先看一眼JVM虚拟机运行时的内存模型:

1.方法区 Perm(永久代、非堆)
2.虚拟机栈
3.本地方法栈 (Native方法)
4.堆
5.程序计数器
1 首先的问题是:jvm如何知道那些对象需要回收 ?
目前两种标识算法、三种回收算法、两种清除算法、三种收集器
- 引用计数法
每个对象上都有一个引用计数,对象每被引用一次,引用计数器就+1,对象引用被释放,引用计数器-1,直到对象的引用计数为0,对象就标识可以回收
这个可以用数据算法中的图形表示,对象A-对象B-对象C 都有引用,所以不会被回收,对象B由于没有被引用,没有路径可以达到对象B,对象B的引用计数就就是0,对象B就会被回收。

但是这个算法有明显的缺陷,对于循环引用的情况下,循环引用的对象就不会被回收。例如下图:对象A,对象B 循环引用,没有其他的对象引用A和B,则A和B 都不会被回收。

- root搜索算法
这种算法目前定义了几个root,也就是这几个对象是jvm虚拟机不会被回收的对象,所以这些对象引用的对象都是在使用中的对象,这些对象未使用的对象就是即将要被回收的对象。简单就是说:如果对象能够达到root,就不会被回收,如果对象不能够达到root,就会被回收。
如下图:对象D访问不到根对象,所以就会被回收

以下对象会被认为是root对象:
- 被启动类(bootstrap加载器)加载的类和创建的对象
- jvm运行时方法区类静态变量(static)引用的对象
- jvm运行时方法去常量池引用的对象
- jvm当前运行线程中的虚拟机栈变量表引用的对象
- 本地方法栈中(jni)引用的对象
由于这种算法即使存在互相引用的对象,但如果这两个对象无法访问到根对象,还是会被回收。如下图:对象C和对象D互相引用,但是由于无法访问根,所以会被回收。

jvm在确定是否回收的对象的时候采用的是root搜索算法来实现。
在root搜索算法的里面,我们说的引用这里都指定的是强引用关系。所谓强引用关系,就是通过用new 方式创建的对象,并且显示关联的对象
Object obj = new Object();以上就是代表的是强引用关系,变量obj 强引用了 Object的一个对象。
java里面有四种应用关系,从强到弱分别为:
Strong Reference(强引用) –>Weak Reference (弱引用) -> Soft Reference(软引用) – > Phantom Reference(引用)
Strong Reference : 只有在引用对象root不可达的情况下才会标识为可回收,垃圾回收才可能进行回收
Weak Reference :即使在root算法中 其引用的对象root可达到,但是如果jvm堆内存 不够的时候,还是会被回收。
Soft Reference : 无论其引用的对象是否root可达,在响应内存需要时,由垃圾回收判断是否需要回收。
Phantom Reference :在回收器确定其指示对象可另外回收之后,被加入垃圾回收队列.
-
标记-清除
标记清除的算法最简单,主要是标记出来需要回收的对象,然后然后把这些对象在内存的信息清除。如何标记需要回收的对象,在上一篇文章里面已经有说明。

-
标记-清除-压缩
这个算法是在标记-清除的算法之上进行一下压缩空间,重新移动对象的过程。因为标记清除算法会导致很多的留下来的内存空间碎片,随着碎片的增多,严重影响内存读写的性能,所以在标记-清除之后,会对内存的碎片进行整理。最简单的整理就是把对象压缩到一边,留出另一边的空间。由于压缩空间需要一定的时间,会影响垃圾收集的时间。

-
标记-清除-复制
这个算法是吧内存分配为两个空间,一个空间(A)用来负责装载正常的对象信息,,另外一个内存空间(B)是垃圾回收用的。每次把空间A中存活的对象全部复制到空间B里面,在一次性的把空间A删除。这个算法在效率上比标记-清除-压缩高,但是需要两块空间,对内存要求比较大,内存的利用率比较低。适用于短生存期的对象,持续复制长生存期的对象则导致效率降低

