深度文本分类之DPCNN
文章目录
-
- 深度文本分类之DPCNN
-
- DPCNN结构
- Region Embedding
- 等长卷积
- 固定Feature Map的数量
- 1/2池化层
- 残差连接
-
- 残差网络
- 残差块
- 残差网络背后的原理
- 直接映射是最好的选择
- 激活函数的位置
- 参考
深度文本分类之DPCNN
由于TextCNN不能通过卷积获得文本的长距离依赖关系,而DPCNN通过不断加深网络,可以抽取长距离的文本依赖关系
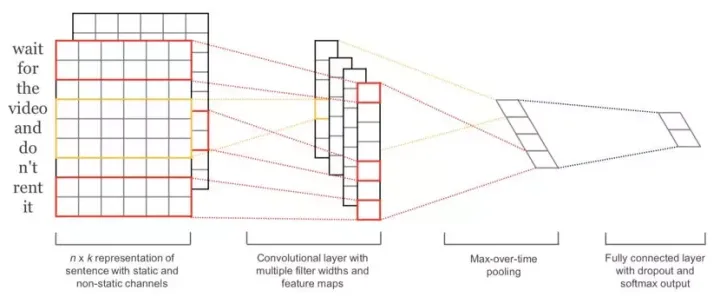
DPCNN结构
Region Embedding
从上图中可以看出,DPCNN的底层貌似保持了跟TextCNN一样的结构的结构,这里作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称为Region embedding
等长卷积
在得到Region embedding后,为了避免后续想象太抽象,我们不妨还是把Region embedding看成word embedding
首先交代一下卷积的基本概念,一般常用的卷积有以下三类:
假设输入的序列长度为n,卷积核大小为m,步长(stride)为s,输入序列两端各填补p个零(zero padding),那么该卷积层的输出序列为(n-m+2p)/s+1。
- 窄卷积(narrow convolution): 步长s=1,两端不补零,即p=0,卷积后输出长度为n-m+1。
- 宽卷积(wide convolution) :步长s=1,两端补零p=m-1,卷积后输出长度 n+m-1。
- 等长卷积(equal-width convolution): 步长s=1,两端补零p=(m-1)/2,卷积后输出长度为n。
对word embedding序列进行等长卷积的意义:既然输入输出序列的位置数一样多,我们将输入输出序列的第n个embedding称为第n个词位,那么这时size为m的卷积核产生的等长卷积就是将输入序列的每个词位及其左右((n-1)/2)个词的上下文信息压缩为该词位的embedding,即产生了每个词位的被上下文信息修饰过的更高level更加准确的语义。
回到DPCNN上来,我们想要克服TextCNN的缺点,捕获长距离模式,显然就要用到深层CNN,那么直接等长卷积堆等长卷积可不可以呢?
显然这样会让每个词位包含进去越来越多、越来越长的上下文信息,这样做会让网络层数变得非常非常深。不过,既然等长卷积堆等长卷积会让每个词位的embedding语义描述的更加丰富准确,那么当然我们可以适当的堆两层来提高词位embedding的表示的丰富性。
固定Feature Map的数量
在表示好每个词位的语义后,其实很多邻接词的语义都是可以合并的,例如“小娟 姐姐 人 不要 太好”中的“不要”和“太好”虽然语义本来离得很远,但是作为邻接词“不要太好”出现时其语义基本等价为“很好”,这样完全可以把“不要”和“太好”的语义进行合并。同时,合并的过程完全可以在原始的embedding space中进行的,毕竟原文中直接把“不要太好”合并为“很好”是很可以的哇,完全没有必要动整个语义空间。
在DPCNN中固定住了feature map的数量,也就是固定住了embedding space(语义空间)的维度,使得网络有可能让整个邻接词的合并操作在原始空间或者与原始空间相似的空间中进行(当然,网络在实际中会不会这样做是不一定的,只是提供了这么一种条件)
