An Image is Worth 16×16 Words:Transformers for Image Recognition at Scale(ViT,ICLR2021)
ViT
- 摘要
- 引言
- 相关工作
- 方法
- 实验
- 结论

摘要
虽然Transformer架构已经成为自然语言处理任务的标准,但它在计算机视觉方面的应用仍然有限。在视觉领域,注意力机制要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,但其整体结构并没有改变。本文表明,这种对CNN的依赖是不必要的,直接应用于图像块序列的纯Transformer架构可以很好地执行图像分类任务。利用大规模数据集进行预训练,再迁移到中小型数据集上使用(ImageNet、CIFAR-100、VTAB等),Vision Transformer能获得与最先进的卷积网络相媲美的优异结果,而且训练所需的计算资源要少得多(这里的少指的是在TPUv3上只需训练2500天,非常人所能企及)。
引言
基于自注意力的架构,特别是Transformer,已成为自然语言处理(NLP)的首选模型。主要方法是在大型文本语料库上进行预训练,然后在较小的特定于任务的数据集上进行微调。由于Transformer的计算高效性和可扩展性,目前已经能够训练超过1000亿参数的模型。随着模型和数据集的增长,仍然没有看到性能饱和的迹象(很多时候,不是一味地扩大数据集或者扩大模型就能获得更好的效果。尤其是在扩大模型的时候,很容易出现过拟合问题。对于Transformer来说,目前还没有观测到这个瓶颈)。
在计算机视觉领域,卷积结构仍然占主导地位。受Transformer在NLP领域成功的启发,一些工作提出将CNN与自注意力混合使用(使用CNN提取到的特征图作为自注意力的输入),还有一些工作提出用自注意力把整个CNN结构替换掉(孤立自注意力:用整张图作为自注意力输入的话复杂度太高,孤立自注意力采用局部小窗口的方式来控制复杂度,有点类似于卷积网络中的滑动窗口;轴自注意力:把2d矩阵拆分成两个1d的向量,先在高度这个维度上做一个自注意力,再在宽度这个维度上做一个自注意力,大幅降低了计算复杂度)。孤立自注意力、轴自注意力等这类基于全注意力机制的模型虽然在理论上很高效,但事实上这些自注意力都是比较特殊的自注意力机制,没有在现在的硬件上做加速,就会导致很难去训练一个大模型。在大规模图像识别任务上,经典的ResNet结构仍然是最好的。
受Transformer在NLP领域可扩展性的启发,本文作者想利用一个标准的Transformer直接作用于图像,尽量做少的修改(就是不做任何针对视觉任务的特定改变)。为了实现这一目标,作者把一张图片划分成多个大小一样的patch(每一个patch的大小都是16×16,假如说一张图片的大小为224×224,经过划分之后,高度和宽度都变成了224/16=14,因此得到的序列长度就是14×14=196),并将这些patch送入一个FC层进行线性映射,得到一个linear embedding,而后作为Transformer的输入。对patch的处理方式与在NLP中处理单词的方式是一样的。作者用有监督的方式对该模型进行图像分类训练(在NLP领域,Transformer大多用无监督的方式进行训练)。
当在中型数据集(如ImageNet)上进行训练时,如果没有加比较强的正则化约束,ViT跟同等大小的残差网络相比,精度会低几个点。这个看起来不太好的结果其实是可以预期的,因为跟卷积神经网络相比,Transformer缺少一些CNN有的归纳偏置(归纳偏置指的就是一些先验知识或者提前做好的假设)。在CNN中,就有两个常说的归纳偏置,一个是locality(局部性),因为卷积网络是以滑动窗口这种形式在图片上进行卷积的,所以它假设图片上相邻的区域会有相邻的特征,这个假设很合理,靠的越近的东西相关性越强;另外一个是translation equivariance(平移等变性),即f(g(x))=g(f(x)),把f看作卷积,g看作平移,意思是无论先做卷积再做平移,还是先做平移再做卷积,其结果都是一样的。因为在CNN中,卷积核就相当于一个template,无论在图片上移到哪里,只要是同样的输入进来,输出永远都是不变的。CNN有了这两个归纳偏置,其实就有了很多先验信息,因此可以使用相对少的数据去学一个较好的模型。而对于Transformer来说,它没有这些先验信息,它对于视觉世界的感知全部需要从大量数据中去学。
