h_l dl=cl−1i⊕hl。因此,新的文本表示 d l d_l dl现在包含了在l-1级的分类结果的信息。值得注意的是,在第一级中没有可用的类别嵌入。在本例中, d 1 d_1 d1 = h 1 h_1 h1.
最后,我们使用一个全连接层(FC)和一个softmax层来对第l级的文本进行分类,如Eq所示。

其中,符号W1和W2分别是从输入层到隐藏层和从隐藏层到输出层的fc的权重矩阵。符号b1和b2是偏差。此外,我们还使用交叉熵函数来计算损失。softmax是在l级的所有类别上计算的,我们得到了分类结果pl也是l级的。
本文提出的方法逐层对层次结构中的每个层次进行上述分类操作,直到得到最后一层的分类结果为止。我们的方法的一个明显的优点是,我们可以利用上层的分类结果来协助下一级的分类。另一个优点是预先训练的混合类别嵌入,这将非常有助于提高分类精度。当然,作为硬币的另一边,我们的方法的缺点是它需要额外的计算成本来预训练混合类别嵌入。
4.实验
4.1 实验描述
在实验中,我们使用了5个真实的数据集,每个数据都有层次类别。这些实验的数据集如下:
- WOS :自科学网络,曾经在工作中使用过的数据。
- Amazon:自于亚马逊的产品评论
- BestBuy,WebService:来自于网络服务,数据集WebService是在本文中被采用和创建的,并进一步被上传到GitHub上.以及我们的HE-HMTC方法的源代码.
这五个数据集都适用于我们的方法,因为它们不仅具有用于基于结构的图嵌入的层次类别结构,而且层次结构中的每个类别标签都必须是具有特定语义的字符串,用于基于语义的单词嵌入.这五个数据集的统计如表2所示:

数据集下载地址: - https://data.mendeley.com/datasets/9rw3vkcfy4/2.
- https://www.kaggle.com/kashnitsky/hierarchical-text-classification.
- https://github.com/BestBuyAPIs/open-data-set.
- https://www.programmableweb.com/category/all/apis.
- http://wiki.dbpedia.org/.
- https://github.com/lxf770824530/HE_HMC.
- https://github.com/kk7nc/HDLTex.
- https://github.com/ShimShim46/HFT-CNN.
- https://github.com/649453932/Chinese-Text-Classification-Pytorch.
- https://github.com/bojone/bert4keras.
4.2 基线算法
我们使用两种最先进的多标签分类器作为基线,以验证我们的HEHMTC方法的分类性能。它们分别是用于多标签文本分类的分层文本分类器和平面文本分类器。在本文中,我们将把我们的HE-HMTC方法与我们提到的更多数据集进行比较。
最先进的层次多标签文本分类器是HDLTex12和HFT-CNN13。与数据集OWS和DBpedia相比,这两种分层文本分类方法对许多现有的平面或分层文本分类器都具有更高的分类精度,它们的源代码也可以在线获得。
另一方面,最先进的平面分类器包括最大池的双向LSTM或平均池化多层感知器(MLP),和 FastText。这三种方法都可以在网站上找到,另外一种最受欢迎的平面分类器就是Bert模型。表3是是所有基线模型、对比模型以及我们的模型。我们还给出了其中提出它们的相关文献。

