DDD学习笔记——聚合的技巧2
DDD学习笔记——聚合的技巧2
一个模型,两种实现
最近,在重读《领域驱动设计》。在其中读到这样一段话 ”一对多关联可以用一个集合类型的实例来实现,也可以用一个访问方法来查找记录,并使用记录来实例化对象。这两种方法反映了同一个模型“。那么,这两种方法到底孰优孰劣,他们的差别在哪里?又该如何选择呢?下面我们用一个虚构的项目来尝试一下这两种不同的方法,看看实际的情况到底如何。
购物车和订单
有这样一家”商贸公司“,它为每个客户提供了”购物车“,允许”客户“将希望采购的商品加入”购物车“中。并从”购物车“创建”订单“,一遍一次性对所有要采购的”商品“进行支付。
基于如此简单的需求,我们可以得到一个简单的领域模型:
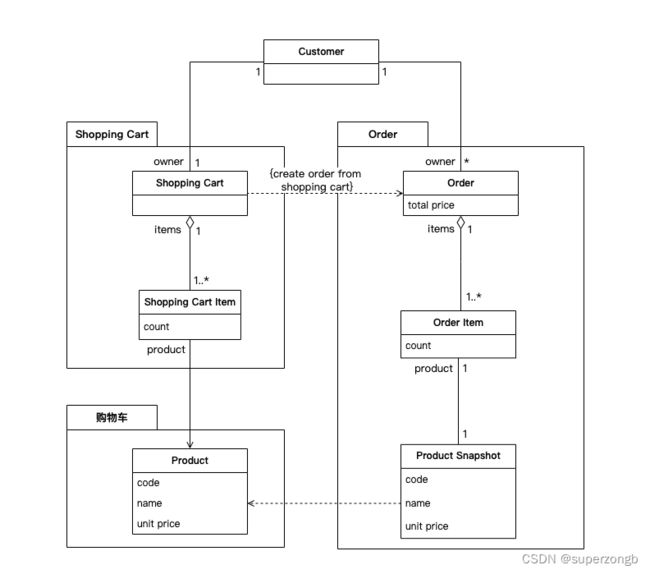
- “Shopping Cart” 包含了众多的 “Shopping Cart Item”,每个“Shopping Cart Item”描述了某种 “Product” 在购物车中的数量。
- “Shopping Cart Item“ 持有 ”Product“ 的引用,”Product“ 本身会随着市场原因产生价格变化。
- ”Customer“ 可以从 “Shopping Cart” 创建 “Order”,“Order”包含了“Oder Item”,“Order Item” 持有在订单创建这个时刻产品的快照 “Product Snapshot”。这样,订单中的商品将不会随着市场而变化。
设计
将领域模型实现为代码的过中,我们会产出设计模型。下面我们分别用两种方式来实现我们的领域模型。
实现1: 集合类型的实例
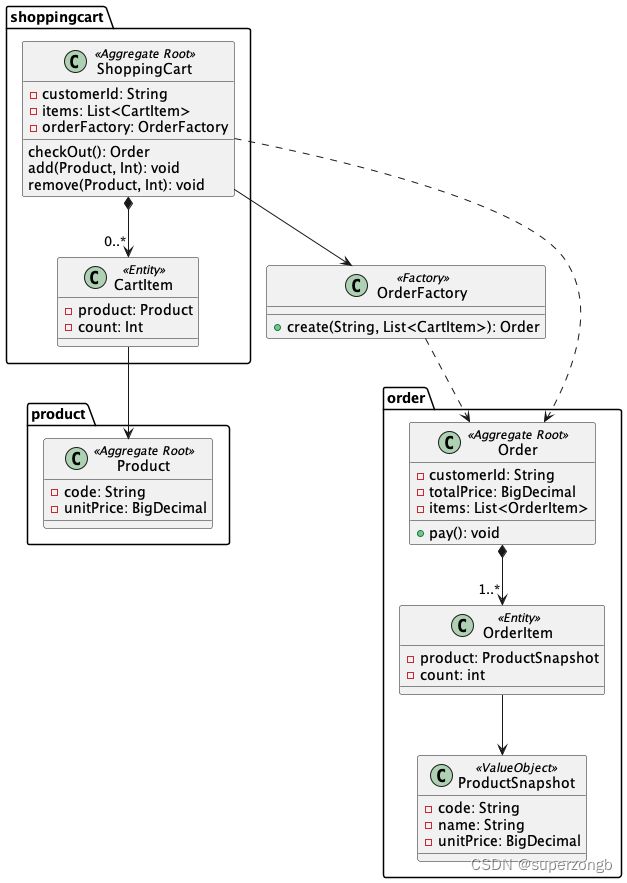
使用集合对象来实现聚合根和实体之间的聚合关系,我们很容易得到上面的设计模型。在 “ShoppingCart” 和 “Order” 中都包含有一个叫做 “items” 的List属性,来实现对Entity的聚合。根据我们一般对Aggregate的认知,Aggregate 必须是一个事务边界,并被视为一个整体(原子性的–作为一个整体加载,作为一个整体保存)。然而,由于受到技术本身(CPU,内存,网络等)的客观约束,使得此模型的处理能力受到了限制,客户一次能够购买的商品种类被限制在了一个较少的数量上。
代理集合
随着业务的发展,贸易公司的生意越做越大,一些“超级客户”需要一次性采购数十万种商品。上面采用集合类型的实现方式,显然无法实现这样的需求。一次性将这么多的对象加载到内存中,我们似乎需要一台特别的计算机。好在 Eric Evans 在 Domain-Driven Design Reference 中对 Repository有这样的描述:
Return fully instantiated objects or collections of objects whose attribute values meet the criteria, thereby encapsulating the actual storage and query technology, or return proxies that give the illusion of fully instantiated aggregates in a lazy way.
返回一个Proxy,在领域层给我们一个假象,使得业务可以感知到的聚合是一个完整的整体,而实际上聚合内的实体则是按需加载到内存中的。
package ...adapter.outbound.presistence.shoppingcart;
public class CartItemListProxy implements MethodInterceptor {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
if (method.getName().equals("get")) {
int index = (int) objects[0];
if (index >= (from + size)) {
from = from + size;
List<CartItemPO> items = itemMapper.getBatchCartItem(cartId, from, size);
inMemoryCache = items.stream().map(convert::toDomain).collect(Collectors.toList());
} else if (index < from) {
from = from - size;
List<CartItemPO> items = itemMapper.getBatchCartItem(cartId, from, size);
inMemoryCache = items.stream().map(convert::toDomain).collect(Collectors.toList());
}
index = index % size;
return inMemoryCache.get(index);
} else if (...) {
...
}
}
}
这样,我们可以通过使用动态代理的方式,分批将数据读入内存。如下,在Domain Layer是感知不到分批读入这样的操作的。
package ...domain.context.shoppingcart;
public class ShoppingCart implements AggregateRoot {
....
public Order checkOut() {
...
//this.items 的类型是List, 但实际上是上面实现的动态代理。
//数据并未被直接加载到内存中,而是分批从数据库读取的。
//但对于OrderFactory来说,并不会感知到这些。操作的仍然是整个聚合。
Order order = orderFactory.create(this.getCustomerId(), this.items);
...
return order;
}
但是,这样的实现方式仍然存在问题。当聚合被修改后,我们需要将变更写⼊数据库。这时再使⽤代理似乎不是⼀个好的选择。因为从领域层,我们将看不到显示的写数据库操作,从⽽导致对聚合的⽣命周期失去控制。例如上面的例子中,ShoppingCart聚合的item需要被删除,也是分批的删除么?Order聚合中增加的OrderItem是否也是分批的写入数据库呢?这些变更,我们都希望在Domain Layer可以显式的被表达出来。
实现2: 访问方法
使用访问方法来表达聚合内的关联关系,我们需要首先明确如何表达。这时我们需要回头来再进一步的挖掘业务逻辑。
面对“超级客户”的大宗采购,我们发现订单的生成过程不会是瞬间完成的。为了生成订单,我们需要核对商品数量,库存数量等等,这个过程需要持续一段时间。所以客户不能在界⾯上立即看到⽀付⽤的订单,需要经过⼀段时间后才能看到最终的订单。在这个过程中,只能在界⾯上看到:“订单正在⽣成中…”。
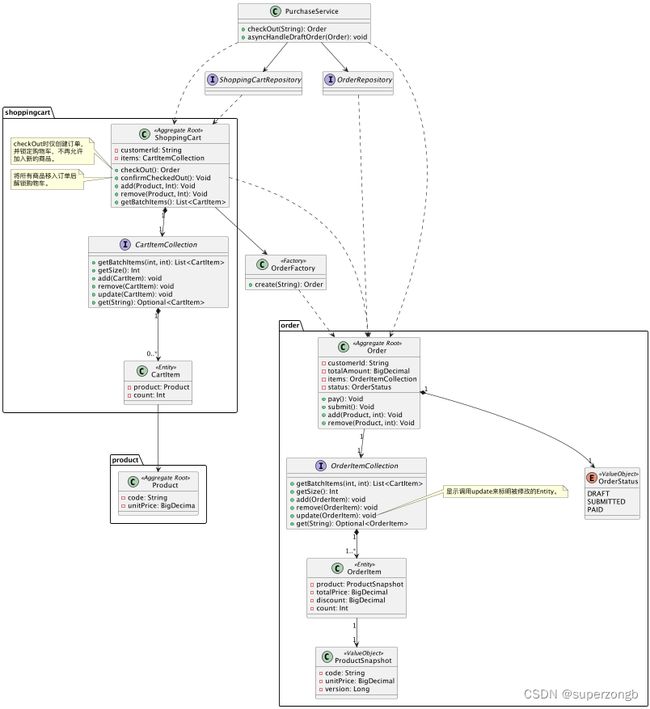
PurchaseService
在Draft状态的Order被创建后,⼀批⼀批的将“商品”从购物⻋移动到订单中。这样的操作更符合现实的情况,对客
户来说,只是点击⼀次CheckOut按钮,但后台实际上需要多次操作,但这些操作是不需要客户介⼊的。
ShoppingCart
\1. checkOut 时锁定购物⻋,不再允许加⼊新的商品。并创建⼀个DRAFT状态的Order。
\2. confirmCheckOut确认所有的商品已经移动到了订单中,解除购物⻋的锁定状态。
Order
刚被创建时状态为Draft,对客户不可⻅,允许多次向订单内添加商品。提交后状态为Subimtted,此时⽤户可⻅,
但商品,价格等不可再修改。
CartItemCollection & OrderItemCollection
对聚合内的实体“组织”形态进⾏抽象,本身蕴含了业务逻辑,同时可以在Infrastructure Layer使⽤基础设施实现业
务逻辑。其中update⽅法有暴露底层实现的嫌疑,但显式的更新有助于降低实现成本。(使⽤动态代理的⽅式可以
⾃动的识别出修改,但成本过⾼)
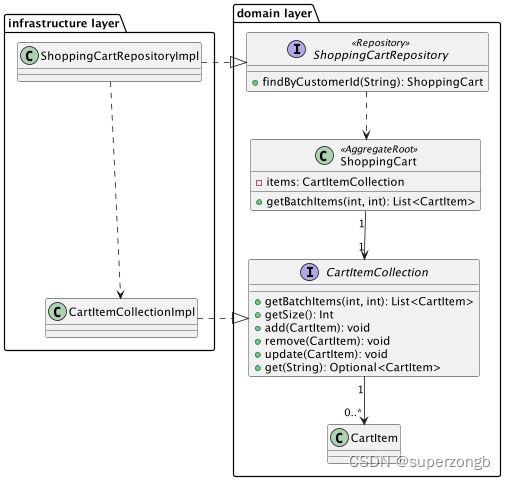
PurchaseService的两个⽅法会在Application Layer背分别调⽤,基于不同的业务考虑使⽤异步线程,或外部定时
器调⽤异步订单处理⽅法。
public class PurchaseService implements Service {
public Order checkOut(String customerID) {
ShoppingCart cart = shoppingCartRepository.findByCustomerID(customerID)
.orElseThrow(RuntimeException::new);
Order order = cart.checkOut();
orderRepository.save(order);
shoppingCartRepository.save(cart);
return order;
}
public void asyncHandleDraftOrder(Order order) {
ShoppingCart cart = shoppingCartRepository.findByCustomerID(order.getCustomerID())
.orElseThrow(RuntimeException::new);
if (cart.getSize() > 0) {
List<CartItem> items = cart.getBatchItems(0, 100);
items.forEach(item -> {
order.add(item.getProduct(), item.getCount());
cart.remove(item.getProduct(), item.getCount());
});
} else {
order.submit();
cart.confirmCheckedOut();
}
orderRepository.save(order);
shoppingCartRepository.save(cart);
}
}
同时,对于“Order”聚合,我们需要注意到订单的总价和订单项有关系,但其具体的规则实际上可以有两种表述:
价格需要满⾜,所有商品单价乘以数量的总和
或者,当前价格+商品单价*新增数量的总和以上的两种规则本质上是不⼀样的,在建模时应该在模型中显示的表达出来。这两种规则映射着不同的实现,也带
来了截然不同的业务表现。规则****1要求⼀次性的计算出总价来,这意味着需要⼀次性遍历所以的待⽀付的订单项。
收到客观资源的限制(时间,CPU,内存),订单项的总数就不可能太多。
class Order{
private OrderItemCollection items;
private BigDecimal totalAmount;
public void add(Product product, int count) {
OrderItem item = items.get(product.getCode())
.orElseGet(() -> {
OrderItem newItem = OrderItem.builder()
.productCode(toSnapshot(product))
.build();
items.add(newItem);
return newItem;
});
item.increase(count);
items.update(item);
//item.increase已经返回了增加的⾦额,下⾯的写法只是为了更明确的表达⾦额增加的逻辑
this.totalAmount = this.totalAmount.add(product.getPrice().multiply(BigDecimal.valueOf(count)));
}
}
多说几句
从上面的例子中,我们发现。具体选择何种实现,还需要回到对业务的深入理解上面来。根据具体的业务需要选择更合适的实现方式。
对于大聚合,有时候我们会考虑聚合划分的是否合理,是否可以再进一步划分成更小的聚合。但就我个人的想法,划分聚合仍需要贴合业务本身,不可因为技术实现而扭曲了业务本身。例如上面的例子中,在创建“Order”的过程中,我们是否可以引入“批次”这样一个概念来解决聚合过大的问题呢?我个人是不太愿意,虽然“批次”确实存在,但这个概念本身在业务上就是一个隐式的概念。本身在业务上没有需要被记录或追溯的需求。那么我也不太需要显式的建模出来,而通过“方法”来隐式表达这样一个概念,更能反映业务原本的模样。