朴素贝叶斯代码实现python
- P(B)称为"先验概率",即在A事件发生之前,对B事件概率的一个判断。
- P(B|A)称为"后验概率",即在A事件发生之后,对B事件概率的重新评估。
- P(A|B)/P(A)称为"可能性函数",这是一个调整因子,使得预估概率更接近真实概率。
- 后验概率=先验概率*调整因子
条件概率

求解小硬币的个数;

朴素贝叶斯代码实现python
机器学习之朴素贝叶斯算法详解_平原的博客-CSDN博客_朴素贝叶斯算法
一、 朴素贝叶斯
1、概率基础知识:
条件概率是指事件A在另外一个事件B已经发生条件下的发生概率。 条件概率表示为: P(A|B), 读作“在B条件下A的概率”。
若只有两个事件A, B, 那么:

全概率公式: 表示若事件A1,A2,…,An构成一个完备事件组且都有正概率,则对任意一个事件B都有公式成立。



python 题目(朴素贝叶斯)

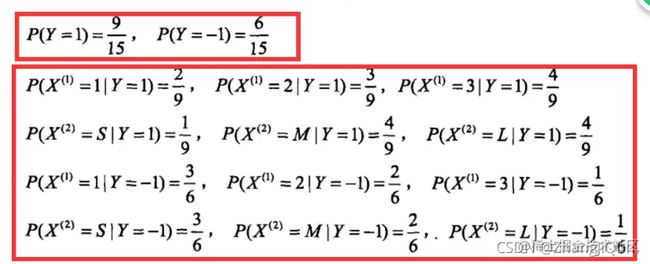
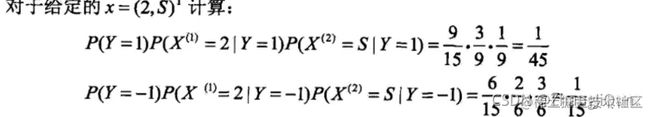
第一阶段——准备阶段, 根据具体情况确定特征属性, 对每个特征属性进行适当划分, 然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段, 其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段, 这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计, 并将结果记录。 其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段, 根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。 这个阶段的任务是使用分类器对待分类项进行分类, 其输入是分类器
和待分类项, 输出是待分类项与类别的映射关系。这一阶段也是机械性阶段, 由程序完成。
#coding:utf-8
# 极大似然估计 朴素贝叶斯算法
import pandas as pd
import numpy as np
class NaiveBayes(object):
def getTrainSet(self):
dataSet = pd.read_csv('naivebayes_data.csv')
dataSetNP = np.array(dataSet) #将数据由dataframe类型转换为数组类型
trainData = dataSetNP[:,0:dataSetNP.shape[1]-1] #训练数据x1,x2
labels = dataSetNP[:,dataSetNP.shape[1]-1] #训练数据所对应的所属类型Y
return trainData, labels
def classify(self, trainData, labels, features):
#求labels中每个label的先验概率
labels = list(labels) #转换为list类型
labels = list(labels) #转换为list类型
P_y = {} #存入label的概率
for label in labels:
P_y[label] = labels.count(label)/float(len(labels)) # p = count(y) / count(Y)
#求label与feature同时发生的概率
P_xy = {}
for y in P_y.keys():
y_index = [i for i, label in enumerate(labels) if label == y] # labels中出现y值的所有数值的下标索引
for j in range(len(features)): # features[0] 在trainData[:,0]中出现的值的所有下标索引
x_index = [i for i, feature in enumerate(trainData[:,j]) if feature == features[j]]
xy_count = len(set(x_index) & set(y_index)) # set(x_index)&set(y_index)列出两个表相同的元素
pkey = str(features[j]) + '*' + str(y)
P_xy[pkey] = xy_count / float(len(labels))
#求条件概率
P = {}
for y in P_y.keys():
for x in features:
pkey = str(x) + '|' + str(y)
P[pkey] = P_xy[str(x)+'*'+str(y)] / float(P_y[y]) #P[X1/Y] = P[X1Y]/P[Y]
#求[2,'S']所属类别
F = {} #[2,'S']属于各个类别的概率
for y in P_y:
F[y] = P_y[y]
for x in features:
F[y] = F[y]*P[str(x)+'|'+str(y)] #P[y/X] = P[X/y]*P[y]/P[X],分母相等,比较分子即可,所以有F=P[X/y]*P[y]=P[x1/Y]*P[x2/Y]*P[y]
features_label = max(F, key=F.get) #概率最大值对应的类别
return features_label
if __name__ == '__main__':
nb = NaiveBayes()
# 训练数据
trainData, labels = nb.getTrainSet()
