linux 基础
1.Shell 命令的格式
如下:
command -options [argument]
command: Shell 命令名称。
options: 选项,同一种命令可能有不同的选项,不同的选项其实现的功能不同。
argument: Shell 命令是可以带参数的,也可以不带参数运行。
eg:ls -l
Shell 命令是支持自动补全功能的(TAB 键)。
1)目录信息查看命令 ls
文件浏览是最基本的操作了, Shell 下文件浏览命令为 ls,格式如下:
ls [选项] [路径]
ls 命令主要用于显示指定目录下的内容,列出指定目录下包含的所有的文件以及子目录,
它的主要参数有:
-a 显示所有的文件以及子目录,包括以“.”开头的隐藏文件。
-l 显示文件的详细信息,比如文件的形态、权限、所有者、大小等信息。
-t 将文件按照创建时间排序列出。
-A 和-a 一样,但是不列出“.” (当前目录)和“..” (父目录)。
-R 递归列出所有文件,包括子目录中的文件。
Shell 命令里面的参数是可以组合在一起用的,比如组合“-al”就是显示所有文件的详细信息,包括以“.”开头的隐藏文件
2)
cd / //进入到根目录“/”下, Linux 系统的根目录为“/” ,
cd /usr //进入到目录“/usr”里面。
cd .. //进入到上一级目录。
cd ~ //切换到当前用户主目录
3)pwd 命令用来显示当前工作目录的绝对路径,不需要任何的参数
4)系统信息查看命令 uname
-r 列出当前系统的具体内核版本号。
-s 列出系统内核名称。
-o 列出系统信息。
5)清屏命令 clear
6)切换用户执行身份命令 sudo
7)切换用户命令 su
“sudo”是以 root 用户身份执行一个命令,并没有更改当前的用户身份,所有需要 root 身份执行的命令都必须在前面加上“sudo”。
命令“su”可以直接将当前用户切换为 root 用户
8)显示文件内容命令 cat
9)显示和配置网络属性命令 ifconfig
10)系统帮助命令 man
eg:man ifconfig
11)系统重启命令 reboot
12)软件安装命令 install
2.APT 下载工具
1)更新本地数据库
如果想查看本地哪些软件可以更新的话可以使用如下命令:
sudo apt-get update
2)检查依赖关系
有时候本地某些软件可能存在依赖关系,所谓依赖关系就是 A 软件依赖于 B 软件。通过如
下命令可以查看依赖关系,如果存在依赖关系的话 APT 会提出解决方案:
sudo apt-get check
3)软件安装
sudo apt-get install package-name
可以看出上述命令是由“apt-get”和“install”组合在一起的,“package-name”就是要安装的软件名字,“apt-get”负责下载软件,“install”负责安装软件。比如我们要安装软件 Ubuntu 下的串口工具“minicom”,我们就可以使用如下命令:
sudo apt-get install minicom
执行上述命令以后就会自动下载和安装 minicom 软件。
4)软件更新
有时候我们需要更新软件,更新软件的话使用命令:
sudo apt-get upgrade package-name
其中 package-name 为要升级的软件名字,比如我们升级刚刚安装的 minicom 这个软件。
5)卸载软件
如果要卸载某个软件的话使用如下命令:
sudo apt-get remove package-name
其中 package-name 是要卸载的软件,比如卸载前面安装的 minicom 这个软件。
3.VI/VIM 编辑器
1)先安装 VIM 编辑器,命令如下:
sudo apt-get install vim
2)VIM 编辑器有 3 种工作模式:输入模式、指令模式和底行模式
3)输入模式
i 在当前光标所在字符的前面,转为输入模式。
I 在当前光标所在行的行首转换为输入模式。
a 在当前光标所在字符的后面,转为输入模式。
A 在光标所在行的行尾,转换为输入模式。
o 在当前光标所在行的下方,新建一行,并转为输入模式。
O 在当前光标所在行的上方,新建一行,并转为输入模式。
s 删除光标所在字符。
r 替换光标处字符。
4)指令模式
1、移动光标指令:
h(或左方向键) 光标左移一个字符。
l(或右方向键) 光标右移一个字符。
