Day44 Redis集群搭建和Hadoop的安装
目录
集群搭建
1、创建安装目录 在master ,node1 ,node2中分别创建
2、将redis 复制到redis-cluster 目录下修改名字为7000
3、修改配置文件
4、复制7000
5、修改每一个里面的配置
6、在7002 ,7003 复制到node1
7、在7004 ,7005 复制到node2
8、启动redis
9、启动集群 第一次使用 都免集群重启不需要使用
10、客户端访问reids集群
Hadoop安装
基础配置
1、关闭防火墙
2、修改主机名
3.关闭networkmanage服务
4、修改ip地址
5.卸载自带jdk
6.安装jdk
7.映射关系
8.修改启动级别之后重启
9.免密配置
开始安装hadoop
上传hadoop-2.7.6.tar.gz 到module
解压:
配置环境变量:
1.修改slaves 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/slaves
2.修改hadoop-env.sh 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
3.修改core-site.xml 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/core-site.xml
4.修改hdfs-site.xml 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/hdfs-site.xml
5.修改yarn-site.xml 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/yarn-site.xml
6.修改mapred-site.xml
7.hadoop分发到node1和node2
8.启动hadoop
如果安装失败
集群搭建
1、创建安装目录 在master ,node1 ,node2中分别创建
mkdir /usr/local/soft/redis-cluster
2、将redis 复制到redis-cluster 目录下修改名字为7000
复制前删除单机版缓存文件
rm -rf appendonly.aof rm -rf dump.rdb
执行复制操作:
cp -r /usr/local/soft/redis /usr/local/soft/redis-cluster
mv /usr/local/soft/redis-cluster/redis /usr/local/soft/redis-cluster/7000
3、修改配置文件
进入到redis.conf配置文件中,输入命令:
vim /usr/local/soft/redis-cluster/7000/bin/redis.conf
在配置文件中找到以下内容并修改为以下内容:
daemonize yes //redis后台运行
pidfile /var/run/redis_7000.pid //pidfile文件对应7000
port 7000 //端口7000
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes.conf //集群的配置 配置文件首次启动自动生成
cluster-node-timeout 5000 //请求超时 设置5秒够了
appendonly yes //aof日志开启有需要就开启,它会每次写操作都记录一条日志 (全持久化)
4、复制7000
进入到第一步所创建的集群安装目录redis_cluster,输入命令:
cd /usr/local/soft/redis-cluster
在该目录下依次输入以下命令:
cp -r 7000 7001
cp -r 7000 7002
cp -r 7000 7003
cp -r 7000 7004
cp -r 7000 7005
5、修改每一个里面的配置
输入命令:
vim 7001/bin/redis.conf
进入到7001的配置文件中,把里面的7000改为对应的复制的端口号,以下内容为经过修改的配置文件中的内容:
pidfile /var/run/redis_7001.pid
port 7001
注意:这里只举例了一个7001,实际还需要依次进入到剩下的四个中去一一修改,只需将上述命令中的7001更改为要修改的端口号即可
6、在7002 ,7003 复制到node1
依次执行如下内容,将复制的端口号进行分发到另外的第一台虚拟机中
scp -r /usr/local/soft/redis-cluster/7002 node1:/usr/local/soft/redis-cluster/
scp -r /usr/local/soft/redis-cluster/7003 node1:/usr/local/soft/redis-cluster/
7、在7004 ,7005 复制到node2
依次执行如下内容,将复制的端口号进行分发到另外的第二台虚拟机中
scp -r /usr/local/soft/redis-cluster/7004 node2:/usr/local/soft/redis-cluster/
scp -r /usr/local/soft/redis-cluster/7005 node2:/usr/local/soft/redis-cluster/
8、启动redis
分发完成后,在每台虚拟机中执行所分发的redis,master中只启动7000和7001,所分发出去的其他redis不启动,否则就失去了分发的意义
输入以下命令进入到该redis的bin目录下并执行redis:
1、在master中执行
cd /usr/local/soft/redis-cluster/7000/bin(进入目录)
./redis-server redis.conf(执行)
cd /usr/local/soft/redis-cluster/7001/bin
./redis-server redis.conf
2、在node1中执行
cd /usr/local/soft/redis-cluster/7002/bin
./redis-server redis.conf
cd /usr/local/soft/redis-cluster/7003/bin
./redis-server redis.conf
3、在node2中执行
cd /usr/local/soft/redis-cluster/7004/bin
./redis-server redis.conf
cd /usr/local/soft/redis-cluster/7005/bin
./redis-server redis.conf
9、启动集群 第一次使用 都免集群重启不需要使用
redis-cli --cluster create 192.168.92.200:7000 192.168.92.200:7001 192.168.92.210:7002 192.168.92.210:7003 192.168.92.220:7004 192.168.92.220:7005 --cluster-replicas 1