这真的是一个良心的作者,他一次将所有的代码、数据集、相关对比模型的论文全部都告诉了别人。
4.3 实验配置
4.3.1 实验环境
1.系统环境
我们的实验是在Windows10操作系统上进行的,该操作系统是用Keras框架和Python3.6语言构建的。硬件包括GPU与NVIDIA RTX2080 SUPER,和内存8 GB。
2.数据预处理
- 首先提取文本和每个级别的类别标签。
- 第二步是清理数据,以删除文本中对分类任务无效的标点符号和停止单词。
- 第三步对文本和相应的标签进行打乱,将训练集和测试集除以80%到20%的比例。
- 最后,我们使用picke模块序列化数据并将其保存到磁盘以使用模型训练。
3.预训练
- graph embedding(文本结构图嵌入):
- 训练模型:SDNE
- 维度:300
- word embedding:
- 训练模型:glove
- 维度:300
4.模型
并采用100个隐藏单元的双层双向GRU,将输入线性变换的单位的分数分别设为0.2。输出层的维度是根据当前级别上的类别数量来设置的。我们将数据集中的文本处理为标准长度。对于超过标准长度的文本,我们将删除文本末尾的单词。对于比标准长度短的文本,我们将其填充到标准长度。在训练过程中,零将被掩盖,不参与计算。对于所有的数据集,它们的标准长度分别被设置为500和300。批量大小设置为64。
5.优化
- 优化器-Adam优化器:
- 学习率为= 0.001
- beta 1 = 0.9
- beta 2 = 0.999
- epsilon=10−8
特别是在消融术的研究中,除完全连接的隐藏层中的神经元数量外,上述实验设置均相同。当没有嵌入的类别信息时,隐藏层神经元的数量设置为256.当嵌入类别标签或类别结构时,隐藏层神经元的数量被设置为500。混合嵌入的隐层神经元数为800个。
4.3.2 评价指标
层次化的文本分类方法通常需要在每个级别上验证分类性能。我们通过两个评价指标来评估我们的方法:准确性(ACC)和总体准确性(OA),这两个指标通常用于比较层次多标签文本分类.此外,我们使用度量的训练参数数(NTP)来比较基于深度神经网络的模型训练的计算复杂度。它们如下所示。
- Overall accuracy (OA)总精确度:
当预测的父类别用于逐级分类时,总体精度指数用于评估总体分类性能。总体精度可以正式定义为 O A = ∣ C p ∣ ∣ S ∣ OA =\frac {|C^p|}{ |S|} OA=∣S∣∣Cp∣,其中 C p C^p Cp是在预先提供上层的预测的父类别时,在层次结构的最后一级被正确分类的实例集,S是所有测试实例的集合.
- Accuracy (ACC)精确度:
对于层次分类,不同层次的分类器可能具有不同的精度.当提供真正的父类别时,准确性(ACC)指数可以用于评估分类器在层次结构的每个层次上的独立性能。在层次结构的第l级的精度 A C C l ACC_l ACCl可以正式定义为 A C C l = ∣ C l t ∣ ∣ S ∣ ACC_l =\frac {|C^t_l|} {|S|} ACCl=∣S∣∣Clt∣,其中, C l t C^t_l Clt是在预先提供真正的父类别时,在层次结构的第l个(l≥1)级别上正确分类的实例集,而S是所有测试实例的集合。此外,精度指数是解决平衡分类问题的合适指标。在层次结构中,根节点通常被认为是0级。
值得注意的是,平面分类器对于索引OA和ACC具有相同的性能值,因为平面分类器不考虑层次结构。
- Number of training parameters (NTP)训练参数数量:
训练参数指标数(NTP)可用于评估模型训练的分类复杂度和计算成本。NTP是计算分类器在训练集上训练的训练参数的总数。这有一个常识:更多的训练参数通常意味着分类器将花费更多的时间进行文本分类。
总结一下,在写论文的时候,这个评价指标这块应该怎么写,我们应该结合我们自己的数据集,分析一下为什么要用这个评价指标,并且指出每个参数在我们实验中代表什么。
4.4 实验和结果分析
4.4.1统计检验和交叉验证
在机器学习任务中,常用的数据划分方法是保留验证和k倍交叉验证。对于具有大量数据的数据集,最好采用10倍交叉验证方法。相比之下,当面对具有少量或中等样本数据的数据集时,将数据分成10个相等的部分将使测试样本的数量相对小,这在一定程度上会导致模型训练的偶然性和偶然性。
在考虑实验中所涉及的数据集时,包括DBpedia, Amazon, Bestbuy, WebService, and WOS,它们都有少量或中等的样本数据。除DBpedia外,数据集中的样本数量低于50,000个,(特别是, Webservice只有10,184个样本)。如果在这些小数据集上使用10倍交叉验证方法,测试结果可能是偶然的。此外,在文本分类中使用保留交叉验证来评估模型,通常是将整个数据集分为80%的训练集和20%的测试集,这与5倍交叉验证方法获得的数据的比率相同。
因此,在本文中,我们进行了5倍交叉验证,来估计根据数据集的大小进行统计检验的指标值。当对我们的模型进行5倍交叉验证时,我们首先随机抽样数据分层,并将其分成5个相等的部分。对于每个验证,选择4个部分作为训练集,另一部分作为测试集。我们以这种方式重复模型训练5次,得到5个验证结果,最后以5个结果的平均值作为模型的最终测试结果。测试结果如图2所示,其中每个交叉验证的标准误差代表了与平均精度的差距。

