论文阅读 - Segment Anything
文章目录
- 0 前言
- 1 预备知识
-
- 1.1 深度学习训练框架
- 1.2 语义分割训练框架
- 2 SAM的任务
- 3 SAM的模型
-
- 3.1 模型整体结构
- 3.2 Image encoder
- 3.3 Prompt encoder
- 3.4 Mask decoder
- 3.5 训练细节
- 4 SAM的数据
-
- 4.1 模型辅助的手动标注阶段
- 4.2 半自动阶段
- 4.3 全自动阶段
- 5 SAM的应用
-
- 5.1 拿来主义
- 5.2 三个阶段
- 参考资料
0 前言
Meta推出的Segment Anything开源之后,一下成为了CV界的网红。本文是对Segment Anything这篇论文的精读,其中会有一些个人的见解。
为了让更多人了解到SAM的重要意义,本文会尽量写的白话一些,让非深度学习工作者也能知道SAM的工作原理。
1 预备知识
这部分写给非深度学习工作者。
1.1 深度学习训练框架
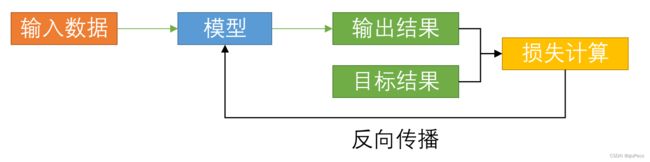
几乎所有的深度学习模型,都逃不出下图1-1所示的框架。我们输入数据,经过模型,得到输出结果。如果是推理阶段,到这里就结束了,也就是绿色箭头的部分。如果是训练阶段,还需要走完黑色箭头的部分,即输出结果会与目标结果计算损失,这个损失会产生梯度,梯度经过反向传播可以更新模型中的参数,如此不断往复,直到模型可以输出我们期望的结果。
注意,这里的目标结果,大部分情况下,都是人工标注的结果。
1.2 语义分割训练框架
这里我们来举一个对纸箱边缘进行语义分割的例子,如图1-2所示。语义分割就是对图片中的每个像素点,进行分类。在这里,是边缘的像素点为白色,非边缘的像素点,为黑色。输入数据变成了 1024 × 1024 × 3 1024 \times 1024 \times 3 1024×1024×3的图片,模型我们这里假设用了HRNet,输出结果就是模型预测出来的边缘,目标结果是人工标注的边缘,损失计算使用了BCE Loss。
可以看出预测的边缘比人工标注的边缘更粗一些,这个差异就产生了损失,于是就能更新模型了。随着模型参数的更新,模型的预测结果会越来越趋近于目标结果,损失也会越来越小,最终收敛。

整个过程中,人需要提供的只有输入数据和目标结果两个部分。根据人提供的数据,模型不断调整自身参数的过程,就是大众口中的“学习”的过程。
除了语义分割之外,其他任务也都是同样的套路。下面我们来看看,SAM是如何对这个训练框架做修改的。
2 SAM的任务
SAM将任务定义为了可提示分割任务,如图2-1所示。为了表示方便,图2-1只画出了推理部分,也就是图1-1中的绿色箭头部分。损失计算和反向传播的方式与其他任务套路一致,这里就不画出来了。
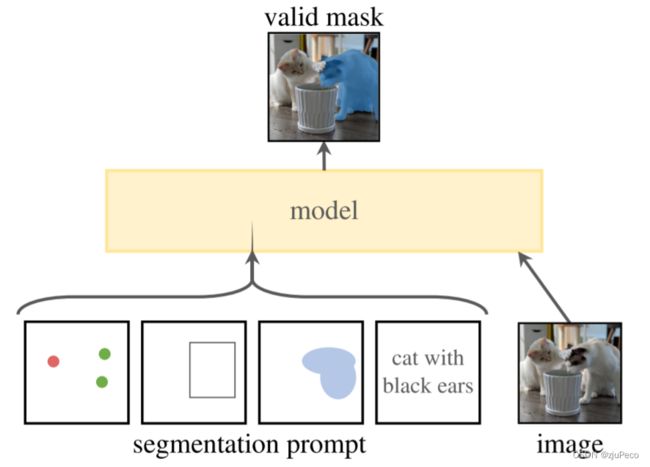
什么是可提示的分割任务?它和语义分割任务的区别在于,它的输入数据多了segmentation prompt这个东西,输出结果只输出prompt对应的mask。语义分割是需要将图片中所有对应类别的内容都分割出来的,比如要分割猫,那么所有的猫都会被分割出来。
prompt就是人对期望模型输出内容的一种提示,SAM支持的prompt包括稀疏提示和稠密提示两大类,稀疏提示包括点(前景点和背景点)、框和文本,稠密提示指的就是掩码,如下图2-2所示。
点可以告诉SAM我想显示这块区域(前景点),不想显示那块区域(背景点),操作简洁,是最为推荐,也是被使用最为频繁的一种点。
框只能告诉SAM我想显示的内容在这块区域内部,没有不想显示的能力。