为了验证归纳偏置这种说法的正确性,作者在更大的数据集上做了预训练(ImageNet-21k数据集,包含1400万张图像;JFT-300M数据集,包含3亿张图像),结果变得更好,发现大规模预训练比归纳偏置要好。ViT只要在足够多的数据上进行预训练,就能在下游任务上获得很好的迁移学习效果。具体而言,ViT在ImageNet-21k或JFT-300M数据集上进行预训练,就能在图像识别任务上获得跟现在最好的残差网络相近或者更好的结果。
相关工作
基于Transformer的模型通常先在大型语料库上进行预训练,然后针对下游特定任务进行微调。其中有两个比较出名的工作,一个是BERT,用了denoising self-supervised的预训练方式;另一个是GPT,用了language modeling做自监督。
将Transformer应用到视觉领域中,最简单的方式就是把每一个像素点当成是一个元素,让它们两两做自注意力就好,但是这个复杂度是平方,很难应用到真实图片上。针对这一问题,有的工作用小窗口做自注意力,有的工作用稀疏的方法只对一些点做自注意力,还有的工作将自注意力用到不同大小的block上。这些特殊的自注意力在计算机视觉任务上表现都不错,但需要用很复杂的工程去加速算子。
与本文最相似的一篇工作提出于2020年,该工作将图像划分成许多个大小为2×2的patch(该工作只在CIFAR-10上做了实验)。与之不同的是,本文证明了在大规模数据集上进行预训练,能够使得Transformer展现出比最好的卷积神经网络还要好的性能。再一个,本文所提模型可以在高分辨率图像上做训练。
方法

模型的整体结构如上图所示。先将图像划分成许多个16×16大小的patch,假设图像大小为224×224×3,那么一共可以划分 22 4 2 / 1 6 2 = 196 224^2/16^2=196 2242/162=196个patch,每个patch的大小为16×16×3,有768维。每个patch展平后经过一个线性投射层(全连接层,有768×768维,前面这个768是patch的维度,后面这个768是设定的序列长度)得到一个D维(D=768)的特征向量(patch embedding),并给每个patch embedding加上一个位置编码(position embedding),patch embedding和position embedding是通过相加融合的,因此这个整体的token既包含了这个图像块原本有的图像信息,又包含了这个图像块所在位置信息。
196×768的矩阵与线性投射层(768×768)相乘,得到的还是196×768的矩阵,即表示196个768维度的patch embedding。196个patch中,每个patch都有一个768维的位置编码序列(position embedding),将其与patch embedding相加得到196个768维的token。此外,还有一个维度为768的extra learnable embedding,同样会加上一个位置编码,得到class token,这个class token跟其他196个token拼接在一起,最终得到197个768维的token。
模型借鉴了BERT的class token(extra learnable embedding),因为其他所有token都在两两做信息交互,所以作者相信这个class token能够从别的token里学到有用的信息,从而只需要根据它的输出做一个最后的判断即可。MLP Head就是一个通用的分类头,用交叉熵损失进行模型的训练(在预训练时使用含有一个隐藏层的MLP作为分类头,在微调时使用一个单线性层实现分类)。