由于现在的处理器都是多核的,处理器的性能得到了极大的提升,所以在此基础上有产生了几种垃圾收集算法。主要包括两种算法
- 并行标记清除
所谓并行,就是原来垃圾回收只是一个线程进行。现在创建多个垃圾回收线程。并行的进行标记和清除。比如把需要标记的对象平均分配到多个线程之后,当标记完成之后,多个线程进行清除。
- 并发标记清除
所谓并发,就是应用程序和垃圾回收可以同时执行。在标记清除算法中,在标记对象和清除对象,以及压缩对象的情况下是需要暂停应用的。那么并行标记清除压缩算法则是在标记清除压缩算法的基础上,把标记清除压缩算法分为以下几个过程
初始标记->并发标记->重新标记->并发清除->重置
以上几种算法是垃圾回收的基本算法,jvm垃圾回收就是在以上几种算法为基础的,在以上几种算法的基础上,java垃圾回收器可以分为以下几种:
- 串行收集器
用单线程处理所有垃圾回收工作,因为无需多线程交互,所以效率比较高。但是,也无法使用多处理器的优势,所以此收集器适合单处理器机器
单线程收集器。在目前多核服务器端运行的情况下,效率比较低。比较适合堆内存小的情况下使用。

- 并行收集器
用多线程处理所有垃圾回收工作,利用多核处理器的优势。但是如果线程数量过多,导致线程之间频繁调度,也会影响性能。一半并行收集的线程是处理器的个数。
“对吞吐量有高要求”,多CPU、对应用响应时间无要求的中、大型应用。举例:后台处理、科学计算。

- 并发收集器
并发收集器主要减少年老代的暂停时间,他在应用不停止的情况下使用独立的垃圾回收线程,跟踪可达对象。在每个年老代垃圾回收周期中,在收集初期并发收集器 会对整个应用进行简短的暂停(初始标记的过程),在收集中还会再暂停一次。第二次暂停会比第一次稍长(重新标记的过程),在此过程中多个线程同时进行垃圾回收工作。
并发收集器使用处理器换来短暂的停顿时间。在一个N个处理器的系统上,并发收集部分使用K/N个可用处理器进行回收,一般情况下1<=K<=N/4。
在只有一个处理器的主机上使用并发收集器,设置为incremental mode模式也可获得较短的停顿时间。
浮动垃圾:由于在应用运行的同时进行垃圾回收,所以有些垃圾可能在垃圾回收进行完成时产生,这样就造成了“Floating Garbage”,这些垃圾需要在下次垃圾回收周期时才能回收掉。所以,并发收集器一般需要20%的预留空间用于这些浮动垃圾。
Concurrent Mode Failure:并发收集器在应用运行时进行收集,所以需要保证堆在垃圾回收的这段时间有足够的空间供程序使用,否则,垃圾回收还未完成,堆空间先满了。这种情况下将会发生“并发模式失败”,此时整个应用将会暂停,进行垃圾回收。
并发收集器,在垃圾回收的时候采用并发标记清除算法的收集器
对响应时间要求高的,多CPU,大型应用。比如页面请求/web服务器。前端业务系统用的比较多。

