Day51 HDFS的概述及其操作
目录
HDFS概述
Java连接HDFS
上传文件:
下载文件:
重命名文件:
删除文件:
查看文件信息:
查看文件是否为目录
Hadoop组件介绍
HDFS架构:
Yarn架构:
MapReduce架构:
HDFS的读写流程
HDFS的读流程
HDFS的写流程
数据备份:
机架感知:
NameNode工作流程
DataNode工作流程
HDFS概述
HDFS是一种允许文件通过网络在多台主机上分享的文件系统,可让多台机器上的多用户分享文件和存储空间
通透性:让实际上是通过网络来访问文件的动作,由程序和用户看起来就像是访问本地的磁盘一样
容错:即使系统中有某些节点宕机,整体来说系统仍然可以持续运作而不会有数据损失(通过副本机制实现)
HDFS是众多分布式文件管理系统中的一种,不适用于小文件
Java连接HDFS
在使用IDEA连接hdfs之前,需要将虚拟机中的Hadoop启动
使用IDEA创建一个maven项目,在其中导入依赖
首先需要导入Hadoop客户端依赖,版本与Hadoop版本一致
在所创建的maven项目中的pom.xml中添加依赖,刷新maven让其下载依赖:
org.apache.hadoop
hadoop-client
2.7.6
新建一个Java文件,创建一个hdfs的配置文件,这里应当选择刚刚所导入依赖的配置文件
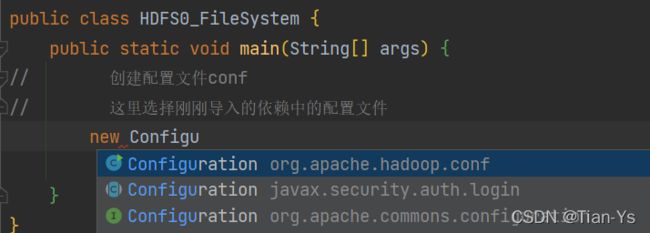
第一种连接方式:传入所要连接的hdfs的uri和配置文件,使用FileSystem.get方法获取连接
FileSystem进入到源码中查看发现是一个抽象类,所以可以查找他的具体实体类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.net.URI;
public class HDFS0_FileSystem {
public static void main(String[] args) throws Exception{
// 创建配置文件conf
// 这里选择刚刚导入的依赖中的配置文件
Configuration conf = new Configuration();
// 创建连接hdfs的URI,同时抛出异常
URI uri = new URI("hdfs://master:9000");
// 使用FileSystem.get连接hdfs,传入配置文件和uri
FileSystem fs = FileSystem.get(uri, conf,"root");
System.out.println(fs.getClass().getName());
}
}这里uri的获取可以进入到/usr/local/soft/hadoop-2.7.6/etc/hadoop文件夹下的配置文件core-site.xml中查看

结果:

该实体类为DistributedFileSystem
第二种连接方式:直接使用配置文件的set方法配置所要连接的Hadoop的相关参数
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class HDFS0_FileSystem2 {
public static void main(String[] args) throws Exception{
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS","hdfs://master:9000");
// 获取连接
FileSystem fs = FileSystem.get(conf);
}
}这样也可以实现连接hdfs
这里的set中的两个参数正是上述core-site.xml中的两个参数
上传文件:
将本地文件上传到Hadoop中
可以使用copyFromLocalFile方法实现上传文件到hdfs,该方法中需要传入四个参数:
delSrc – 是否强制删除src元数据 boolean类型
overwrite:是否覆盖已存在的文件 boolean类型
src – path:需要上传的本地文件路径,类型为Path对象类型
dst – path:所要上传到的hdfs上的文件路径,类型为Path对象类型
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFS1_UpFile {
public static void main(String[] args) throws Exception{
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS","hdfs://master:9000");
// 获取连接
FileSystem fs = FileSystem.get(conf);
// 上传文件
fs.copyFromLocalFile(false,true,new Path("D:\\IdeaProjects\\HadoopCode\\data\\sanguo.txt"),new Path("/sanguo/"));
// 关闭连接
fs.close();
// 加入一个完成上传的提示
System.out.println("application is finished");
}
}结果:
 在hdfs中查看结果:hdfs中的sanguo目录下多了一个sanguo.txt文件
在hdfs中查看结果:hdfs中的sanguo目录下多了一个sanguo.txt文件