文本可以随意描述,但也需要描述成模型可以理解的内容,不是SAM的重点,只是一个拓展功能。
掩码是点的稠密版本,训练时会用到,推理时还是以点为主。

通过提示得到模型的输出会带来一个必然的问题——歧义性。如下图2-3所示,1个提示点,既可以表示整头鸵鸟,也可以表示鸵鸟的身体,也可以表示鸵鸟的头。当有2个提示点时,这种歧义性就会减少,比如在身体上点了1个背景点,那这2个点就告诉SAM要输出鸵鸟头的mask。
所以,当输入的提示点只有1个时,SAM输出3个mask,我们可以使用置信度最高的那个mask;当输入的提示点大于1个时,SAM只输出1个mask。
当输入的提示点只有1个时,为什么输出3个mask,不是4个,不是5个?这是作者进行了大量实验来确定最佳的输出mask数量。他们发现,生成3个mask可以很好地处理歧义性问题(整体、部分和子部分),并且可以在保持高精度的同时保持较快的推理速度。也就是说,这是一个可以调节的超参数。

SAM使用这种提示的方式来训练模型有一个很大的好处,就是不需要对全图进行完整的标注,理论上,每张图片只需要标注出一个mask,就可以开始训练了。这个小小的区别,却大大减轻了标注的负担,为后面构建数据引擎提供了极大的便利。
这里我们来思考一下,语义分割模型,也用这种每张图片只标注一个mask的方式,然后在计算loss时,不计算非mask区域的loss不就行了吗?不行!这样就没有负样本了。
我认为这也就是没有通用的语义分割模型出现的原因之一,这条路,目前看来,只有可提示的方式是行得通的。
3 SAM的模型
3.1 模型整体结构
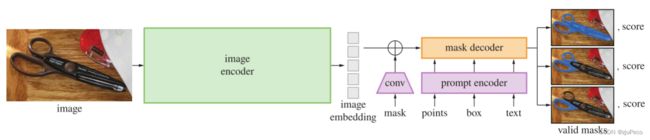
SAM的模型结构还是没有逃出encoder-decoder的框架,这也是目前几乎所有语义分割在使用的框架,如下图3-1所示。image和valid masks中间夹着的这部分,就是把图2-1中的model展开的结果。图像先经过一个非常重的image encoder得到了image embedding,这个embedding也可以叫做image representation,就是这张图片被表示为了一个特征向量image embedding;然后人可能是输入不同的提示,也就是图3-1中的mask,points,box和text,稠密提示mask会经过卷积进行编码,稀疏提示会经过专门设计的prompt encoder进行编码,这样一来,prompt会得到prompt embedding;mask embedding会直接作用在image embedding上,可以认为就是选中了图像中的某一块区域;最终,image embedding会和prompt embedding的一起输入mask decoder,输出最终的3张mask图片。
3.2 Image encoder
Image encoder使用VIT的图像编码器,并使用MAE的预训练权重,image encoder在某张图的推理过程中只会运行一次,image embedding在后续过程中会被反复使用。SAM中,图片的输入为 1 × 3 × 1024 × 1024 1\times3\times1024\times1024 1×3×1024×1024,那么image encoder的输出就是 1 × 256 × 64 × 64 1\times256\times64\times64 1×256×64×64。
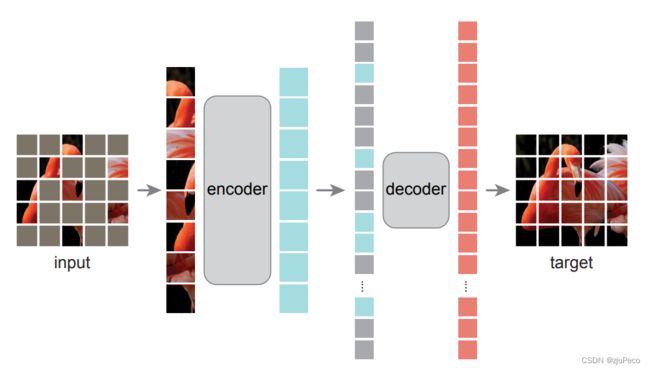
这边SAM就是拿来主义,直接拿的MAE。这里稍微讲一下MAE是什么。MAE也是Meta公司的,是何恺明大佬的作品,整个网络的核心思想是,借鉴NLP中学习word embedding的方法,把图片当做是一个sentence,然后随机遮挡住其中的一部分内容,输入网络,让网络还原出被遮挡的内容。通过这种重建的方式,让encoder有一个好的图像编码能力,能输出好的图片特征表示。