j(或下方向键) 光标下移一行。
k(或上方向键) 光标上移一行。
nG 光标移动到第 n 行首。
n+ 光标下移 n 行。
n- 光标上移 n 行。
2、屏幕翻滚指令
Ctrl+f 屏幕向下翻一页,相当于下一页。
Ctrl+b 屏幕向上翻一页,相当于上一页。
3、复制、删除和粘贴指令
cc 删除整行,并且修改整行内容。
dd 删除该行,不提供修改功能。
ndd 删除当前行向下 n 行。
x 删除光标所在的字符。
X 删除光标前面的一个字符。
nyy 复制当前行及其下面 n 行。
p 粘贴最近复制的内容。
5)底行模式
x 保存当前文档并且退出。
q 退出。
w 保存文档。
q! 退出 VI/VIM,不保存文档。
如果我们要退出并保存文本的话需要在“:”底行模式下输入“wq”
进入 VIM 的底行模式的时候之说了在指令模式下输入“:”的方法,还可以在指令模式下输入“/”进入底行模式,输入“/”。
在“/”底行模式下我们可以在文本中搜索指定的内容,比如搜索 test.txt 文件中“嵌入式”三个字:
/嵌入式
4.根目录“/”中的一些重要的文件夹
/bin 存储一些二进制可执行命令文件, /usr/bin 也存放了一些基于用户的命令文件。
/sbin 存储了很多系统命令, /usr/sbin 也存储了许多系统命令。
/root 超级用户 root 的根目录文件。
/home 普通用户默认目录,在该目录下,每个用户都有一个以本用户名命名的文件夹。
/boot 存放 Ubuntu 系统内核和系统启动文件。
/mnt 通常包括系统引导后被挂载的文件系统的挂载点。
/dev 存放设备文件,我们后面学习 Linux 驱动主要是跟这个文件夹打交道的。
/etc 保存系统管理所需的配置文件和目录。
/lib 保存系统程序运行所需的库文件, /usr/lib 下存放了一些用于普通用户的库文件。
/lost+found 一般为空,当系统非正常关机以后,此文件夹会保存一些零散文件。
/var 存储一些不断变化的文件,比如日志文件
/usr 包括与系统用户直接有关的文件和目录,比如应用程序和所需的库文件。
/media 存放 Ubuntu 系统自动挂载的设备文件。
/proc 虚拟目录,不实际存储在磁盘上,通常用来保存系统信息和进程信息。
/tmp 存储系统和用户的临时文件,该文件夹对所有的用户都提供读写权限。
/opt 可选文件和程序的存放目录。
/sys 系统设备和文件层次结构,并向用户程序提供详细的内核数据信息。
5.文件操作命令
1)创建新文件命令—touch
2)文件夹创建命令—mkdir
3)文件及目录删除命令—rm
rm [参数] [目的文件或文件夹目录名]
命令主要参数如下:
-d 直接把要删除的目录的硬连接数据删成 0,删除该目录。
-f 强制删除文件和文件夹(目录)。
-i 删除文件或者文件夹(目录)之前先询问用户。
-r 递归删除,指定文件夹(目录)下的所有文件和子文件夹全部删除掉。
-v 显示删除过程。
直接使用命令“rm”是无法删除文件夹(目录)的,我们需要加上参数“-rf”,也就是强制递归删除文件夹(目录)
4)文件夹(目录)删除命令—rmdir
rmdir,它可以不加任何参数的删除掉指定的文件夹(目录)
5)文件复制命令—cp
cp [参数] [源地址] [目的地址]
主要参数描述如下:
-a 此参数和同时指定“-dpR”参数相同
-d 在复制有符号连接的文件时,保留原始的连接。
-f 强行复制文件,不管要复制的文件是否已经存在于目标目录。
-I 覆盖现有文件之前询问用户。
-p 保留源文件或者目录的属性。
-r 或-R 递归处理,将指定目录下的文件及子目录一并处理
通配符“*”
6)文件移动命令—mv
mv [参数] [源地址] [目的地址]
主要参数描述如下:
-b 如果要覆盖文件的话覆盖前先进行备份。
-f 若目标文件或目录与现在的文件重复,直接覆盖目的文件或目录。
-I 在覆盖之前询问用户。
6.文件压缩和解压缩
命令行下进行压缩和解压缩常用的命令有三个: zip、 unzip 和 tar
1)命令 zip
zip 命令看名字就知道是针对.zip 文件的,用于将一个或者多个文件压缩成一个.zip 结尾的文件,命令格式如下:
zip [参数] [压缩文件名.zip] [被压缩的文件]
eg:zip -rv test2.zip test2
主要参数函数如下:
-b<工作目录> 指定暂时存放文件的目录。
-d 从 zip 文件中删除一个文件。
-F 尝试修复已经损毁的压缩文件。