想要在上传时设置文件的副本数操作,只需将hadoop中的hdfs-site.xml文件下载,导入到IDEA的resources目录下,将该文件中的副本数更改后,在运行上传操作时会自动访问resources目录下的该文件,然后其副本数就更改为了所设置的副本数。
这里已经导入了hdfs-site.xml并且更改了内容副本数为2
可以通过set方法去配置设置相关配置文件中的副本数,将副本数设置为1并上传
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFS1_UpFile2 {
public static void main(String[] args) throws Exception{
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS","hdfs://master:9000");
// 设置副本数为1
conf.set("dfs.replication","1");
// 获取连接
FileSystem fs = FileSystem.get(conf);
// 上传文件
fs.copyFromLocalFile(false,true,new Path("D:\\IdeaProjects\\HadoopCode\\data\\sanguo.txt"),new Path("/sanguo/sanguo2.txt"));
// 关闭连接
fs.close();
// 加入一个完成上传的提示
System.out.println("application is finished");
}
}
结果:

副本配置顺序:
Hadoop集群自定义配置文件
下载文件:
下载文件操作同上传相似,只需要使用copyToLocalFile方法即可:
该方法的参数也有四个:
delSrc – 是否强制删除src元数据 boolean类型
src :所要下载的hdfs上的文件的路径
dst – path:本地存放的下载文件的路径
useRawLocalFileSystem:是否将RawLocalFileSystem用作本地文件系统,一般情况下选择true
这里注意:若是不加最后一个参数,也可以实现下载文件,但大部分可能会报错,同时下载完成的文件中没有内容。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFS3_DownFile {
public static void main(String[] args) throws Exception{
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS","hdfs://master:9000");
// 设置副本数为2
conf.set("dfs.replication","2");
// 获取连接
FileSystem fs = FileSystem.get(conf);
// 下载文件
fs.copyToLocalFile(false,new Path("/sanguo/sanguo2.txt"),new Path("D:\\IdeaProjects\\HadoopCode\\data"),true);
// 关闭连接
fs.close();
// 提示
System.out.println("application is Download");
}
}结果:

在该项目下会多一个文件:

重命名文件:
重命名文件操作中含有两个参数:
src — path:即将被重命名的文件路径
drt — path:重命名后的文件名及路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFS4_ReNameFile {
public static void main(String[] args) throws Exception{
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS","hdfs://master:9000");
// 设置副本数为2
conf.set("dfs.replication","2");
// 获取连接
FileSystem fs = FileSystem.get(conf);
// 重命名文件
fs.rename(new Path("/sanguo/sanguo2.txt"),new Path("/sanguo/sanguo3.txt"));
// 关闭连接
fs.close();
// 提示
System.out.println("application is Renamed");
}
}结果:
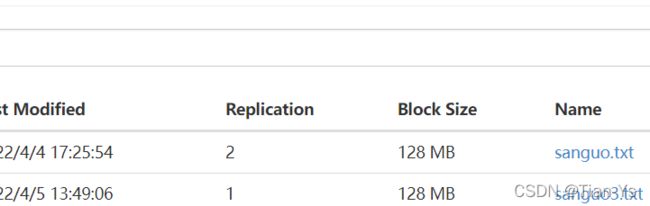
 在hdfs中查看结果:
在hdfs中查看结果:
删除文件:
删除文件操作提供一个delete方法来进行删除,有两个参数:
Path f:所要删除的文件的路径
boolean recursive:如果被删除的文件是一个目录,则为ture,否则为false,若不为一个目录但仍然写true会报错。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFS5_DeleteFile {
public static void main(String[] args) throws Exception{
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS","hdfs://master:9000");
// 设置副本数为2
conf.set("dfs.replication","2");
// 获取连接
FileSystem fs = FileSystem.get(conf);
// 删除文件
fs.delete(new Path("/sanguo/sanguo3.txt"),false);
// 关闭连接
fs.close();
// 提示
System.out.println("application is Deleted");
}
}结果:
在HDFS中查看:

查看文件信息:
查看文件信息提供了一个listFiles方法,该方法有两个参数:
Path f:所要查看的文件/目录路径
boolean recursive:是否递归目录,是为true,否为false
该方法不同于前面,该方法返回值为RemoteIterator迭代器类型
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
public class HDFS6_FileStatus {
public static void main(String[] args) throws Exception {
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS", "hdfs://master:9000");
// 设置副本数为2
conf.set("dfs.replication", "2");
// 获取连接
FileSystem fs = FileSystem.get(conf);
// 查看文件
RemoteIterator files = fs.listFiles(new Path("/input"), true);
while (files.hasNext()) {
LocatedFileStatus locatedFileStatus = files.next();
// 获取每个块的位置信息
BlockLocation[] blocks = locatedFileStatus.getBlockLocations();
// 获取block块的大小
System.out.println("块大小:"+locatedFileStatus.getBlockSize());
// 获取路径
System.out.println("块路径:"+locatedFileStatus.getPath());
// 获取用户组
System.out.println("块用户组:"+locatedFileStatus.getGroup());
// 获取所有者
System.out.println("块所有者:"+locatedFileStatus.getOwner());
for (BlockLocation block : blocks) {
System.out.println("hosts:" + block.getHosts());
System.out.println("name:" + block.getNames());
System.out.println("length:" + block.getLength());
}
}
// 关闭连接
fs.close();
// 提示
System.out.println("application is Success");
}
} 结果:

查看文件是否为目录
查看文件是否为目录提供一个fileStatus方法查看
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFS7_isFile {
public static void main(String[] args) throws Exception{
// 创建配置文件
Configuration conf = new Configuration();
// 设置所要连接的hdfs的参数
conf.set("fs.defaultFS","hdfs://master:9000");
// 设置副本数为2
conf.set("dfs.replication","2");
// 获取连接
FileSystem fs = FileSystem.get(conf);
// 查看文件是否为目录
FileStatus[] fileStatuses = fs.listStatus(new Path("/input"));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.isFile());
System.out.println(fileStatus.isDirectory());
}
// 关闭连接
fs.close();
// 提示
System.out.println("application is Deleted");
}
}
结果:将该目录下的文件全部遍历判断