在图2中,子图2(a)2(b)分别是基于三个层次的数据集DBpedia和Amazon的5倍交叉验证实验结果。其他的则有两个层次结构。实验结果表明,我们的5倍交叉验证在DBpedia、Amazon和WOS数据集上表现得非常好。不同层次的精度和总体精度在其精度值的分布上都是相对稳定的。每个交叉验证的标准误差也是稳定的,这是通过当前平均和平均精度之间的减法计算出来的。大多数的5倍交叉验证在数据集bestBuy和 Webservice集上表现得非常好,除了与数据bestBuy的其他折点相比,第五次交叉验证有一点总体变化.在WebService的第二倍交叉验证中,变化分别略高于和低于平均值。

在这里,通过计算指标值的平均值和标准差,显示了许多关于指标值的结果和分布的信息。根据这些实验结果,整个5点交叉验证的实验结果有合理的确定性。
k折交叉验证
就是把测试集和训练集合并起来,从中挑选出k个不同的验证集,然后依次在每个验证集上作实验,如果每次的实验结果都是趋于相近的水平,说明这个模型是稳定的,这个就称为k折交叉验证。

4.4.2 与平面分类器相比的准确性
在过去的几年里,一些平面分类器具有多标签文本分类的优异性能。有一些实验观察结果:并非所有的HMTC分类器都比一些平面分类器有更好的准确性。在本文中,我们的HE-HMTC方法使用混合嵌入文本表示,集成了类别结构的全局和局部图嵌入和类别标签的词语义。有必要与最先进的平面分类器进行比较,以验证我们的方法的性能。
我们首先将我们的方法与5个真实数据集中提到的4.1节中提到的最先进的平面分类器进行了比较。在这里,我们只考虑整体精度性能指数,因为平面分类器不考虑层次结构。实验结果见表4。

从表4中,我们可以发现,我们的HE-HMTC方法在所有适用的数据集上都优于所有的平面分类器。在表中,总体精度最大的实数值以粗体显示。真实的最小的整体精度使用下划线标出。不难发现,我们的方法在几乎所有的数据集DBpedia、亚马逊、百思买和WebSercice上,都有非常明显的分类性能改进。基于我们的方法的总体精度在数据集DBpedia上提高了至少1.18%(95.86%–%94.68),在亚马逊数据集上提高了19.20%(78.05%–58.85%),在BestBuy上提高了3.07%(96.36%–93.29%),在数据集网络服务上提高了9.50%(76.31%-66.81%)。另一个发现是,基于FastText的总体准确性是所有方法中最低的。其他三种方法,如BiLSTM/ Maxpool/MLP、BiLSTM/Meanpool/MLP和BERT/MLP,在总体精度方面都获得了中等的分类性能。
4.4.3 与层次分类器相比的准确性
在下面,我们将我们的HE-HMTC方法与最先进的HMTC方法HDLTex和HFT-CNN进行比较,就其分类性能而言。我们将在DBpedia, Amazon, Bestbuy, WebService, and WOS五个数据集上作实验,我们同时关注性能指标的准确性和整体准确性。我们使用总体精度指标来评估我们的HE-HMTC的整体分类性能,当预测的父类别被提供逐级分类时。另一方面,由于局部层次分类通常是以自顶向下的方式逐级进行的,因此在提供真父类别时,我们需要跟踪和验证分类器在层次结构各层次上的独立性能。实验结果如表5所示,其中 A C C i ACC_i ACCi是指在提供上一层文本的真父类别时,第i层的准确率值。OA仍然是指与预测的父类别一起提供的文本的最后一级标签的总体准确性。