# x1,x2
features = [2,'S']
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print (features,'属于',result)
复制代码
编辑
朴素贝叶斯算法--python实现 - 一叶舟鸣 - 博客园
拉普拉斯平滑 λ=1 K=2, S=3; λ=1 拉普拉斯平滑
在估计条件概率P(X|Y)时出现概率为0的情况怎么办?
简单来说:引入λ,当λ=1时称为拉普拉斯平滑。
#coding:utf-8
#朴素贝叶斯算法 贝叶斯估计, λ=1 K=2, S=3; λ=1 拉普拉斯平滑
import pandas as pd
import numpy as np
class NavieBayesB(object):
def __init__(self):
self.A = 1 # 即λ=1
self.K = 2
self.S = 3
def getTrainSet(self):
trainSet = pd.read_csv('naivebayes_data.csv')
trainSetNP = np.array(trainSet) #由dataframe类型转换为数组类型
trainData = trainSetNP[:,0:trainSetNP.shape[1]-1] #训练数据x1,x2
labels = trainSetNP[:,trainSetNP.shape[1]-1] #训练数据所对应的所属类型Y
return trainData, labels
def classify(self, trainData, labels, features):
labels = list(labels) #转换为list类型
#求先验概率
P_y = {}
for label in labels:
P_y[label] = (labels.count(label) + self.A) / float(len(labels) + self.K*self.A)
#求条件概率
P = {}
for y in P_y.keys():
y_index = [i for i, label in enumerate(labels) if label == y] # y在labels中的所有下标
y_count = labels.count(y) # y在labels中出现的次数
for j in range(len(features)):
pkey = str(features[j]) + '|' + str(y)
x_index = [i for i, x in enumerate(trainData[:,j]) if x == features[j]] # x在trainData[:,j]中的所有下标
xy_count = len(set(x_index) & set(y_index)) #x y同时出现的次数
P[pkey] = (xy_count + self.A) / float(y_count + self.S*self.A) #条件概率
#features所属类
F = {}
for y in P_y.keys():
F[y] = P_y[y]
for x in features:
F[y] = F[y] * P[str(x)+'|'+str(y)]
features_y = max(F, key=F.get) #概率最大值对应的类别
return features_y
if __name__ == '__main__':
nb = NavieBayesB()
# 训练数据
trainData, labels = nb.getTrainSet()
# x1,x2
features = [2,' U']
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print (features,'属于',result)
复制代码
编辑
【朴素:特征条件独立 贝叶斯:基于贝叶斯定理】
1朴素贝叶斯的概念【联合概率分布、先验概率、条件概率**、全概率公式】【条件独立性假设、】 极大似然估计
2优缺点
【优点: 分类效率稳定;对缺失数据不敏感,算法比较简单,常用于文本分类;在属性相关性较小时,该算法性能最好 缺点:假设属性之间相互独立;先验概率多取决于假设;对输入数据的表达形式很敏感】
3先验概率、后验概率
先验概率的计算比较简单,没有使用贝叶斯公式;
而后验概率的计算,要使用贝叶斯公式,而且在利用样本资料计算逻辑概率时,还要使用理论概率分布,需要更多的数理统计知识。
4朴素贝叶斯的参数估计:
①极大似然估计(可能出现概率为0的情况)②贝叶斯估计(加入常数,拉普拉斯平滑)
在估计条件概率P(X|Y)时出现概率为0的情况怎么办?
简单来说:引入λ,当λ=1时称为拉普拉斯平滑。
4、 朴素贝叶斯的优缺点
优点:对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点:对输入数据的表达形式很敏感(离散、连续,值极大极小之类的)。
重点:
面试的时候怎么回答朴素贝叶斯呢?
首先朴素贝斯是一个生成模型(很重要),其次它通过学习已知样本,计算出联合概率,再求条件概率。
生成模式和判别模式的区别
生成模式:由数据学得联合概率分布,求出条件概率分布P(Y|X)的预测模型;
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
判别模式:由数据学得决策函数或条件概率分布作为预测模型
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场。