< 每日闲谈:你真的了解 “ ChatGPT ” 嘛 ? >

< 每日闲谈:你真的了解 “ ChatGPT ” 嘛 ? >
- 前言
- OpenAI的创立
- ChatGPT有何过人之处?
-
- > 效果演示
- OpenAI看家之作 — GPT自然语言模型
-
- > GPT发展史
- > 里程碑-GPT3
- > 从数据到AI — ChatGPT模型训练之路
-
- 1.学习文字接龙
- 2.人类老师引导文字接龙方向
- 3.模仿人类制定的偏好,训练老师模型
- 4.用增强式学习向模型老师学习
- > 特性总结
- ChatGPT国内用户注册方法
- 参考文献
- 往期内容
前言
相信小伙伴们最近肯定没有少从互联网上听到关于 ChatGPT 的信息,最近越来越多和 **ChatGPT ** 相关的 Ai 人工智能内容的工具被宣传出来。也越来越多行业直接或者间接受到 “Ai” 的影响,衍生出了相关的新兴职位,例如: Ai插画师、AI提词工程师、Ai艺术画师等等。所以,清楚的了解认识它,非常有必要!
随着 “ ChatGPT ” 越来越火,即使是在国内,除了技术爱好者和相关从业人士,甚至在很多娱乐新闻上都能看到它的身影。前阵子还上了抖音的热榜,这对于一个技术产品来讲的确是非常难得,非常出圈的一件事。
So, it is 何方神圣? 接下来,就由小温带小伙伴们来认识一下它!
OpenAI的创立
OpenAI 是现在世界上最顶级的人工智能实验室之一,其创始人之一正是鼎鼎有名的明星企业家马斯克。马斯克一直是AI威胁论的支持者,他认为在未来AI会威胁到人类社会,但他觉得避免AI潜在威胁的最好方式并不是去限制它,而是透明化地研究它,开放他,普及他,避免巨头垄断。
2015年底马斯克作为创始人之一的身份和硅谷大佬共同创建了明星企业 OpenAI 。起初OpenAI的定位是一家非盈利专注于人工智能研究的实验室,但是现在也有商业化的部分。其使命是通过研发一种高度自主且在大多数具有经济价值的工作上超越人类的系统。
OpenAI注重在AI领域的理论研究,公司成立以来发表了很多显著的研究成果,与其他巨头相比,OpenAI更注重开源分享,因此每年都会发布一些有影响力的开源作品或平台,使得OpenAI每次发布开源作品时,都会受到业内人士的广泛关注。
ChatGPT有何过人之处?
于 2022.12 OpenAI 推出了他们的最新之作 ChatGPT,一经推出就获得大量关注,据官方统计ChatGPT推出一周的时间,线上体验用户已超过一百万,那他到底有何神奇之处,能引起如此大的关注呢?
强烈建议大家自己去官网体验一下,不过需要先注册,但ChatGPT对国内用户非常不友好,可以说是能封住的地方都封住了(估计是和国家间政策处理有关),所以注册一个ChatGPT账号对国内用户来讲也是一件成本很高的事。我总结了一下注册账号的教程,放在末尾章节,有需要的可以根据它去尝试注册。
这里有我体验的一些示例,效果确实很惊艳。
> 效果演示
- 严谨知识类: 知识类的问题,对于来ChatGPT说是小菜一碟,每次对话都非常好的保留上下文的语义环境,让沟通很顺畅。
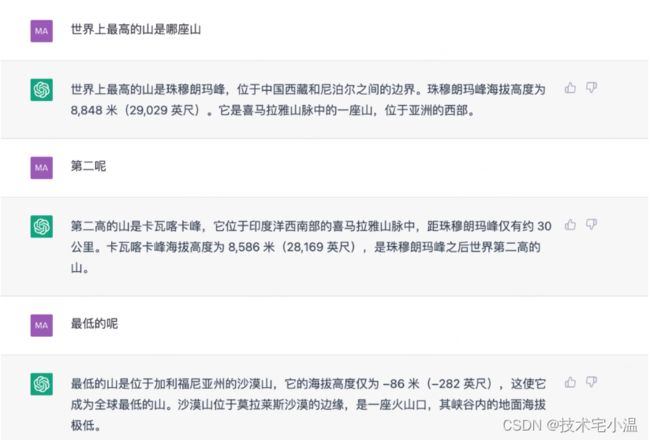
- 开放性知识类: 回答准确,解答详细,贴近人类生活,会给出靠谱的建议。