从表5可以看出,一方面,在5个适当适用的数据集上,HE-HMTC方法的整体精度性能指标优于两种分层方法。与Amazon和WebService数据集相比,我们的方法有非常明显的分类性能提升,分别提高了至少17.58%(78.05% 60.47%)和10.28% (76.31% 66.03)。总体准确率也分别比其他三个数据集DBpedia、BestBuy和WOS至少提高3.76%(95.86% 92.10%)、2.42%(96.36% 93.94%)和1.93(78.51 76.58%)。结果表明,该方法具有较好的整体分类性能。
另一方面,对于精度性能指标,HEHMTC方法在所有适当适用的数据集上,与所有分层分类器HDLTex和HFT-CNN相比,具有非常有竞争力的分类精度。它在大多数级别上都优于这些数据集。这表明我们在每个层次的分类器都具有竞争力的分类性能。另一个发现是,基于HFT-CNN的总体精度在所有5个数据集的所有层次方法中都是最低的。HDLTex在精度和总体精度指标方面都具有中等的分类性能。
4.4.4 对HE-HMTC方法的消融研究
我们进行了消融研究,以检查和断言所提出的混合嵌入如何对实验结果的影响。消融实验目前已被广泛应用于研究不同“特征”的行为和影响,组成了一个复杂的深度神经网络模型和算法。消融研究通常指的是去除模型或算法的一些特征,并观察这是如何影响性能的。我们从以下四个特征中进行了实验和分析:
- GE-WE-:禁用混合嵌入,包括图形的嵌入和词的嵌入
- GE+:仅启用基于SDNE的类别结构的图嵌入
- WE+:只启用类别标签的单词嵌入
- GE+WE+:通过我们的HE-HTMC方法,实现了混合嵌入
对于每个特征/情况,我们希望观察整体精度的变化和各级精度的变化。实验结果如表6所示。

从表6中可以看出,在这四种情况下,它们在每个数据集上的第一级的准确性是相同的。此外,通过深入分析,还可以发现一些非常有趣的结果。
首先,如果我们禁用包括单词嵌入和图嵌入在内的类别嵌入(GE−WE−),那么我们所获得的精度和总体精度在5个数据集的四种情况中都是最低的。这也表明了我们的混合嵌入方法是值得探索的这也表明了我们的混合嵌入方法值得探索,同时也很有意义。
接下来,我们将分析这三个特征以进行进一步的消融研究,即GE+、WE+和GE+WE+(我们的HE-HMTC)。首先,不难发现,当GE+或WE+分别应用于对这5个数据集进行分类时,这两种方法在每个级别的分类性能和总体精度上都有显著的提高,这两种方法在每个级别的分类性能和总体精度上都有显著的提高。这显然表明,基于类别结构的图嵌入或基于标签语义的词嵌入确实有助于提高分类性能。
其次,我们比较了GE+和WE+这两个特征,并进一步验证了哪些特征更有助于提高分类性能。在几乎所有除Amazon ACC3之外的情况下,我们发现GE+WE−在提高分类准确率和整体准确性方面比GE−WE+具有更显著的优势。对于层次分类,这可能表明类别结构可能比类别标签的词语义对提高分类性能的影响更大。
第三,我们分别将我们的方法(GE+WE+)与GE+和WE+这两个特征进行了比较。在总体精度指数方面,我们的HEHMTC方法总体上比几乎所有的数据集都优于GE+和WE+。
虽然我们的方法对 BestBuy的总体准确性略低于GE+的0.1%(96.46%-96.36%),但它没有统计学意义。另一方面,值得注意的是GE+和我们的方法之间的每个级别的精度值。我们可以发现,在大多数数据集,如亚马逊、百思买、网络服务和WOS,GE+有时在某些程度上比我们的模型的准确性略高。但仔细看看,我们模型和BestBuy, WebService 和WOS之间的准确性差异分别被限制在0.03%(97.29%–97.26%)、0.4%(80.22%–79.92%)和0.38%(84.80%–84.42%),这也没有统计学意义。此外,通用电气+有时的情况精度略高于我们的方法经常发生w.r.t ACCi指的是精度值在i级时提供真正的父母类别文本的上层,也就是说,它不需要考虑错误传播从上层。
在这里,我们认为这并不意味着单词嵌入对我们的方法不是必要的或重要的。相反,如果我们注意到我们的方法在几乎所有数据集上的总体精度都高于GE+。我们知道,总体准确性指的是由预测的父类别提供的文本的最后一级标签的准确性。因此,我们相信,当我们将WE+纳入我们的方法时,WE+对提高整体分类性能非常有帮助,这可以减少分层文本分类过程中从上层开始的错误传播。深入研究发现,我们认为WE+辅助的HMTC比没有WE+特性的HMTC更有效地处理数据稀疏性问题。用于分类模型训练的训练样本数据往往会变得相对稀疏。训练次数随着层次的加深,每个类别的文本样本变得越来越小,因为每个上层的类别比层次中的下层类别少得多。简而言之,从上述分析来看,我们的HE-HMTC方法在所有五个数据集的分层文本分类性能上都非常具有竞争力。
4.4.5 分类过程的复杂性分析
下面,我们将我们的HE-HMTC方法与最先进的HMTC方法HDLTex和HFT-CNN进行了比较,关于它们的计算复杂性和成本。这些实验是在这五个数据集上进行的。我们关注的是训练参数的复杂性指数数量(NTP),而不是花费时间来执行包括学习和测试阶段在内的分类过程。NTP指数可以反映分类过程的学习和测试阶段的复杂性和计算成本。较少的训练参数通常意味着在学习和测试阶段有更少的复杂性和计算成本,反之亦然。在实验中,收集了训练参数的数量。实验结果见表7。