注意:这里的六个IP地址分别为所分发的redis对应的三个虚拟机的IP地址
10、客户端访问reids集群
# -p 端口号
-h 节点ip
-c 自动重定向,在任一一台虚拟机上输入不属于该虚拟机处理的命令,可以不报错,且成功执行,并且会自动重定向到属于某虚拟机上的命令的虚拟机上
访问集群:
redis-cli -p 7000 -h master -c
Hadoop安装
基础配置
1、关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
查看防火墙状态
firewall-cmd --state
systemctl status firewalld.service
启动防火墙
systemctl start firewalld.service
2、修改主机名
第一种
hostnamectl set-hostname 名称
第二种
vim /etc/hostname
查看主机名
hostnamectl status
3.关闭networkmanage服务
systemctl status NetworkManager #查看NetworkManager状态
systemctl stop NetworkManager #停止NetworkManager
systemctl disable NetworkManager#禁止NetworkManager开机启动
4、修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.129.211
NETMASK=255.255.255.0
GATEWAY=192.168.129.2
DNS1=192.168.129.2
5.卸载自带jdk
查看自带jdk
rpm -qa |grep jdk
卸载:
rpm -e 自带jdk名称 --nodeps
一般情况下在查看jdk时可能会什么也不显示,表示没有自带jdk;或者只显示一行,但是这一行不用删除,并不表示自带的jdk
6.安装jdk
上传jdk1.8.0_171到/usr/local/module
解压jdk到soft
cd /usr/local/module
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/soft
配置环境变量
vim /etc/profile
增加
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
7.映射关系
ip地址 主机名
linux配置路径vim /etc/hosts
windows配置路径C:\Windows\System32\drivers\etc\hosts
8.修改启动级别之后重启
systemctl set-default multi-user.target #无界面
克隆两台然后
9.免密配置
ssh-keygen -t rsa 然后三次回车
ssh-copy-id -i 主机名
开始安装hadoop
上传hadoop-2.7.6.tar.gz 到module
该module目录需要自己创建,创建在/usr/local/soft/下
解压:
tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
注意:必须在解压在/usr/local/soft/
配置环境变量:
export HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
PATH中新加$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1.修改slaves 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/slaves
删除原有内容
新加从节点主机名
node1
node2
2.修改hadoop-env.sh 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
删除export JAVA_HOME=${JAVA_HOME}
新加export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
3.修改core-site.xml 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/core-site.xml
在core-site.xml标签configuration中复制一下内容
4.修改hdfs-site.xml 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/hdfs-site.xml
5.修改yarn-site.xml 位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/yarn-site.xml
6.修改mapred-site.xml
位置/usr/local/soft/hadoop-2.7.6/etc/hadoop/mapred-site.xml
该文件该目录下没有,但是该目录下有该文件的模板,所以在修改前需要复制该模板:
cp /usr/local/soft/hadoop-2.7.6/etc/hadoop/mapred-site.xml.template /usr/local/soft/hadoop-2.7.6/etc/hadoop/mapred-site.xml
然后在进入到mapred-site.xml下,修改为如下内容
7.hadoop分发到node1和node2
scp -r /usr/local/soft/hadoop-2.7.6 node1:/usr/local/soft
scp -r /usr/local/soft/hadoop-2.7.6 node2:/usr/local/soft
8.启动hadoop
在master格式化
hdfs namenode -format
start-all.sh
google浏览器输入master:50070
如果安装失败
关闭:stop-all.sh
再次重启的时候
1.需要手动将每个节点的tmp目录删除: 所有节点都要删除
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
然后执行将namenode格式化
2.在主节点执行命令:
hdfs namenode -format
3.启动hadoop
start-all.sh
启动之后,进入到浏览器中输入master:50070会出现如下界面:
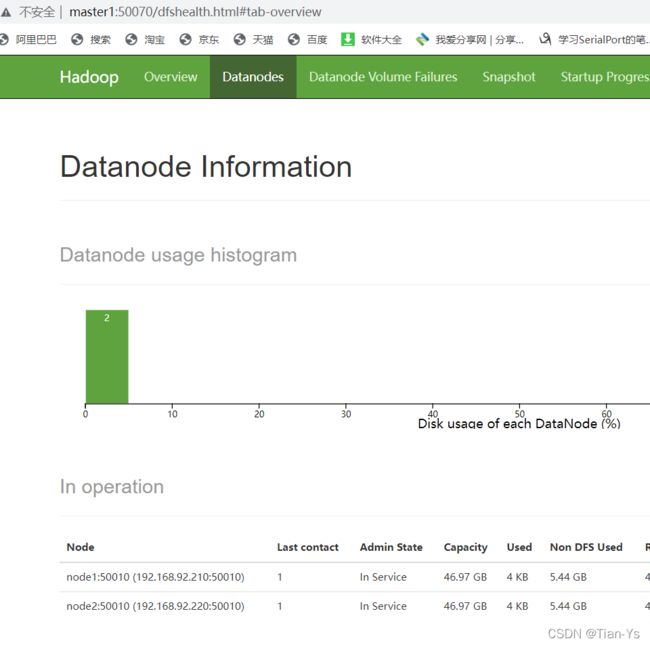
若是在这没有显示该页面,则是Hadoop安装失败,去执行安装失败后的步骤,若是显示了该页面但是其中没有显示node1和node2的相关信息,则说明hadoop安装成功,但是其中的配置文件出错了,可以去检查每一个配置文件,修改其中的错误内容,之后在node1和node2中删除分发后的hadoop,重新分发。之后再重新启动hadoop,重新执行以上步骤。