这是一个很重的image encoder,这里应该有很大的改进空间。不过SAM的重点并不在设计网络结构上,所以这里直接拿来就可以了。拿的时候,只拿了encoder部分,decoder部分是不要的。
3.3 Prompt encoder
Prompt encoder中考虑了两种提示,即稀疏提示(如points,boxes,text)和稠密提示(masks)。
稀疏提示中,points和box使用位置编码,并将points或box的编码和可学习的embedding相加,如一个点的位置编码则与表示前景和背景的embeding相加,一个box的左上角角点位置编码与表示左上角的embedding相加,右上角同理,text使用现成的文本图像对齐编码器CLIP编码。稀疏提示会被映射到256维的大小。
稠密提示中,mask通过卷积映射到image embedding相同的维度,并和image embdding相加,如果没有mask提示,则使用一个可学习的表示“no mask”的embedding和image embdding相加。
3.4 Mask decoder
Mask decoder受transformer分割模型启发,在prompt embedding中加入可学习的output tokens,只使用了两个decoder layers。每层decoder中包括self-attention和双向的cross-attention,既会将token作为query去计算和image的注意力去更新token,也会将image embdding作为query去计算和token的注意力并去更新image embedding。
在第二层decoder中会将第一层更新的token重新加上prompt token,并和更新的image embeding计算注意力。计算完两次decoder后,用更新的token再次计算和更新的image embdding计算注意力,并将输出传递给3层的MLP,同时image embedding使用两个转置卷积上采样4倍(与图像原始尺寸比相当于只下采样了4倍),然后将MLP的输出和image embedding相乘。
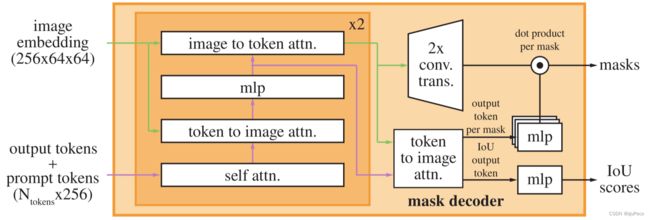
这里的output tokens共有4个,前3个分别对应于输入1个提示点时的3个mask输出(整体、部分和子部分),最后1个表示输入的不止1个提示点,此时只输出这第4个output token对应的mask。当模型接收到多个提示时,它将生成3个mask,并且这些mask通常会非常相似。为了避免在训练期间计算退化损失并确保单个明确的掩码接收到正则化梯度信号,当给出多个提示时,我们只预测一个单一的掩码。这是通过添加第4个output token来实现的,它用于生成额外的mask。
退化损失是SAM中一种用于训练模型的损失函数。它的作用是确保模型在生成mask时不会过度依赖提示,而是能够从输入图像中学习到更多的信息。具体来说,在训练期间,SAM模型会接收到1个输入图像和1个提示,并生成1个或多个mask。然后,这些mask将与真实mask进行比较,并计算IoU分数。如果IoU分数低于某个阈值,则会计算退化损失,并将其添加到总损失中。这样可以鼓励模型在生成mask时更加准确和鲁棒,并避免过度依赖提示。