串行处理器:
--适用情况:数据量比较小(100M左右);单处理器下并且对响应时间无要求的应用。
--缺点:只能用于小型应用
并行处理器:
--适用情况:“对吞吐量有高要求”,多CPU、对应用响应时间无要求的中、大型应用。举例:后台处理、科学计算。
--缺点:垃圾收集过程中应用响应时间可能加长
并发处理器:
--适用情况:“对响应时间有高要求”,多CPU、对应用响应时间有较高要求的中、大型应用。举例:Web服务器/应用服务器、电信交换、集成开发环境。
JDK5.0适用的分代垃圾回收算法
分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。
在Java程序运行的过程中,会产生大量的对象,其中有些对象是与业务信息相关,比如Http请求中的Session对象、线程、Socket连接,这类对象跟业务直接挂钩,因此生命周期比较长。但是还有一些对象,主要是程序运行过程中生成的临时变量,这些对象生命周期会比较短,比如:String对象,由于其不变类的特性,系统会产生大量的这些对象,有些对象甚至只用一次即可回收。
试想,在不进行对象存活时间区分的情况下,每次垃圾回收都是对整个堆空间进行回收,花费时间相对会长,同时,因为每次回收都需要遍历所有存活对象,但实际上,对于生命周期长的对象而言,这种遍历是没有效果的,因为可能进行了很多次遍历,但是他们依旧存在。因此,分代垃圾回收采用分治的思想,进行代的划分,把不同生命周期的对象放在不同代上,不同代上采用最适合它的垃圾回收方式进行回收。
如何分代
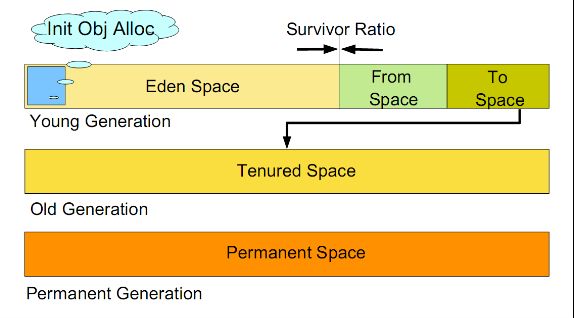
如图所示:
虚拟机中的共划分为三个代:年轻代(Young Generation)、年老点(Old Generation)和持久代(Permanent Generation)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系不大。年轻代和年老代的划分是对垃圾收集影响比较大的。
年轻代:
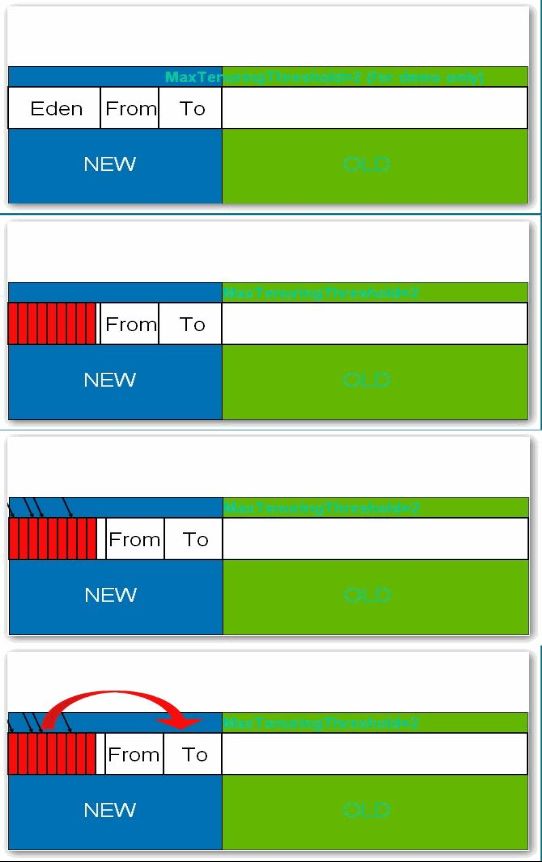
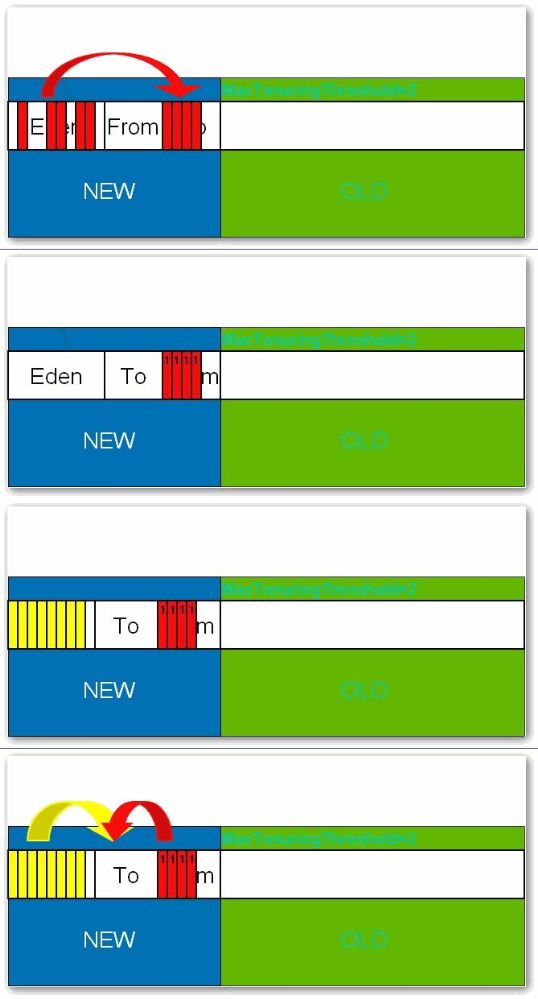
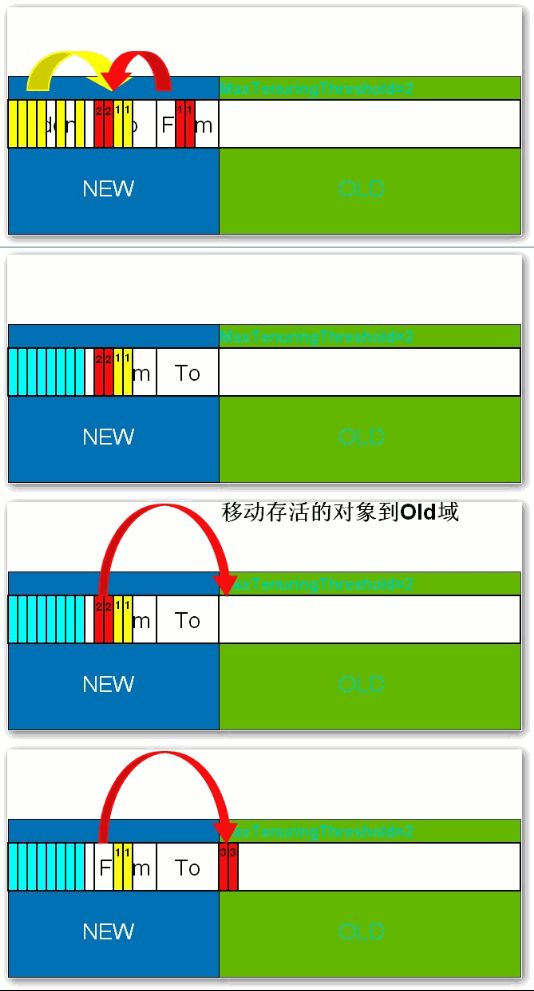
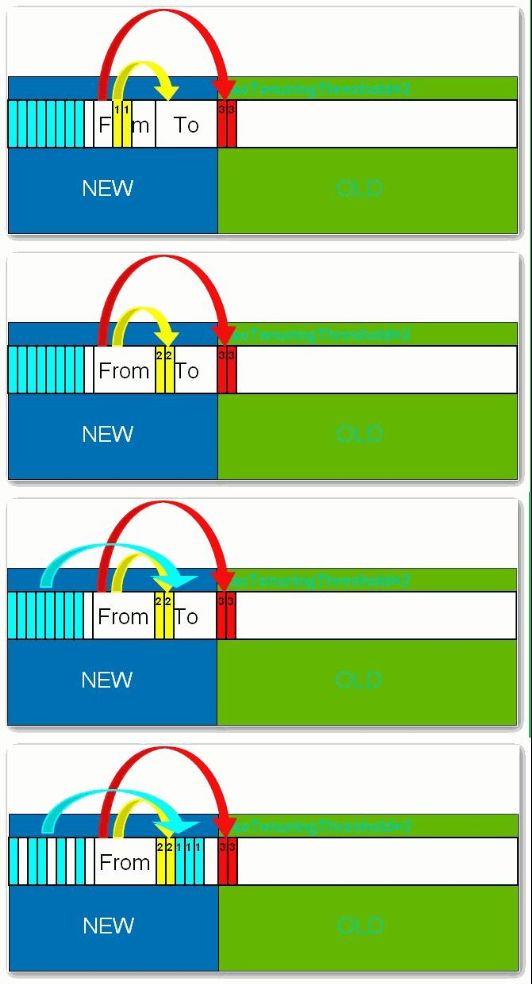
所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来 对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
年老代:
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
持久代:
用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=<N>进行设置。
什么情况下触发垃圾回收
由于对象进行了分代处理,因此垃圾回收区域、时间也不一样。GC有两种类型:Scavenge GC和Full GC。
GC类型
GC有两种类型:Scavenge GC和Full GC。
1. Scavenge GC
一般情况下,当新对象生成,并且在Eden申请空间失败时,就好触发Scavenge GC,堆Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。
2. Full GC
对整个堆进行整理,包括Young、Tenured和Perm。Full GC比Scavenge GC要慢,因此应该尽可能减少Full GC。有如下原因可能导致Full GC:
* Tenured被写满
* Perm域被写满
* System.gc()被显示调用
* 上一次GC之后Heap的各域分配策略动态变化