Hadoop组件介绍
目前Hadoop包含三大组件:
HDFS:一个分布式存储框架,适合海量数据的存储
mapreduce:一个分布式计算框架,适合海量数据的计算
yarn:一个资源调度平台,负责给计算框架分配计算资源
HDFS架构:
HDFS具有主从架构
如图所示:
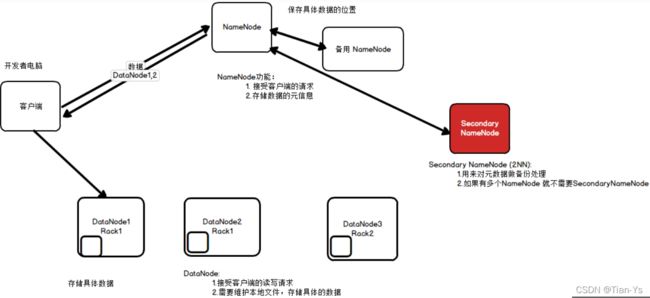
NameNode:主节点,用于接收客户的请求;存储数据的元信息,即存储数据的具体存放位置
DataNode:从节点,用于接收客户端的读写请求;需要维护本地文件,存储具体的数据
Rank:机架,为了保证数据的可靠性,将数据放在不同的机架上,当某一个机架发生问题时,有另外的一个机架可以继续工作
SecondaryNameNode:备用NameNode,同样为了保证数据的可靠性;用来对元数据进行备份处理,若是有多个NameNode,则不需要SercondaryNameNode
中心式架构:将多个数据划分为一个个文件块存储
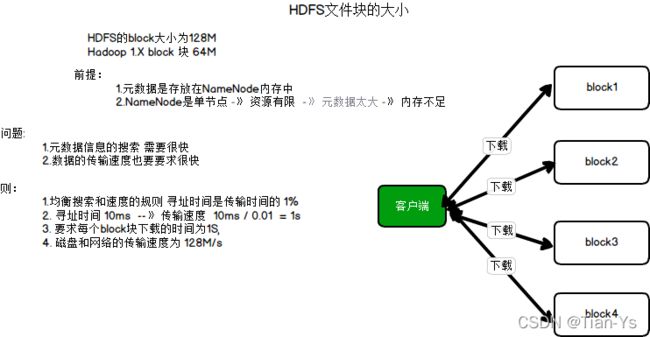
HDFS文件块block的大小:128M,在Hadoop1.X版本中每一个block块的大小为64M。
HDFS文件块的大小:
Yarn架构:
Yarn的主从架构:
如图所示:
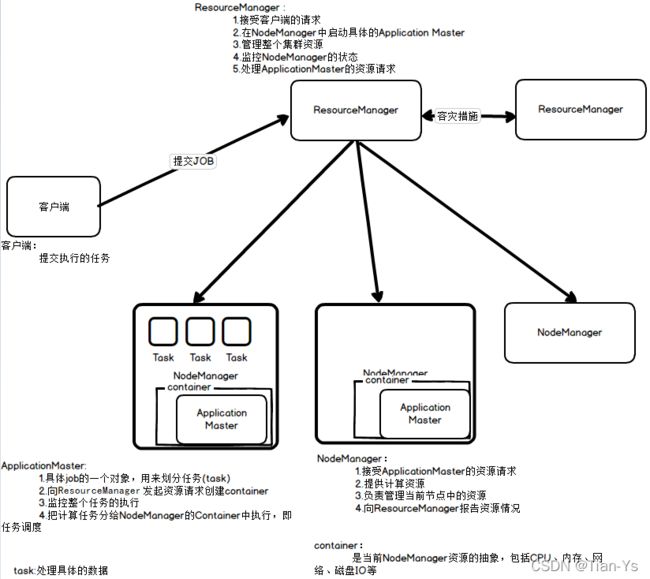
架构流程:
客户端:提交执行的任务
ResourceManager:主节点
1、接收客户端请求;
2、在NodeManager中启动具体的ApplicationMaster;
当没有任务时:3、管理整个集群的资源;4、监控NodeManager的状态
ApplicationMaster:
1、是一个具体Job的一个对象,用来划分任务(task);
2、向ResourceManager请求资源创建container;
3、监控整个任务的执行
container:是当前NodeManager资源的抽象,包括CPU,内存,网络,磁盘IO等
NodeManager:从节点
1、接收ApplicationMaster的资源请求;2、提供计算资源
当没有任务时:3、负责管理当前节点中的资源;4、向ResourceManager报告资源情况
MapReduce架构:
MapReduce分为Map阶段和Reduce阶段
如图所示:
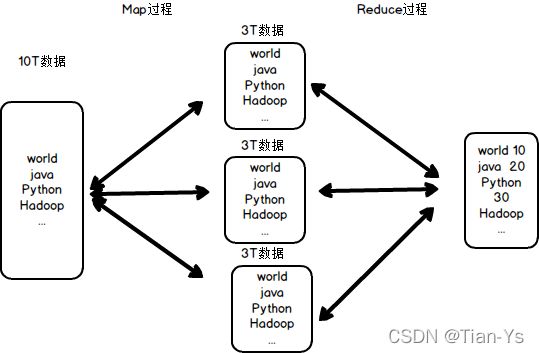
Map阶段:对数据进行切分成多个节点的阶段
Reduce阶段:每个节点计算其自身的内容,计算之后,对数据进行汇总的阶段
MapReduce的主从架构中,主节点为MapReduceApplicationMaster,该节点在集群启动时看不见,只有在提交jar包时才能看见;从节点为具体的task。
MapReduceMaster:即yarn架构中的ApplicationMaster,1、接收客户端提交的计算任务;2、把计算任务分给NodeManager的Container中执行,即任务调度
HDFS的读写流程
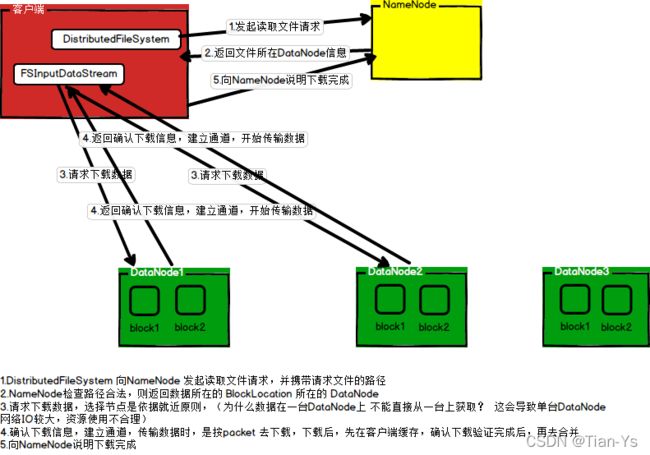
HDFS的读流程
如图所示为hdfs的读流程:
HDFS的写流程
如图为hdfs的写流程:
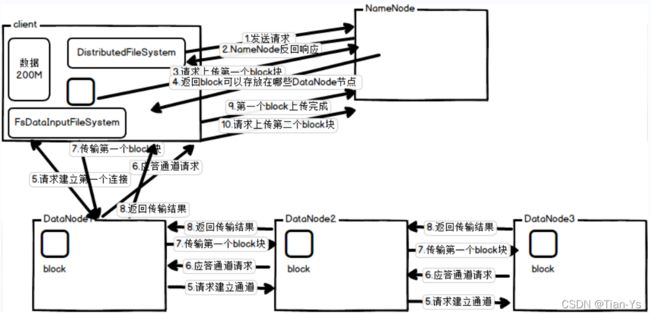
写流程的具体注解:

NameNode返回DataNode的策略:
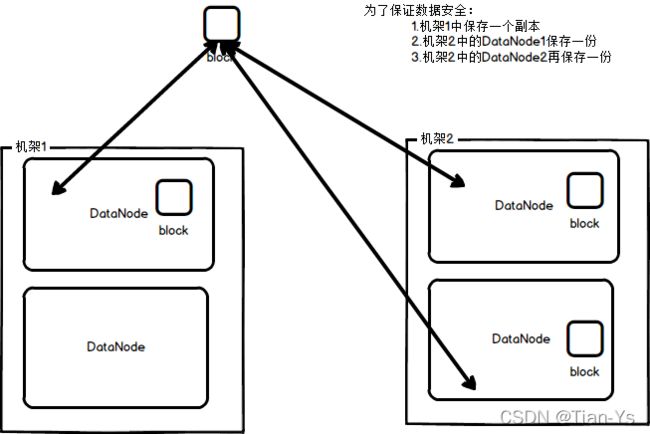
数据备份:
数据备份如图:
机架感知:
机架感知如图:

NameNode工作流程
NameNode的工作流程及具体问题:
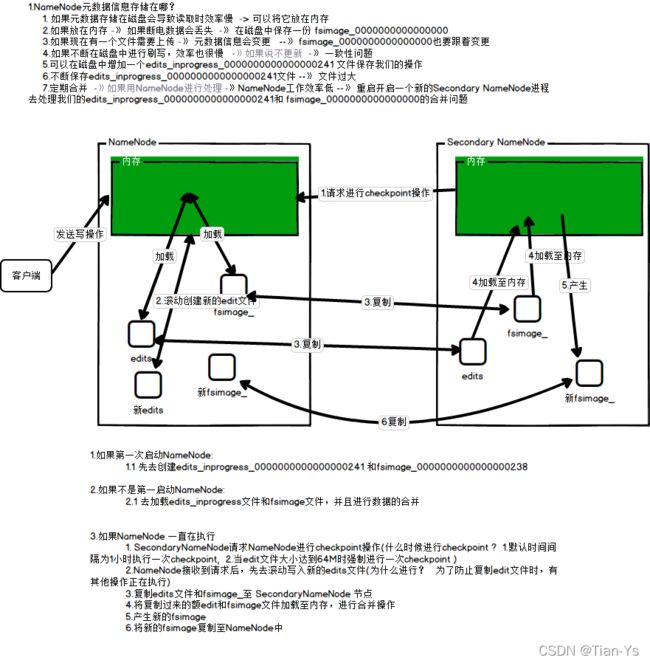
DataNode工作流程
DataNode工作流程如图:
