【Pytorch-神经网络的两种快速搭建方法-包含回归和分类的两个例子】
快速搭建方法1
使用pytorch快速搭建的方法
net2 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
Sequential(
(0): Linear(in_features=1, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=1, bias=True)
)
常规搭建方法2
# 建立神经网络
class Net(torch.nn.Module):
def __init__(self,n_features,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_features,n_hidden)
self.predict = torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net1= Net(2,10,2)
Net(
(hidden): Linear(in_features=2, out_features=10, bias=True)
(predict): Linear(in_features=10, out_features=2, bias=True)
)
分类例子
结果显示
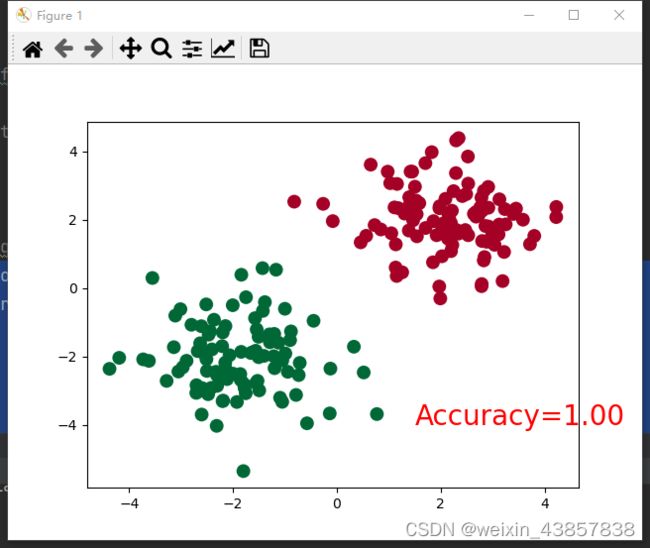
建立数据
# 假数据
n_data = torch.ones(100, 2) # 数据的基本形态
#normal该函数返回从单独的正态分布中提取的随机数的张量
x0 = torch.normal(2*n_data, 1) # 类型0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # 类型0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # 类型1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # 类型1 y data (tensor), shape=(100, 1)
# 注意 x, y 数据的数据形式是一定要像下面一样 (torch.cat 是在合并数据, 按维数0(行)拼接)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # LongTensor = 64-bit integer
使用我们曾经搭建的net进行训练
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.02) # 传入 net 的所有参数, 学习率
# 算误差的时候, 注意真实值!不是! one-hot 形式的, 而是1D Tensor, (batch,)
# 但是预测值是2D tensor (batch, n_classes)
loss_func = torch.nn.CrossEntropyLoss()
# plt.ion() # 画图
# plt.show()
for t in range(100):
out = net(x) # 喂给 net 训练数据 x, 输出分析值
loss = loss_func(out, y) # 计算两者的误差
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
画图显示
if t % 2 == 0:
plt.cla()
# 过了一道 softmax 的激励函数后的最大概率才是预测值
prediction = torch.max(F.softmax(out), 1)[1]
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / 200. # 预测中有多少和真实值一样
plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
完整代码
import torch
import numpy as np
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 假数据
n_data = torch.ones(100, 2) # 数据的基本形态
#normal该函数返回从单独的正态分布中提取的随机数的张量
x0 = torch.normal(2*n_data, 1) # 类型0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # 类型0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # 类型1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # 类型1 y data (tensor), shape=(100, 1)
# 注意 x, y 数据的数据形式是一定要像下面一样 (torch.cat 是在合并数据, 按维数0(行)拼接)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # LongTensor = 64-bit integer
# 画图
# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
# plt.show()
#
# 建立神经网络
class Net(torch.nn.Module):
def __init__(self,n_features,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_features,n_hidden)
self.predict = torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net2 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
net = Net(2,10,2)
print(net)
print(net2)
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.02) # 传入 net 的所有参数, 学习率
# 算误差的时候, 注意真实值!不是! one-hot 形式的, 而是1D Tensor, (batch,)
# 但是预测值是2D tensor (batch, n_classes)
loss_func = torch.nn.CrossEntropyLoss()
# plt.ion() # 画图
# plt.show()
for t in range(100):
out = net(x) # 喂给 net 训练数据 x, 输出分析值
loss = loss_func(out, y) # 计算两者的误差
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
# 接着上面来
if t % 2 == 0:
plt.cla()
# 过了一道 softmax 的激励函数后的最大概率才是预测值
prediction = torch.max(F.softmax(out), 1)[1]
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / 200. # 预测中有多少和真实值一样
plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
#
# plt.ioff() # 停止画图
# plt.show()
回归例子
结果显示
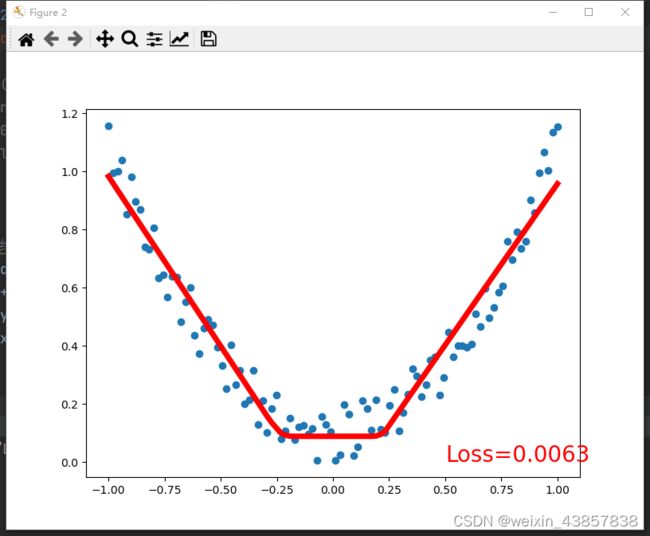
完整代码
x = torch.unsqueeze(torch.linspace(-1,1,100),dim=1)
y = x.pow(2) + 0.2*torch.rand(x.size())
y = Variable(y)
x = Variable(x)
# 建立神经网络
class Net(torch.nn.Module):
def __init__(self,n_features,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_features,n_hidden)
self.predict = torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(1,10,1)
# # net(x)
# print(net(x))
# plt.scatter(x,net(x).data.numpy())
# plt.show()
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(),lr=0.5)
loss_fun = torch.nn.MSELoss() # 预测值和真实值的误差计算公式 (均方差)
plt.figure(2, figsize=(8, 6))
plt.ion()
for t in range(100):
prediction = net(x)# 喂给 net 训练数据 x, 输出预测值
loss = loss_fun(prediction,y)# 计算两者的误差
optimizer.zero_grad()# 清空上一步的残余更新参数值
loss.backward()# 误差反向传播, 计算参数更新值
# 优化梯度
optimizer.step()# 将参数更新值施加到 net 的 parameters 上
# 接着上面来
if t % 5 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy()) # 离散的点
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()