也就是说,整个网络虽然形状上来看是深层的,但是从语义空间上来看完全可以是扁平的。
1/2池化层
在上述合并条件下,我们可以用pooling layer进行合并。
每经过一个size=3, stride=2(大小为3,步长为2)的池化层(以下简称1/2池化层),序列的长度就被压缩成了原来的一半。
同样是size=3的卷积核,每经过一个1/2池化层后,其能感知到的文本片段就比之前长了一倍。例如之前是只能感知3个词位长度的信息,经过1/2池化层后就能感知6个词位长度的信息
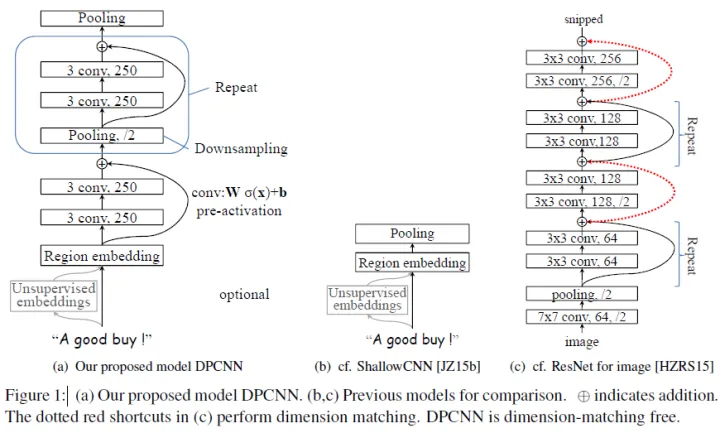
剩下的我们就只需要重复的进行等长卷积+等长卷积+1/2池化就可以了,如下图所示的Block:

残差连接
但是!如果问题真的这么简单的话,深度学习就一下子少了超级多的难点了。
首先,由于我们在初始化深度CNN时,往往各层权重都是初始化为一个很小的值,这就导致最开始的网络中,后续几乎每层的输入都是接近0,这时网络的输出自然是没意义的,而这些小权重同时也阻碍了梯度的传播,使得网络的初始训练阶段往往要迭代好久才能启动。
同时,就算网络启动完成,由于深度网络中仿射矩阵(每两层间的连接边)近似连乘,训练过程中网络也非常容易发生梯度爆炸或消失问题
我们可以使用ResNet中提出的shortcut-connection/skip-connection/residual-connection(残差连接)来解决上述问题
下面我们补充一些关于残差连接的知识:
- 过拟合:在训练集上的误差变低,在测试集上的误差变高
- 退化:在训练集和测试集上的误差都变高
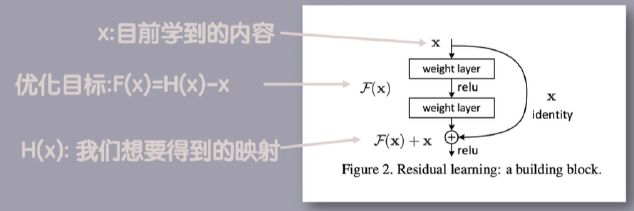
对于 resnet残差连接可以用“传话筒”游戏来通俗理解:类似于《王牌》中的传话筒,腾哥在看到了“狗中赤兔”这个词后,形象地演给花花看,花花又演给晓彤看,最后晓彤演给玲姐看,结果玲姐看完一脸懵~。可以看出,“狗中赤兔”在传递过程中信息是不断减少的,腾哥获得了最多的信息,而玲姐获得的最少,这就类似于浅层网络获得的信息多,而深层少,最终深层网络无法理解传来的信息,也就是玲姐猜不出来题。(这一现象称之为“梯度消失”,就是指信息一层层不断减少直至消失)那怎么办呢?为了解决这个问题,腾哥就跳过花花晓彤,单独给玲姐演了一遍,结果玲姐顿悟—“狗中赤兔”!这相当于浅层网络绕开中间网络,把信息直接传给了深层网络,深层网络秒懂。残差连接就是将信息直接传给深层网络,避免了浅层网络对信息的削减。(还有一种“梯度爆炸”现象,是指每一层网络传递的信息越来越多,导致深层网络直接“死机”了)
残差网络
在VGG中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。那么,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题:
- 计算资源的消耗
- 模型容易过拟合
- 梯度消失/梯度爆炸问题的产生
问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;问题3通过Batch Normalization也可以避免。貌似我们只要无脑地增加网络的层数,我们就能从此获益,但实验数据给了我们当头一棒。
在前向传输的过程中,随着层数的加深, Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了 l+1 层的网络一定比 l 层包含更多的图像信息。
基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。
残差块
残差网络是由一系列残差块组成的,一个残差块可以用表示为:
x l + 1 = x l + F ( x l + W l ) x_{l+1}=x_l+F(x_l+W_l) xl+1=xl+F(xl+Wl)
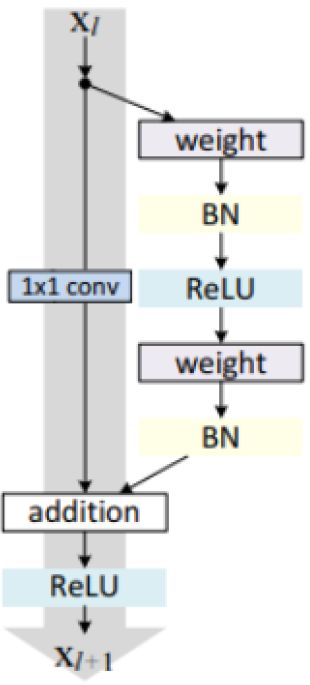
残差块分成两部分:直接映射部分和残差部分。 xl是直接映射,反应在下图中是左边的曲线;F(xl, Wl)是残差部分,一般由两个或者三个卷积操作构成,即下图中右侧包含卷积的部分。

Weight在卷积网络中是指卷积操作,addition是指单位加操作
feature map的数量:该层卷积核的个数,有多少个卷积核,经过卷积就会产生多少个feature map【对应吴恩达讲的课程则是:有多少个滤波器就会产生多少个不同的特征,即滤波器的数量等于feature map的数量】
在卷积网络中, xl 可能和 xl+1 的Feature Map的数量不一样,这时候就需要使用 1×1 卷积进行升维或者降维
这时,残差块表示为:
x l + 1 = h ( x l ) + F ( x l + W l ) x_{l+1}=h(x_l)+F(x_l+W_l) xl+1=h(xl)+F(xl+Wl)
残差网络背后的原理
残差块一个更通用的表示方式:
x l + 1 = h ( x l ) + F ( x l + W l ) x l + 1 = f ( y l ) x_{l+1}=h(x_l)+F(x_l+W_l)\\ x_{l+1}=f(y_l) xl+1=h(xl)+F(xl+Wl)xl+1=f(yl)
h(⋅) 是直接映射, f(⋅) 是激活函数,一般使用ReLU。我们首先给出两个假设:
- 假设1: h(⋅) 是直接映射;
- 假设2: f(⋅) 是直接映射
那么这时候残差块可以表示为:
x l + 1 = x l + F ( x l + W l ) x_{l+1}=x_l+F(x_l+W_l) xl+1=xl+F(xl+Wl)
对于一个更深的层 L ,其与 l 层的关系可以表示为:
x L = x l + ∑ i = l L − 1 F ( x i , W i ) x_L=x_l+\sum_{i=l}^{L-1}F(x_i,W_i) xL=xl+i=l∑L−1F(xi,Wi)
∂ ϵ ∂ x l = ∂ ϵ ∂ x L ∂ x L ∂ x l = ∂ ϵ ∂ x L ( 1 + ∂ ∂ x l ∑ i = 1 L − 1 F ( x i , W i ) ) = ∂ ϵ ∂ x L + ∂ ϵ ∂ x L ∂ ∂ x l ∑ i = 1 L − 1 F ( x i , W i ) \frac{\partial{\epsilon}}{\partial{x_l}}=\frac{\partial{\epsilon}}{\partial{x_L}}\frac{\partial{x_L}}{\partial{x_l}}=\frac{\partial{\epsilon}}{\partial{x_L}}(1+\frac{\partial}{\partial{x_l}}\sum_{i=1}^{L-1}F(x_i,W_i))=\frac{\partial{\epsilon}}{\partial{x_L}}+\frac{\partial{\epsilon}}{\partial{x_L}}\frac{\partial}{\partial{x_l}}\sum_{i=1}^{L-1}F(x_i,W_i) ∂xl∂ϵ=∂xL∂ϵ∂xl∂xL=∂xL∂ϵ(1+∂xl∂i=1∑L−1F(xi,Wi))=∂xL∂ϵ+∂xL∂ϵ∂xl∂i=1∑L−1F(xi,Wi)
上面公式反映了残差网络的两个属性:
- 整个训练过程中,
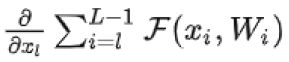
不可能一直为-1,也就是说在残差网络中不会出现梯度消失的问题 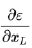
表示L层的梯度可以直接传递到任何一个比它浅的l层
通过分析残差网络的正向和反向两个过程,我们发现,当残差块满足上面两个假设时,信息可以非常畅通的在高层和低层之间相互传导,说明这两个假设是让残差网络可以训练深度模型的充分条件。
直接映射是最好的选择
激活函数的位置
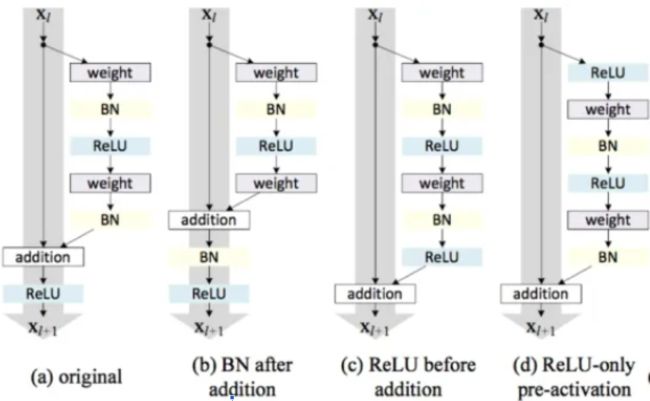
我们们希望构造一种结构能够满足直接映射,即定义一个新的残差结构 f^(⋅) :
y l + 1 = y l + F ( f ^ ( y l ) , w l + 1 ) y_{l+1}=y_l+F(\hat{f}(y_l),w_{l+1}) yl+1=yl+F(f^(yl),wl+1)
上面公式反应到网络里即将激活函数移到残差部分使用
而实验结果也表明将激活函数移动到残差部分可以提高模型的精度
既然每个block的输入在初始阶段容易是0而无法激活,那么直接用一条线把region embedding层连接到每个block的输入乃至最终的池化层/输出层就可以啦
想象一下,这时的shortcut connection由于连接到了各个block的输入(当然为了匹配输入维度,要事先经过对应次数的1/2池化操作),这时就相当于一个短路连接,即region embedding直接短路连接到了最终的池化层或输出层。等等,这时的DPCNN不就退化成了TextCNN嘛。深度网络不好训练,就一层的TextCNN可是异常容易训练的。这样模型的起步阶段就是从TextCNN起步了,自然不会遭遇前面说的深度CNN网络的冷启动问题了。
同样的道理,有了shortcut后,梯度就可以忽略卷积层权重的削弱,从shortcut一路无损的传递到各个block手里,直至网络前端,从而极大的缓解了梯度消失问题。
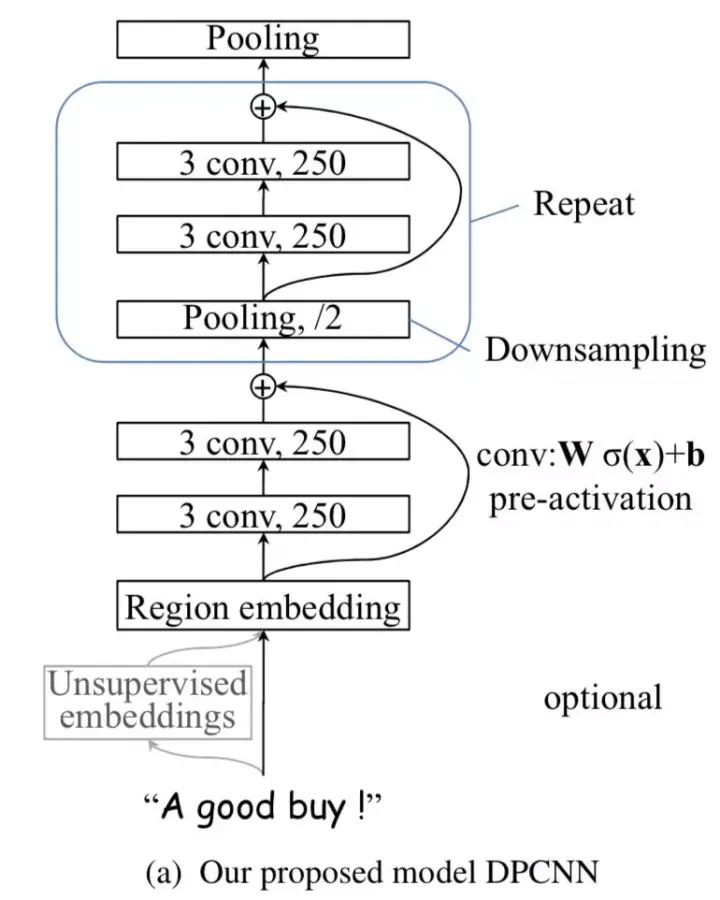
由于前面所述的1/2池化层的存在,文本序列的长度会随着block数量的增加呈指数级减少,即:
n u m b l o c k s = l o g 2 s e q _ l e n num_blocks=log_2seq\_len numblocks=log2seq_len
这导致序列长度随着网络加深呈现金字塔(Pyramid)形状:

因此作者将这种深度定制的简化版ResNet称之为Deep “Pyramid” CNN。
参考
1、从经典文本分类模型TextCNN到深度模型DPCNN:https://zhuanlan.zhihu.com/p/35457093
2、自然语言处理 03:N-gram 语言模型:https://yey.world/2020/03/09/COMP90042-03/
3、知否?知否?一文看懂深度文本分类之DPCNN原理与代码:https://zhuanlan.zhihu.com/p/56189443
4、残差网络这一部分参考了一个视频和一个文章,但是找不到出处了