这里还需要注意的是,实际情况下,SAM的输出不光光只有masks,还有IoU scores。IoU scores用于对生成的多个mask进行排序,并选择最佳的掩码。具体来说,当模型生成多个掩码时,每个掩码都会与真实mask计算IoU scores。然后,这些分数被用来对生成的掩码进行排序,并选择IoU分数最高的掩码作为最终输出。这种方法可以确保输出的掩码与真实目标之间有很高的重叠度,从而提高模型的准确性和鲁棒性。
3.5 训练细节
训练时,每个mask在11轮中随机采样提示来模拟交互式设置,且每次会计算真实mask和每一个mask的损失,但仅使用最低的损失反向传播。就是说,有了真实的mask,这个mask对应的提示我们是可以随机构造的,每个mask会随机构造11种提示来进行训练。
SAM模型使用的损失函数是由Focal Loss和Dice Loss的线性组合。Focal Loss是一种用于解决类别不平衡问题的损失函数,它可以使模型更加关注难以分类的样本。Dice Loss是一种用于图像分割任务的损失函数,它可以衡量模型预测mask与真实mask之间的重叠程度。在SAM模型中,这两种损失函数被结合在一起,以平衡分类和分割任务之间的权衡。
4 SAM的数据
4.1 模型辅助的手动标注阶段
第一个阶段类似于交互式分割,首先用公开数据集训练SAM,然后预标注一些目标,由专业的标注人员通过浏览器的交互式分割工具,单击前景或背景来矫正mask,跳过需要花30秒以上时间标注的标签。
虽然鼓励对标签进行命名和描述,但最终并未使用这类信息。标注矫正后,只使用新标注的mask对SAM重新训练,随着数据的增多,Image encoder也从 VIT-B换到VIT-H。
模型一共反复训练了6遍。最终平均每张图片的mask从20个增加到了44个。
第一阶段大概标注12万张图片,430万个mask。
第一阶段可以认为是对已有类别的修正。
4.2 半自动阶段
第二阶段为了增加mask的多样性,先通过一阶段训练的模型自动预测其余未标注的图片并生成mask,然后由标注者标注图片中剩余未标注的目标。
只用新mask又训练了5次,标注时间恢复到34秒,因为剩余未标注目标基本是一些标注困难的mask。
第二阶段增加了18万张图,590万个mask。
第二阶段可以认为是对未知类别的补充。
4.3 全自动阶段
第三阶段使用第二阶段的数据训练的SAM模型来完成自动标注,数据集自动标注生成包括以下过程:
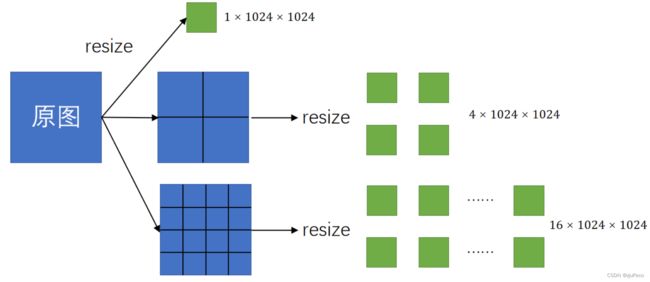
(1)Cropping
对整张图使用 32 × 32 32\times32 32×32的网格点作为prompt,并分别重叠滑窗获得 2 × 2 2\times2 2×2( 16 × 16 16\times16 16×16的网格点作为提示)和 4 × 4 4\times4 4×4( 8 × 8 8\times8 8×8的网格点作为提示)大小的crop图。每个点均会返回子部分,部分和整体的分割结果。将这些结果进行NMS,NMS的优先级按 4 × 4 4\times4 4×4crop图, 4 × 4 4\times4 4×4crop图, 1 × 1 1\times1 1×1图的顺序进行。因为crop是在原图上进行的,原图的分辨率(平均 3300 × 4950 3300\times4950 3300×4950)是远大于 1024 × 1024 1024\times1024 1024×1024的,因此切割的越细的图片,分辨率越高。
(2)Filtering
为了结果的可信度,分别做了3次过滤。第一次,按置信度0.88阈值进行过滤。第二次,对同一预测mask使用不同的阈值,如果在0.5−δ和0.5+δ处对概率图进行阈值处理会导致类似的mask,则认为mask是稳定的,第三,容易出现mask覆盖全图的情况,所以移除占比全图超过95%的mask。
(3)Postprocessing