在表7中,我们将HE-HMTC方法与HDLTex和HFT-CNN进行了比较。考虑到HE-HMTC模型是一个逐级的局部HMTC模型,通过将每个层次分类模型的所有训练参数相加,得到参数的数量。在我们的实验中,每个层次的参数只包括参与模型训练的参数。很容易发现,HE-HMTC保持了较低的NTP值。它的NTP比HDLText要低得多,只是略高于HFT-CNN。原因可能是HDLTex为层次结构中的每个类别构建了一个分类器,因此具有非常大的训练参数。
简而言之,根据前面的实验部分,我们可以得出结论,我们的方法比最先进的平面和层次化方法具有优越的分类精度,特别是在保持较低的计算成本的同时,实现了优越的文本分类性能。
4.4.6 分类性能的综合统计分析
在本节中,我们希望对所有最先进的平面和层次化方法进行全面的统计分析,包括我们的HE-HMTC方法。赫尔林格-TOPSIS(H-TOPSIS)模型被提出用于排名算法并通过应用海林格-距离和TOPSIS来支持最佳算法的选择,它已被用于多视角文本分类的实证评价.在本文中,我们将使用H-TOPSIS模型对所有最先进的方法和我自己的模型方法进行全面的统计分析。我们首先对海林格距离和H-TOPSIS作出简要的解释如下:
设f和g为两个概率密度函数(FDF)。f和g之间的海灵格距离 D H ( f , g ) D_H(f,g) DH(f,g)由Eq给出。

设f1和f2分别为两个正态分布 N ( μ 1 , σ 1 2 ) N(μ_1,σ^2_1) N(μ1,σ12)和 N ( μ 2 , σ 2 2 ) N(μ_2,σ^2_2) N(μ2,σ22)上的两个PDFs,用f1进一步计算f1和f2之间的Hellinger距离 D H ( f 1 , f 2 ) D_H(f_1,f_2) DH(f1,f2)

其中, μ 1 μ_1 μ1和 μ 2 μ_2 μ2为平均值, σ 1 σ_1 σ1和 σ 2 σ_2 σ2为标准差。使用海林格距离来比较算法性能的H-TOPSIS可以在以下步骤中进行描述。
Step1:计算每个标准的positive ideal solutions ( P I S ) f + (PIS)f ^+ (PIS)f+和negative ideal solutions ( N I S ) f − (NIS)f^− (NIS)f−。在本文中,我们主要关注分类算法的准确性。一个精度越高的算法就越好。假设我们有n个算法,每个算法都有m个准则。设 μ i j μ_{ij} μij表示第i个算法的第j个准则的平均值,因此每个准则的PIS和NIS都可以用Eq来总结.

