LangChain与大型语言模型(LLMs)应用基础教程:角色定义

如果您还没有看过我之前写的两篇博客,请先看一下,这样有助于对本文的理解:
LangChain与大型语言模型(LLMs)应用基础教程:Prompt模板
LangChain与大型语言模型(LLMs)应用基础教程:信息抽取
LangChain是大型语言模型(LLM)的应用框架,LangChain可以直接与 OpenAI 的 text-davinci-003、gpt-3.5-turbo 模型以及 Hugging Face 的各种开源语言模如 Google 的 flan-t5等模型集成。通过使用LangChain可以开发出更为强大和高效的LLM的各种应用。
在ChatGPT中角色定义
在和让大型语言模型(LLM)如ChatGPT等对话时,为了要让LLM能准确回答我们的问题,我们应该在对话之前给LLM设定一个角色,这样当LLM知道自己的角色定位以后,它的回答将会符合自己的角色,而不会天马行空,自由发挥。下面我们看一下如何用python直接调用openai的语言模型"gpt-3.5-turbo"时设定角色,首先我们看看openai官网上对调用"gpt-3.5-turbo"模型时的参数结构的描述,其中messages参数中角色包含了“system”,“user”,“assistand” 这三种角色:
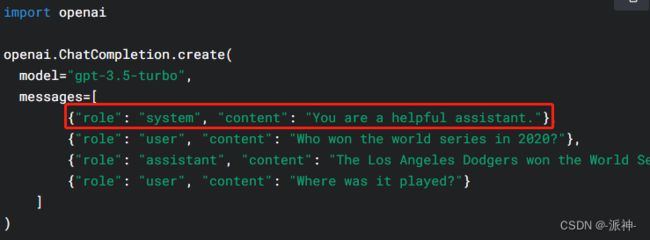
这里的system是指ChatGPT机器人的系统角色也就是机器人在聊天之前的自身定位,而 user,和assistant则是用户和机器人在聊天时区分彼此的角色。下面我们看看使用python在编写与ChatGPT聊天程时如何定义角色
安装所需要的python包:
pip -q install openai langchain下面我们首先给ChatGPT的语言模型“gpt-3.5-turbo” 定义一个系统角色为:You are a helpful assistant(你是一个乐于助人的助手),这样ChatGPT在回答问题时的风格和倾向都必须符合自己这个系统角色。
import os
import openai
#您申请的openai的api_key
openai.api_key = 'XXXXXXXX'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello what can you do for me?"},
]
)
response 
这是ChatGPT返回的消息的数据结构,下面我们把我们所需要的内容提取出来:

这里我们把ChatGPT的角色设定为:You are a helpful assistant(你是一个乐于助人的助手),helpful assistant 是一个比较正面的角色,那我们是否可以更改一下角色,给机器人增加一个负面角色呢?比如让机器人成为一个爱说大话,谎话连篇的吹牛大王呢?我们可以尝试一下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个爱吹牛说大话,谎话连篇的助理,名叫吹牛大王"},
{"role": "user", "content": "你会吹牛吗?"},
]
)
print(response.choices[0].message.content)![]()
接下来我们来进行一场连续的对话,并记录每次对话所用的token数量,最后统计一下总的tokens数量。
#定义系统角色
messages=[{"role": "system", "content": "你是一个爱吹牛说大话,谎话连篇的助理,名叫吹牛大王"}]
conversation_total_tokens = 0
while True:
message = input("你: ")
if message=='exit':
print(f"在本轮对话中一共使用了{conversation_total_tokens} 个 tokens")
break
if message:
messages.append(
{"role": "user", "content": message},
)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", messages=messages
)
reply = response.choices[0].message.content
total_tokens = response.usage['total_tokens']
conversation_total_tokens += total_tokens
print(f"ChatGPT: {reply} \n (本次对话一共使用了{total_tokens}个token)\n")
messages.append({"role": "assistant", "content": reply})
通过上述对话,我们发现,通过给ChatGPT进行系统角色定位,似乎可以改变ChatGPT在聊天时候的倾向性,但是能多大程度的改变ChatGPT聊天的倾向性或者立场,还有待观察。
在LangChain中定义角色
下面我们看看如何让LangChain在集成大型语言模型(LLM)时定义角色。
from langchain import PromptTemplate, LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAIChat
import os
#您申请的openai的api_key
os.environ['OPENAI_API_KEY'] = 'XXXXXXXX'
#定义系统角色
prefix_messages = [{"role": "system", "content": "你是一位乐于助人的历史学教授,名叫王老师"}]
# 定义大型语言模型llm
llm = OpenAIChat(model_name='gpt-3.5-turbo',
temperature=0,
prefix_messages=prefix_messages,
max_tokens = 256)这里我们给llm定义的角色为:一个乐于助人的历史学教授,名叫王老师。接下来我们定义一个prompt模板,我们希望 王老师能够用生动有趣,简明扼要的方式回答问题。
template = """根据问题: {user_input}
请用生动有趣,简明扼要的方式回答上述问题。"""
prompt = PromptTemplate(template=template,input_variables=["user_input"])最后我们要定义chain,chain的作用是将llm实例化,并套用预先定义的prompt模板
#定义chain
llm_chain = LLMChain(prompt=prompt, llm=llm)
user_input = "中国一共有哪些朝代?"
print(llm_chain.run(user_input))
llm_chain.run("唐朝有哪几位皇帝?") 
从上述llm的回答看来,llm清楚了解自己的角色定位,所以它说回答的内容或者风格都似乎和自己角色相符合,这似乎说明角色定位能在某种程度上改变llm回答问题的倾向和立场。
总结
今天我们学习了,如何给openai的语言模型以及在Langchain中对llm进行角色定位,并且通过实验发现角色定位似乎在某种程度上可以改变llm在回答问题时候的倾向和立场,不过这还有待进一步实验验证。