- 世纪难题,无合适答案类: 对于这种无理的问题,ChatGPT显得有点滑头,虽然它给出了看起来说的过去的答案,但显得太过官方,无论问它多少遍它的答案都不会是妈妈或者是妻子,更不会从法律等一些客观角度给出结论,因为无论如何选择,答案都是反人性的,ChatGPT不会给出引发争论的、有毒的、坏的答案,从中也能看出它并不是
野蛮生长,而是有着这人类干预和调教的过程,如果你一再逼问,它最终会拒绝回答。


- 更感性更具有人类情感的问题: 即使是人类中很感性的问题,ChatGPT一般也能给出比较合理的答案,而由于人类的干预和调教,它的价值观会更加注重让你尊重对方,而不是为你得坏心思提供方法,ChatGPT并不缺少方法,很多问题往往需要换一个问法它才能给出让人满意的答案。



- 创作能力: 根据简单的故事情节要求,创作了小芳和小明的爱情故事,几乎能让人无法分辨是机器还是人的创作,非常有意思。

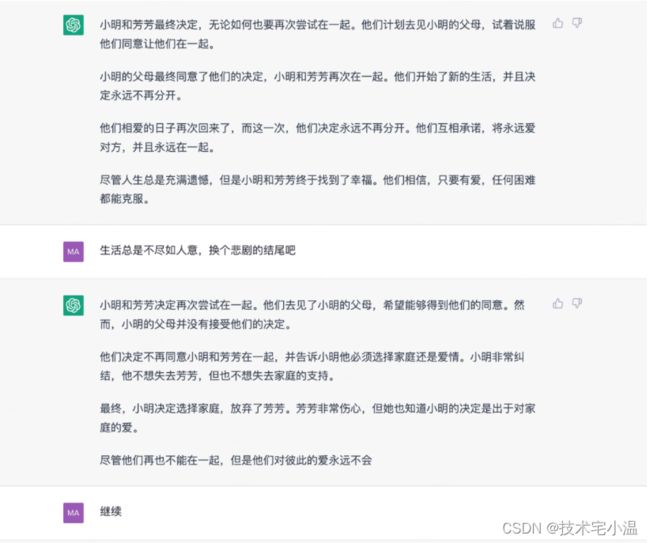
- 代码编写能力: 按要求代码编写,动态输入指令,代码纠错,编码能力合格。

OpenAI看家之作 — GPT自然语言模型

美国人工智能研究实验室 OpenAI 于 2023.04.04 为其热门聊天机器人 ChatGPT 发布了最新的 GPT-4 语言模型,距 ChatGPT 推出仅 4 个月。
与ChatGPT最初使用的GPT-3.5模型相比,GPT-4在几个方面实现了跨越式改进:强大的图像识别能力;文本输入限制增加到 25,000 字;回答准确率显着提高;生成歌词的能力,创意文本,实现风格变化。
据悉,OpenAI从2018年开始发布GPT语言模型,GPT-3是GPT语言模型的第三个版本。聊天机器人ChatGPT将于2022年发布,其免费版使用的模型为GPT-3.5。
GPT-4是OpenAI发布的最新最强大的大规模语言模型,其AI能力强于以往任何GPT模型。
> GPT发展史

之所以叫它ChatGPT,是因为它使用了一个叫GPT的自然语言模型,GPT是openAI的一个自然语言处理的模型,到今天已经发展到了第四代。
从GPT发布史来看从18年到20年发布到GPT3后,就没有GPT大版本发布了,这个和GPT3的训练方式也有关系,年初发布的instructGPT和chatGPT都是在此基础上的微调版本,chatGPT能达到如此惊艳的效果也全仰仗GPT3模型,那它为什么如此之强呢。
> 里程碑-GPT3

事实上GPT3相比较上代并没有太大结构上的差异,它之所以这么强主要是因为OpenAI的土豪式的训练方式。从上图可以看出,GPT3相比较GPT2训练的参数量从15亿跃升至1750亿,提高了一百多倍!数据量也达到了45TB。
GPT3通过海量到夸张的数据量,远远超越现有的所有自然语言模型,达到了惊艳的效果,同时1200万美元的巨大训练花费,也是绝大多数企业无法负担的,甚至GPT3自爆训练过程出现一个bug,OpenAI也没有资金重新训练了。
> 从数据到AI — ChatGPT模型训练之路

数据有了,那ChatGPT是如何被训练成一个如此智能的聊天工具的呢,总的来说可以分为以下四个部分:
1.学习文字接龙
先看下GPT如何补全一个完整的句子,首先GPT在网络上收集它看到的所有句子,这样当有文字输入后,GPT选择用哪个文字去对输入的文字做补充,形成完整的句子。
那GPT学习了那么多的句子,它怎么知道该用哪个做补全?所以GPT的输出是几率分布的,学习了所有与这个文字相关的句子,按几率大小,从其中随机抽取出来补全(每次都不一样)。
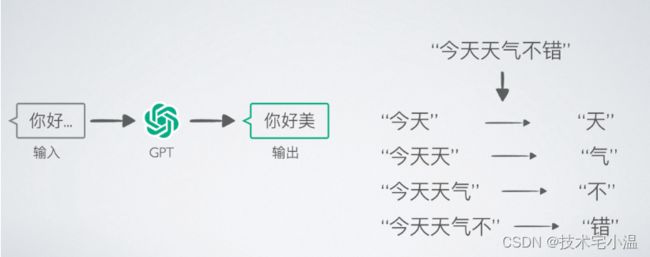
比如它收集的句子中50% “你好” 后面都接 “美”,那当输入“你好”时,GPT就有50%的几率选择用“美”补全,这样GPT就能将字组装成有意义的句了
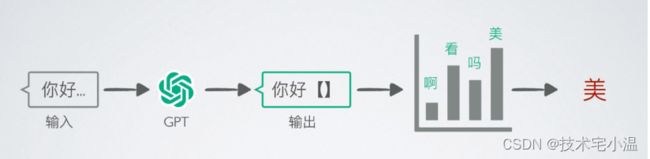
2.人类老师引导文字接龙方向
可仅仅是文字接龙,GPT只能产出有意义的句子,还远远无法达到问答的要求,所以就来到了有人类老师介入的第二个阶段,引导文字接龙方向,让GPT知道人类一般想要得到的句子是什么样的。

通过输入一批代表性的问题和标准答案,让GPT熟悉人类常用的提问模式和想得到的答案类型,起码知道当输入一个问题时,要返回一个陈述句而不是疑问句,不需要穷举所有问题,只是让GPT了解大概偏好 这样GPT筛选出一部分更加贴近人类的答案,抛弃掉很多无用数据。
3.模仿人类制定的偏好,训练老师模型
经过人类引导后,GPT可能对一个输入有多个输出,都符合人类引导的偏好,但是如何进一步在这些输出中,能有更大几率挑选到更优质的答案呢,就需要人类的打分系统。
通过ChatGPT和openAI开源的API,GPT得到越来越多的人类向他提出的问题,GPT会对这些问题输出多个答案,雇佣很多人类老师给GPT的多个答案打分,人类老师不需要告诉GPT标准答案,只需要对GPT已有答案进行打分,GPT慢慢就会了解那些答案是更优质的答案。

通过这些数据训练一个模仿人类老师打分标准的老师模型,用这个模型代替人类,去给GPT模型做打分训练,减少人工成本,GPT模型的答案越来越优质,越来越贴近人类喜好。
4.用增强式学习向模型老师学习
GPT 将输入的问题和它返回的输出的答案,给到老师模型,老师模型已经学会了人类的喜好(如: 老师模型知道输入是个问句,输出如果是问句就给低分,因为用户肯定是希望得到一个答案),他会给 GPT 的输出打分,帮助 GPT 模型训练。

训练不需要人类,模型可以一直不断的自我训练,自我完善,越来越贴近人类需求。
> 特性总结
- 避免专业方向调优使模型更加通用
- 无法复制的海量学习数据
- 极强的上下文连接能力
- 对用户真是意图的理解更深入
- 善于处理广泛的知识和逻辑理解
- InstructGPT有毒回答改了减小25%
- InstructGPT的71%-88%的结果符合人类喜好
ChatGPT国内用户注册方法
- 需要海外VPN节点(非国内、香港)
- 需要非国内邮箱(可用注册Outlook,Gmail很方便)
- 需要海外国家手机号验证码(可用sms-activate.org接码平台,选择ChatGPT,接收一条验证码大概几块钱)
- 官网地址注册(https://beta.openai.com/signup)
参考文献
- OpenAI 中文文档
- 预训练语言模型之GPT-1,GPT-2和GPT-3
- Training language models to follow instructions with human feedback
- OpenAI Codex 论文精读【论文精读】
- GPT——生成式预训练Transformer
- GPT-4 正式发布!如何接入?如何免费使用GPT-4?
往期内容
< 每日算法 - JavaScript解析:搜索旋转排序数组 >
< CSS小技巧:类似photoShop的混合模式(mix-blend-mode / background-blend-mode)使用 >
<开源: 推荐10个开源的前端低代码项目>
< CSS小技巧:那些不常用,却很惊艳的CSS属性 >
< 开源项目框架:推荐几个开箱即用的开源管理系统 - 让开发不再复杂 >