观察到两种错误类型是可以通过后处理解决的。有4%的mask包含小的杂散的成分,于是移除了面积小于100像素的mask,还有4%的mask中存在空洞,于是填补了面积小于100像素的洞。
自动标注结果组成SA-1B数据集,共10亿mask,1100万张图片。为了评估数据集中mask的质量,随机抽取500张图并由人工矫正,对齐矫正前后的结果,发现94%以上的mask对IoU都在90%以上,97%的mask对IoU在75%以上。
SA-1B数据集的数据源来自于11M个经过许可和隐私保护的图像。具体来说,这些图像是从互联网上收集而来的,包括各种类型的图像,如自然风景、人物肖像、动物等。在收集这些图像时,研究人员采用了一系列自动化技术和算法,以确保数据的质量和隐私性。
第三阶段可以认为是通过预测阶段的增广得到接近人工标注的mask。
5 SAM的应用
5.1 拿来主义
(1)微调模型
SAM的image encoder是从MAE那儿拿来的,拿来之后,image encoder见过了大量的图片,这样的预训练权重是极有意义的。我们可以直接拿SAM的image encoder过来,然后在后面接任意任务的head,也就是decoder,并且在我们自己的数据集上只训练decoder部分,就可以得到比较好的模型。最后再放开整个模型进行训练。
直接拿来是可以得到一个比较好的结果的,但这个结果的上限一下就到头了,想要优化是非常困难的,或者说是无法保障的。甚至可能训练出来的结果都不如其他的模型。
(2)组合模型
现在开源的模型中,不仅仅只有SAM的效果是接近于人工标注的,还有最近很火的的图像生成模型(AIGC),语音模型,目标检测模型等等。把这些模型都结合起来,就能得到许多零样本的优秀模型。Grounded-Segment-Anything是其中做的比较好的,如图5-1和5-2所示,是其中用文本或者语音生成数据的例子。
5.2 三个阶段
看了SAM之后,我认为,关于模型效果的优化,可以分为三个阶段。
(1)模型结构的优化
这个阶段是我们大多深度学习工作者投入大量时间的阶段。给定一个数据集,找一个这个数据集的benchmark,然后拿几个模型过来跑一跑,根据跑的结果,分析模型的哪些结构设计是可以优化的,然后在此基础上优化。其实拿来主义也是一种这个方面的优化,但是几次之后,在这个固定的数据集上,效果就很难提升了。
说的直白一点,优化到后来,可能花个几个月,都是零提升。
(2)半自动的数据扩充
深度学习是数据驱动的科学,有一点是大家公认的,就是更多的数据,可以训练出更好的模型。我们可以像SAM的半自动阶段那样,不断输入新的数据,使用模型进行预标注,然后人工修正,将修正过的图片再喂给模型。这条路是拿人工时间成本换效果,随着时间的积累,模型是可以保证有提升的。
这里推荐一个基于Labelme修改的标注工具AnyLabeling。
(3)全自动的数据扩充
这个是SAM独有的,前提是有一个很好的基础模型,这个基础模型是需要通过(2)训练出来的。有了这个基础模型,设计一套预测的增广,模型的预测结果就可以接近甚至超越人工标注。这个时候,模型学的其实就是预测增广后的能力。模型的能力提升了,增加了预测增广的能力也会随之提升,这是一个正反馈。
只要有一个好的验证策略可以知道模型在更新权重之后是否有效果上的提升,那么,这条路就是拿机器时间成本换效果,随着时间的积累,模型是可以保证有提升的,最终产生质变。
参考资料
[1] https://ai.facebook.com/research/publications/segment-anything/
[2] https://www.chatpdf.com/
[3] https://github.com/IDEA-Research/Grounded-Segment-Anything