-g 将文件压缩入现有的压缩文件中,不需要新建压缩文件。
-h 帮助。
-j 只保存文件的名,不保存目录。
-m 压缩完成以后删除源文件。
-n<字尾符号> 不压缩特定扩展名的文件。
-q 不显示压缩命令执行过程。
-r 递归压缩,将指定目录下的所有文件和子目录一起压缩。
-v 显示指令执行过程。
-num 压缩率,为 1~9 的数值。
2)命令 unzip
unzip 命令用于对.zip 格式的压缩包进行解压,命令格式如下:
unzip [参数] [压缩文件名.zip]
主要参数如下:
-l 显示压缩文件内所包含的文件。
-t 检查压缩文件是否损坏,但不解压。
-v 显示命令显示的执行过程。
-Z 只显示压缩文件的注解。
-C 压缩文件中的文件名称区分大小写。
-j 不处理压缩文件中的原有目录路径。
-L 将压缩文件中的全部文件名改为小写。
-n 解压缩时不要覆盖原有文件。
-P<密码> 解压密码。
-q 静默执行,不显示任何信息。
-x<文件列表> 指定不要处理.zip 中的哪些文件。
-d<目录> 把压缩文件解到指定目录下。
3)命令 tar
zip 和 unzip 这两个是命令只适用于.zip 格式的压缩和解压,其它压缩格式就用不了了,比如 Linux 下最常用的.bz2 和.gz 这两种压缩格式。其它格式的压缩和解压使用命令tar, tar 将压缩和解压缩集合在一起,使用不同的参数即可。
tar [参数] [压缩文件名] [被压缩文件名]
常用参数如下:
-c 创建新的压缩文件。
-C<目的目录> 切换到指定的目录。
-f<备份文件> 指定压缩文件。
-j 用 tar 生成压缩文件,然后用 bzip2 进行压缩。
-k 解开备份文件时,不覆盖已有的文件。
-m 还原文件时,不变更文件的更改时间。
-r 新增文件到已存在的备份文件的结尾部分。
-t 列出备份文件内容。
-v 显示指令执行过程。
-w 遭遇问题时先询问用户。
-x 从备份文件中释放文件,也就是解压缩文件。
-z 用 tar 生成压缩文件,用 gzip 压缩。
-Z 用 tar 生成压缩文件,用 compress 压缩。
eg:使用如下两个命令将 test1 文件夹压缩为.bz2 和.gz 这两个格式:
tar -vcjf test1.tar.bz2 test1
tar -vczf test1.tar.gz test1
-vcjf 表示创建 bz2 格式的压缩文件, -vczf 表示创建.gz 格式的压缩文件。
eg:使用如下所示两行命令完成.bz2 和.gz 格式文件的解压缩:
tar -vxjf test1.tar.bz2
tar -vxzf test2.tar.gz
-vxjf 用来完成.bz2 格式压缩文件的解压, -vxzf 用来完成.gz 格式压缩文件的解压。
7.文件查询和搜索
常用的文件查询和搜索命令: find 和 grep
1)命令 find
find 命令用于在目录结构中查找文件,其命令格式如下:
find [路径] [参数] [关键字]
路径是要查找的目录路径,如果不写的话表示在当前目录下查找,关键字是文件名的一部分,主要参数如下:
-name
-depth 从指定目录下的最深层的子目录开始查找。
-gid<群组识别码> 查找符合指定的群组识别码的文件或目录。
-group<群组名称> 查找符合指定的群组名称的文件或目录。
-size<文件大小> 查找符合指定文件大小的文件。
-type<文件类型> 查找符合指定文件类型的文件。
-user<拥有者名称> 查找符合指定的拥有者名称的文件或目录。
2)命令 grep
find 命令用于在目录中搜索文件,我们有时候需要在文件中搜索一串关键字, grep 就是完成这个功能的, grep 命令用于查找包含指定关键字的文件,如果发现某个文件的内容包含所指定的关键字, grep 命令就会把包含指定关键字的这一行标记出来, grep 命令格式如下:
grep [参数] 关键字 文件列表
grep 命令一次只能查一个关键字,主要参数如下:
-b 在显示符合关键字的那一列前,标记处该列第 1 个字符的位编号。
-c 计算符合关键字的列数。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用此参数!否则 grep 指令将回报信息并停止搜索。
-i 忽略字符大小写。
-v 反转查找,只显示不匹配的行。
-r 在指定目录中递归查找。
8.文件类型
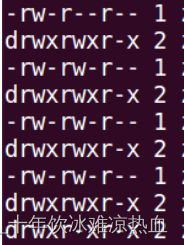
这些字符表示的文件类型如下:
- 普通文件,一些应用程序创建的,比如文档、图片、音乐等等。
d 目录文件。
c 字符设备文件, Linux 驱动里面的字符设备驱动,比如串口设备,音频设备等。
b 块设备文件,存储设备驱动,比如硬盘, U 盘等。
l 符号连接文件,相当于 Windwos 下的快捷方式。
s 套接字文件。
p 管道文件,主要指 FIFO 文件
9.Linux 用户权限管理
1)对于一个文件通常有三种权限:读(r)、写(w)和执行(x)
其中“-rw-rw-r--”表示文件权限与用户和用户组之间的关系,第一位表示文件类型。
权限是“rw-”,也就是对该文件拥有读和写两种权限。
权限是“r--”,也就是只读权限。
使用命令“sudo”命令暂时切换到 root 用户
2)文件的权限有三种:读(r)、写(w)和执行(x),除了用 r、 w 和 x 表示以外,
我们也可以使用二进制数表示,三种权限就可以使用 3 位二进制数来表示,一种权限对应一个二进制位,如果该位为 1 就表示具备此权限,如果该位为 0 就表示没不具备此权限


其权限为“rw-rw-r--”,因此其十进制表示就是: 664。
10.权限管理命令
使用 Shell 来操作文件的权限管理,主要用到“chmod”和“chown”这两个命令
1)权限修改命令 chmod
命令“chmod”用于修改文件或者文件夹的权限,权限可以使用前面讲的数字表示也可以使用字母表示,命令格式如下:
chmod [参数] [文件名/目录名]
eg:chmod 776 test
主要参数如下:
-c 效果类似“-v”参数,但仅回显更改的部分。
-f 不显示错误信息。
-R 递归处理,指定目录下的所有文件及其子文件目录一起处理。
-v 显示指令的执行过程。
2)文件归属者修改命令 chown
命令 chown 用来修改某个文件或者目录的归属者用户或者用户组,命令格式如下:
chown [参数] [用户名.<组名>] [文件名/目录]
其中[用户名.<组名>]表示要将文件或者目录改为哪一个用户或者用户组,用户名和组名用“.”隔开,其中用户名和组名中的任何一个都可以省略,命令主要参数如下:
-c 效果同-v 类似,但仅显示更改的部分。
-f 不显示错误信息。
-h 只对符号连接的文件做修改,不改动其它任何相关的文件。
-R 递归处理,将指定的目录下的所有文件和子目录一起处理。
-v 显示处理过程。
10.Linux 磁盘管理
文件/etc/fstab 详细的记录了 Ubuntu 中硬盘分区的情况
使用命令“ls /dev/sd*”来查看当前的“/dev/sd*”设备文件
1)磁盘管理命令
磁盘分区命令 fdisk
如果要对某个磁盘进行分区,可以使用命令 fdisk,命令格如下:
fdisk [参数]
主要参数如下:
-b<分区大小> 指定每个分区的大小。
-l 列出指定设备的分区表。
-s<分区编号> 将指定的分区大小输出到标准的输出上,单位为块。
-u 搭配“-l”参数,会用分区数目取代柱面数目,来表示每个分区的起始地址。
2)格式化命令 mkfs
使用命令 fdisk 创建好一个分区以后,我们需要对其格式化,也就是在这个分区上创建一个文件系统, Linux 下的格式化命令为 mkfs,命令格式如下:
mkfs [参数] [-t 文件系统类型] [分区名称]
主要参数如下:
fs 指定建立文件系统时的参数
-V 显示版本信息和简要的使用方法。
-v 显示版本信息和详细的使用方法。
比如我们要格式化 U 盘的分区/dev/sdb1 为 FAT 格式,那么就可以使用如下命令:
mkfs – t vfat /dev/sdb1
3)挂载分区命令 mount
mount [参数] -t [类型] [设备名称] [目的文件夹]
命令主要参数有:
-V 显示程序版本。
-h 显示辅助信息。
-v 显示执行过程详细信息。
-o ro 只读模式挂载。
-o rw 读写模式挂载。
-s-r 等于-o ro。
-w 等于-o rw。
4)卸载命令 umount
当我们不再需要访问已经挂载的 U 盘,可以通过 umount 将其从卸载点卸除,命令格式如下:
umount [参数] -t [文件系统类型] [设备名称]
-a 卸载/etc/mtab 中的所有文件系统。
-h 显示帮助。
-n 卸载时不要将信息存入到/etc/mtab 文件中
-r 如果无法成功卸载,则尝试以只读的方式重新挂载。
-t<文件系统类型> 仅卸载选项中指定的文件系统。
-v 显示执行过程。
11.GCC 编译器
gcc [选项] [文件名字]
主要选项如下:
-c: 只编译不链接为可执行文件,编译器将输入的.c 文件编译为.o 的目标文件。
-o: <输出文件名>用来指定编译结束以后的输出文件名,如果不使用这个选项的话 GCC 默认编译出来的可执行文件名字为 a.out。
-g: 添加调试信息,如果要使用调试工具(如 GDB)的话就必须加入此选项,此选项指示编译的时候生成调试所需的符号信息。
-O: 对程序进行优化编译,如果使用此选项的话整个源代码在编译、链接的的时候都会进行优化,这样产生的可执行文件执行效率就高。
-O2: 比-O 更幅度更大的优化,生成的可执行效率更高,但是整个编译过程会很慢。
GCC 编译器的编译流程是:预处理、编译、汇编和链接。
预处理就是展开所有的头文件、替换程序中的宏、解析条件编译并添加到文件中。
编译是将经过预编译处理的代码编译成汇编代码,也就是我们常说的程序编译。
汇编就是将汇编语言文件编译成二进制目标文件。
链接就是将汇编出来的多个二进制目标文件链接在一起,形成最终的可执行文件,链接的时候还会涉
及到静态库和动态库等问题。
12.Makefile 基础
1)Makefile 规则格式
目标…... : 依赖文件集合……
命令 1
命令 2
……2)Makefile 变量
Makefile 中的变量都是字符串!类似 C 语言中的宏
#Makefile 变量的使用
objects = main.o input.o calcu.o
main: $(objects)
gcc -o main $(objects)Makefile 中可以写注释,注释开头要用符号“#”,不能用 C 语言中的“//”或者“/**/”!
第 2 行我们定义了一个变量 objects,并且给这个变量进行了赋值,其值为字符串“main.o input.o calcu.o”。
第 3 和 4 行使用到了变量 objects,Makefile 中变量的引用方法是“$(变量名)”,比如本例中的“$(objects)”就是使用变量 objects。
3)在定义变量 objects 的时候
使用“=”对其进行了赋值, Makefile变量的赋值符还有其它两个“:=”和“?=”,我们来看一下这三种赋值符的区别:
1、赋值符“=”
使用“=”在给变量的赋值的时候,不一定要用已经定义好的值,也可以使用后面定义的值。也就是变量的真实值取决于它所引用的变量的最后一次有效值。
2、赋值符“:=”
赋值符“:=”不会使用后面定义的变量,只能使用前面已经定义好的,这就是“=”和“:=”两个的区别。
3、赋值符“?=”
“?=”是一个很有用的赋值符,比如下面这行代码:
curname ?= zzk
上述代码的意思就是,如果变量 curname 前面没有被赋值,那么此变量就是“zzk”,如果前面已经赋过值了,那么就使用前面赋的值。
4、变量追加“+=”
Makefile 中的变量是字符串,有时候我们需要给前面已经定义好的变量添加一些字符串进
去,此时就要使用到符号“+=”,比如如下所示代码:
objects = main.o inpiut.o
objects += calcu.o
一开始变量 objects 的值为“main.o input.o”,后面我们给他追加了一个“calcu.o”,因此变量 objects 变成了“main.o input.o calcu.o”,这个就是变量的追加。
4)Makefile 模式规则
目标中的“%”表示对文件名的匹配,“%”表示长度任意的非空字符串
#当“%”出现在目标中的时候,目标中“%”所代表的值决定了依赖中的“%”值,使用方法如下:
%.o : %.c
命令5)Makefile 自动化变量

6)Makefile 伪目标
声明方式如下:
.PHONY : clean
使用伪目标主要是为了避免 Makefile 中定义的执行命令的目标和工作目录下的实际文件出现名字冲突,有时候我们需要编写一个规则用来执行一些命令,但是这个规则不是用来创建文件的。
7)Makefile 条件判断
<条件关键字>
<条件为真时执行的语句>
endif
以及:
<条件关键字>
<条件为真时执行的语句>
else
<条件为假时执行的语句>
endif条件关键字有 4 个: ifeq、 ifneq、 ifdef 和 ifndef,
这四个关键字其实分为两对、 ifeq 与ifneq、 ifdef 与 ifndef
ifeq (<参数 1>, <参数 2>)
ifeq ‘<参数 1 >’ ,‘ <参数 2>’
ifeq “<参数 1>” , “<参数 2>”
ifeq “<参数 1>” , ‘<参数 2>’
ifeq ‘<参数 1>’ , “<参数 2>”上述用法中都是用来比较“参数 1”和“参数 2”是否相同,如果相同则为真,“参数 1”和“参数 2”可以为函数返回值。 ifneq 的用法类似,只不过 ifneq 是用来了比较“参数 1”和“参数 2”是否不相等,如果不相等的话就为真。
ifdef 和 ifndef 的用法如下:
ifdef <变量名>
如果“变量名”的值非空,那么表示表达式为真,否则表达式为假。“变量名”同样可以是一个函数的返回值。 ifndef 用法类似,但是含义用户 ifdef 相反。
8)Makefile 函数使用
函数的用法如下:
$(函数名 参数集合)
或者:
${函数名 参数集合}
调用函数和调用普通变量一样,使用符号“$”来标识。参数集合是函数的多个参数,参数之间以逗号“,”隔开,函数名和参数之间以“空格”分隔开,函数的调用以“$”开头。
1、函数 subst
函数 subst 用来完成字符串替换,调用形式如下:
$(subst
此函数的功能是将字符串
2、函数 patsubst
函数 patsubst 用来完成模式字符串替换,使用方法如下:
$(patsubst
eg:$(patsubst %.c,%.o,a.c b.c c.c)
将字符串“a.c b.c c.c”中的所有符合“%.c”的字符串,替换为“%.o”,替换完成以后的字符串为“a.o b.o c.o”。
3、函数 dir
函数 dir 用来获取目录,使用方法如下:
$(dir
eg:$(dir )
提取文件“/src/a.c”的目录部分,也就是“/src”。
4、函数 notdir
函数 notdir 看名字就是知道去除文件中的目录部分,也就是提取文件名
$(notdir
eg:$(notdir )
提取文件“/src/a.c”中的非目录部分,也就是文件名“a.c”。
5、函数 foreach
foreach 函数用来完成循环,用法如下:
$(foreach , ,
此函数的意思就是把参数中的单词逐一取出来放到参数中,然后再执行
6、函数 wildcard
通配符“%”只能用在规则中,只有在规则中它才会展开,如果在变量定义和函数使用时,通配符不会自动展开,这个时候就要用到函数 wildcard,使用方法如下:
$(wildcard PATTERN…)
比如:
$(wildcard *.c)
上面的代码是用来获取当前目录下所有的.c 文件,类似“%”。
13.GNU 汇编语法
编译使用的 GCC 交叉编译器,所以我们的汇编代码要符合 GNU 语法。
GNU 汇编语法适用于所有的架构,并不是 ARM 独享的, GNU 汇编由一系列的语句组成,每行一条语句,每条语句有三个可选部分,如下:
label: instruction @ comment
label 即标号,表示地址位置,有些指令前面可能会有标号,这样就可以通过这个标号得到指令的地址,标号也可以用来表示数据地址。注意 label 后面的“:”,任何以“:”结尾的标识符都会被识别为一个标号。
instruction 即指令,也就是汇编指令或伪指令。
@符号,表示后面的是注释,就跟 C 语言里面的“/*”和“*/”一样,其实在 GNU 汇编文件中我们也可以使用“/*”和“*/”来注释。
comment 就是注释内容。
比如如下代码:
add:
MOVS R0, #0X12 @设置 R0=0X12
上面代码中“add:”就是标号,“MOVS R0,#0X12”就是指令,最后的“@设置 R0=0X12”就是注释。
ARM 中的指令、伪指令、伪操作、寄存器名等可以全部使用大写,也可以全部使用小写,但是不能大小写混用。
用户可以使用.section 伪操作来定义一个段,汇编系统预定义了一些段名:
.text 表示代码段。
.data 初始化的数据段。
.bss 未初始化的数据段。
.rodata 只读数据段。
汇编程序的默认入口标号是_start,不过我们也可以在链接脚本中使用 ENTRY 来指明其它的入口点,下面的代码就是使用_start 作为入口标号:
.global _start
_start:
ldr r0, =0x12 @r0=0x12
上面代码中.global 是伪操作,表示_start 是一个全局标号,类似 C 语言里面的全局变量一样.