Transformer Encoder这块的输入就是一个197×768的tensor,这个tensor会先经过一个Norm层,出来后还是197×768。而后进行多头自注意力操作,如果是单头自注意力,一分为三(k、q、v),每一个都是197×768。因为这里是多头自注意力,所以维度并不是768,假设在这里ViT用了12个头,那么一个头的维度就是768/12=64,即在一个头中,k、q、v都是197×64。最终将12个头的输出进行拼接,得到的依然是197×768。再经过一个Norm层,得到的还是197×768。而后再经过一个MLP,经过MLP的时候会把维度相应放大,一般放大4倍,即768×4=3072维,tensor就是197×3072,再经过一个线性投射层将维度映射回768维,最终输出的就是197×768。至此,一个Transformer Block的前向过程就走完了,输入为197×768,输出也是197×768。叠加L个Transformer Block就构成了Transformer Encoder。
在CNN中,locality(局部性)、two-dimensional neighborhood structure(二维窗口结构)、translation equivariance(平移等变性)几乎用于整个模型的每一层。相比于CNN,ViT具有少得多的归纳偏置,只有MLP中具有locality(局部性)和translation equivariance(平移等变性),而自注意力是全局的。在ViT模型之初将图像分割成块,以及在微调时调整不同分辨率图像的position embedding时,会涉及到two-dimensional neighborhood structure,其他时候关于patch的2d信息,patch之间所有的空间关系都需要从头开始学。
①将图像划分成196个patch,随后进行线性投射;②将图像送入CNN,提取到14×14的特征图,而后进行线性投射。这两种方式可以看作是不同的图像预处理操作,预处理之后的步骤是完全一样的。
之前有工作提到过,用比预训练具有更高分辨率的图像对特定任务进行微调,能得到更好的结果。然而对于Transformer来说,如果在微调时使用更高分辨率的图像,势必会导致更长的序列维度,那在预训练中已经训练好的position embedding就失去了意义。针对这一情况,作者提出使用简单的2d插值就可以解决,但如果分辨率相差太大,简单的2d插值可能会让结果掉点,因此2d插值只是一个临时方案。
实验
对于Class Token,作者做了消融实验。为了尽可能使用NLP中的Transformer结构,同样加上了这个class token,其作用就是作为整体的图像特征输出。得到class token的输出后,再接一个MLP,这个MLP中只有一个隐藏层(全连接层),并使用tanh作为非线性激活函数。
class token这个设计完全借鉴于NLP中的Transformer,在以往的视觉领域中,经过卷积神经网络提取到的最终特征图(假设大小为14×14),会做一个GAP(全局平均池化)操作,拉直之后就是一个向量,这个向量就可以理解成整体的图像特征,而后用这个向量去做分类。
对于Transformer来说,196×768(不包含class token)的输入,输出也为196×768,直接对这些输出做一个GAP是否可行呢?答案是可行的。也就是说使用class token和使用GAP这两种方式都是可以的,ViT所有实验都用了class token,主要是为了跟原始的Transformer保持一致。
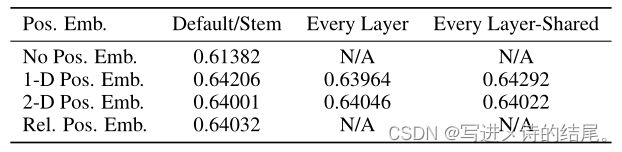
对于位置编码,作者也做了消融实验。分别使用no positional information、1d positional embedding、2d positional embedding和relative positional embedding四种情况进行实验,结果如下表所示。有位置编码的情况要比没有位置编码更好,位置编码的实现方式对于结果的影响不大,效果都差不多。作者推测之所以会出现这种情况,是因为Transformer Encoder的输入为patch级别,而不是像素级别,patch级别的输入维度要比像素级别的小得多,而且学习表示该分辨率中的空间关系也比较容易,因此如何编码空间信息的差异就不那么重要了。
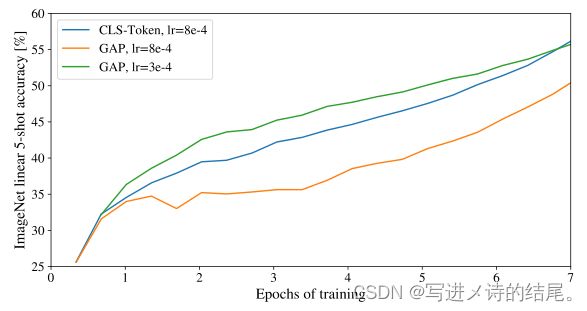
本文评估了ResNet、ViT和混合模型的表征学习能力,为了了解每个模型的数据需求,对不同大小的数据集进行了预训练。当考虑预训练的计算代价(即训练时间)时,ViT表现的非常好。
ViT有如下几种变体,当分割成的patch的尺寸更小时,模型的计算代价会更大,因为序列长度增加了。

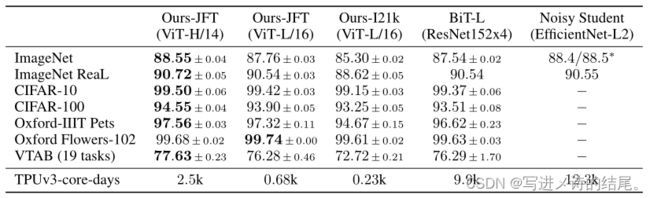
ViT模型与主流分类基准的性能对比如下:
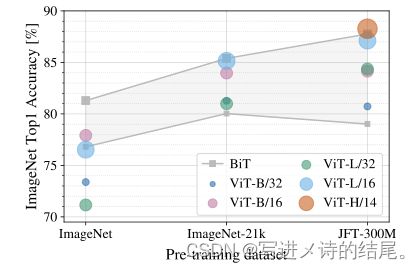
ViT在中小型数据集上做预训练时得到的结果远不如CNN(ResNet-152),因为没有用那些先验知识,没有用那些归纳偏置,因此ViT需要更大规模的数据去让网络学的更好。随着预训练的数据量增加,ViT的效果也是越来越好。如果想在数据集上进行预训练,而数据集又比ImageNet-21k小,那选择CNN得到的结果会更好;如果数据集比ImageNet-21k还要大,那可以使用ViT获得更好的结果。
ViT为了与ResNet进行比较,加了一些强约束,比如dropout、weight decay、label smoothing,因此不太好分析ViT本身的一些特性。因而作者拿到预训练模型后,直接把它当一个特征提取器,以进行消融实验。预训练的数据量不够时,ViT完全比不过ResNet,随着数据量的增加,ViT的性能也是越来越好。
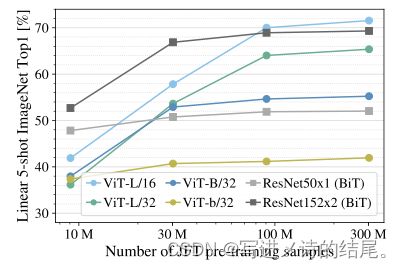
从下面的图中可以看到,在相同的计算代价下,ViT基本要比ResNet表现更好,即证明了ViT的计算代价比CNN小。另外,当模型规模较小时,混合模型比ViT和ResNet都要好;但当模型规模变大后,ViT逐渐占据上风。

下图左展示了线性投射层是如何embed RGB value的,其实ViT学到的跟CNN也很像,都带有一些颜色、纹理等,因此作者认为这些成分可以作为描述图像块底层结构的基函数。下图中通过相似性计算显示了position embedding的工作,可以看到每个patch的位置编码与自己的相似性是最高的,与周围的相似性也相对较高,离得越远相似性越低,表明它确实学到了距离这个概念;同时还能看到它也学到了行和列的规则,同一行同一列表现出了更高的相似性,也就意味着它虽然是一个一维的位置编码,但它已经学到了二维图像的距离的概念,这也可以解释为何2d的位置编码并没有比1d的效果更好,因为1d的位置编码已经够用了。下图右展示了自注意力的作用,刚开始时有的自注意力头只能看到附近的东西,有的自注意力头能看到很远的东西,这就说明自注意力在网络刚开始的时候就已经能注意到全局上的信息了,而不像CNN刚开始的时候感受野非常小,只能看到附近的一些pixels。随着网络越来越深,模型学到的特征也越来越高水平,即具有更多的语义信息。到了网络后半部分,自注意力的距离都非常远了,即都能看到很远的东西,也就意味着它已经学到了带有语义性的概念,而不是靠临近的像素点去进行判断。

结论
本文探索了Transformer在图像识别中的应用(使用NLP领域中的Transformer来处理计算机视觉问题)。与以往的在计算机视觉领域中用到的自注意力工作不同,除了最初的获取patch步骤以及位置编码用了一些图像的归纳偏置外,没有再引入任何特定于图像的归纳偏置(这么做的好处就是不需要对Vision领域有什么了解,可以直接把图片理解成为一个序列的图像块,就像一个句子有很多个单词一样,然后就能够利用NLP里面标准的Transformer来做图像分类了)。