式中,i∈{0、1、2、…,n}、j∈{0、1、2、…,m}、n和m分别为算法/方法和评价准则的数量。
step2:分别计算每个算法的PIS(+)和NIS(−)的分离度量 d i + di^+ di+和 d i − di^− di−,如下式所示。

step3:通过等式计算每个算法相对于positive ideal solution的相对接近系数ξi.

**Step 4:**根据相对接近系数ξi对备选方案进行排序.最好的算法是那些ξi值较高的算法,因此应该选择它们,因为它们更接近正的理想解。
具体来说,我们分别做了两种排名。第一种就是将所有的平面分类器与我们的分类程序一起排序。另一种是关于所有的HMTC方法。在本文中,对于第一种排名,我们以总体精度(OA)和每个第i级的精度(ACCi)作为所有最先进的HMTC方法的标准。为了满足各算法统计变量的一致性,我们使用ACC1、ACC2和OA三个标准来评估算法,因为其中有些数据集只有类别标签的两级层次。首先,我们提取了HDLTex、HFT-CNN和HE-HMTC三种算法中关于ACC1、ACC2和OA的信息。分别在5个不同的数据集上计算各算法精度的平均μ和标准差σ,如表8所示。
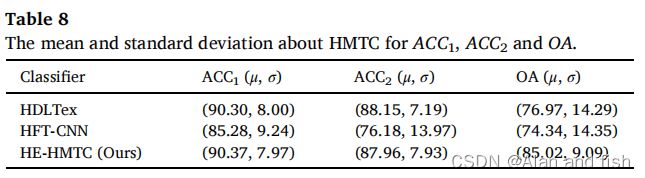
然后,我们从表8中提取每个准则的PIS和NIS值,从而得到表9。

然后,我们从值 P I S f + PISf^+ PISf+和 N I S f − NISf^- NISf−通过方程计算分离度量 d i + d^+_i di+和 d i − d^−_i di−。然后,我们将通过Eq得到每个算法的相对接近系数ξi.关于算法排序的最终排序结果如表10所示。

对于第二类排序,由于平面文本分类算法只有总体精度,所以我们只以总体精度作为对我们的HE-HTMC算法和所有平面算法进行排序的标准。与第一种排名类似的操作可以获得相关的表信息,如表11-13所示。

从表10和表13中我们可以发现,我们的HE-HMTC方法在所有层次和平面分类器中具有最高的相对接近系数排名,这总体上表明我们的方法比这些适用的数据集具有优越的分类性能。在平面分类器中,FastText被排在最后位置。
此外,考虑到表7,我们可以得出结论,与最先进的局部和分层文本分类方法相比,我们的HEHMTC方法具有优越的分类精度,特别是保持了较低的计算成本,同时实现了优越的性能。
5.结论
本文提出了一种基于嵌入的HMTC混合文本表示方法。我们的HE-HMTC方法充分利用了类别的结构及其标签的语义来丰富文本的表示,从而试图提高文本的分类性能。本文的新贡献是给出了一种基于嵌入的混合文本表示,该表示将基于BiGRU的文本表示与基于类别结构的图嵌入和基于类别标签的词嵌入相结合。我们做了广泛的实验,在5个适当适用的数据集上验证了我们的HEHMTC方法的性能。在相关的精度分析方面,我们发现我们的HE-HMTC方法在几乎所有适用的数据集上对所有的平面和层次分类器具有非常强的竞争力。消融实验从四个角度进行,通过它,我们发现我们的HE-HMTC方法通常可以在几乎所有具有最深层次的数据集上获得最高的总体精度。通过对所有最先进的平面和层次分类器进行基于H-TOPSIS的综合分析,我们的HE-HMTC方法在5个真实字数据集上排名最高。
我们必须注意到,关于HMTC的改进及其性能验证的问题仍然是一个有待解决的问题。在未来的工作,我们将探讨HMTC如何有效地应用于特定领域的文本分类任务,如基于文本的情绪分析、web服务发现。另一方面,我们认为,如果加入更多的验证方法,最好采取新的见解来研究HMTC的改进。
在未来的工作中,我们希望利用我们的HE-HMTC方法,将其应用于电力文本多标签分类,以进行故障类型识别和决策。此外,我们还将探讨如何有效地学习用于文本分类的语义丰富的类别标签嵌入。