使用 Elastic Learned Sparse Encoder 和混合评分的卓越相关性
作者:The Elastic Platform team
2023 年 5 月 25

今天,我们很高兴地宣布 Elasticsearch 8.8 正式发布。 此版本为矢量搜索带来了多项关键增强功能,让开发人员无需付出通常的努力和专业知识即可在搜索应用程序中利用一流的 AI 驱动技术。 使用 Elastic 专有的语义搜索转换器实现卓越的搜索性能,并使用 RRF 实现混合评分 —— 无需参数调整。
此外,对于 Elasticsearch 8.8,即使你在后台使用密集向量检索,也可以使用分面(facets),而新的 Radius 查询将进一步增强你客户的搜索体验!
最后,借助 Elasticsearch 8.8,你可以将生成式 AI 实现的显着创新与 Elasticsearch 的强大功能结合起来 —— 我们将以 Elasticsearch Relevance Engine™ 的形式推出这一切。
这些新功能使客户能够:
- 使用 Elastic 专有的语义搜索转换器 Elastic Learned Sparse Encoder 实现开箱即用的一流语义搜索
- 使用 Reciprocal Rank Fusion (RRF) 简化混合评分
- 在带有半径查询的密集向量检索之上使用分面
- 使用 reroute processor 更好地控制将日志分配给所需的索引或数据流
- 当你的集群接近分片容量时接收警报
- 在发布博客中了解有关 Elastic Learned Sparse Encoder 的更多信息。
在发布博客中了解有关 Elastic Learned Sparse Encoder 的更多信息。 继续阅读下文以了解有关上面突出显示的其他功能的更多详细信息。
使用 Reciprocal Rank Fusion (RRF) 的简化混合搜索
通常,最好的排名是通过组合多种排名方法来实现的,例如 BM25 和生成密集向量嵌入的 ML 模型。 在实践中,将结果集组合成一个单一的组合相关性排名结果集被证明是非常具有挑战性的。 当然,理论上你可以将每个结果集的分数归一化(因为原始分数在完全不同的范围内),然后进行线性组合,根据每个排名的分数加权和排序最终结果集方法。 只要你提供正确的权重,Elasticsearch 就支持它并且运行良好。 为此,你需要了解环境中每种方法得分的统计分布,并有条不紊地优化权重。 实际上,这超出了绝大多数用户的能力。
另一种方法是 RRF 算法,它提供了出色的排序方法零样本混合,正如学术研究所证明的那样。 如果你不了解不同方法中排名分数的确切分布,这不仅是最好的混合方式,而且客观上也是混合排名方法的好方法 —— 即使你知道如何归一化及分数的分布情况,也很难被击败。 基本概念是结果的组合顺序由每个结果集中每个文档的位置(和存在)定义。 因此可以方便地忽略排名分数。
Elastic 8.8 支持具有多个密集向量查询和在倒排索引上运行的单个查询的 RRF。 在不久的将来,我们希望支持来自 BM25 和 Elastic 的检索模型(两者都是稀疏向量)的混合结果,从而产生同类最佳的零样本集(无域内训练)排名方法。
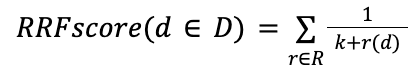
- D - 文档集
- R - 一组排名作为 1..|D| 的排列
- K - 通常默认设置为 60
有向量相似性的分面
相关性排名中的误报会导致用户体验不佳。 看到排名靠前的不相关结果的用户很清楚,这很可能会将相关结果推到他们将查看的有限子集之外,这会降低对搜索结果的信任度。
在传统的基于词频(例如 BM25)的排名中,有一个固有的过滤器 —— 大多数文档将不包含查询中的任何词,并将被从结果集中过滤掉。 这消除了许多误报。 相比之下,在向量搜索中,索引中的每个向量都与查询向量有一个点积(dot product),因此即使是最不相关的文档仍然是候选者。 当使用分面时,这个问题会更加严重,因为过滤建议可能基于相当不相关的结果,并导致用户在使用分面值后将这些结果向上浮动。
相关性阈值解决了这个问题,补充了 Elasticsearch 业界领先的聚合结果集和有效过滤的能力,以支持向量搜索中的分面。
在 Elastic 中存储来自 OpenAI 模型的嵌入
Elasticsearch 现在支持使用 HNSW 算法对高达 2048 维的向量执行 kNN 向量搜索。 输出超过 1024 维的向量在现实生产中有用的模型并不多,但最近用户请求支持 OpenAI 模型说服我们提高阈值。
重新路由摄取处理器:将日志定向到正确的索引或数据流
Elastic 集成可以轻松获取常见的现成日志类型,例如 Apache Nginx 日志、Kafka 指标或 Java 跟踪。 代理会将每种日志类型发送到正确的数据流并摄取管道以解析为可用字段。 当多种日志类型都来自一个混合源时,事情变得更具挑战性,例如容器日志或 firehose。 他们应该使用哪个数据流和管道? 你真的要将其添加到运输代理配置中吗?
使用新的重新路由摄取处理器,你可以集中控制每个文档的处理位置。 使用数据的已知属性(如文件路径或容器名称)来识别源并分配所需的索引或数据流。 重新路由处理器有两种模式:目的地和数据流。 在目标模式下,你明确指定目标索引名称:
{
"reroute": {
"description": "reroute to my errors index",
"if": "ctx.message.indexOf('error') >= 0",
"destination": "myerrorsindex"
}
}在数据流模式下,reroute 会根据日志的类型、数据集和命名空间构造目标数据流名称。 神奇的是它们将从文档中的字段派生,或者你可以自己在处理器中覆盖数据集和命名空间。 请注意,你必须遵循数据流命名方案。
例如,要根据文件路径重新路由 Nginx 日志,请将此处理器包含在你的摄取管道中:
{
"reroute": {
"description": "nginx router",
"if" : "ctx?.log?.file?.path?.contains('nginx')",
"dataset": "nginx"
}
}根据文档中的 service.name 字段重新路由:
{
"reroute": {
"dataset": [
"{{service.name}}",
"generic"
]
}
}如果你想从这些类型的来源之一载入日志,则重新路由处理器可能适合你:
- Lambda 运输功能,包括我们自己的 functionbeat 和我们新的无服务器日志转发器
- 来自我们的 docker 日志记录驱动程序的 Docker 日志
- 来自 Filebeat、Agent 或 Fluentd/Fluentbit 的 Kubernetes pod 日志
- Prometheus 指标:单个 Prometheus 收集器可能会从许多 Prometheus 端点收集指标
- OpenTelemetry 指标:OTel 收集器从许多指标端点收集指标
- Syslog/Journald:许多服务通过单个 syslog 输入发送数据
- GCP 数据流集成
- Azure MP 集成
重新路由处理器在 8.8 中处于技术预览状态。
time_series 索引的增强
time_series 模式下的索引针对指标数据进行了优化。 V8.8 包括对这些索引的多项增强:
- 具有 Flattened 数据类型的字段现在可以用作 time_series 索引中的维度字段(即定义时间序列 id 的字段),从而更容易将现有数据流转换为 time_series 数据流,这通常会减少大约 70% 的索引大小( 这反过来又降低了 TCO)。
- 添加了许多新的压缩方法,这些方法旨在有效压缩指标数据。 这些包括增量编码、XOR 编码、GCD 编码和偏移编码。 这些的影响因数据而异,但在某些情况下,它们可以将字段在索引中占用的大小减少 90% 以上。 这些压缩方法将根据度量类型和数据类型自动用于 time_series 索引。
- 维度字段的数量限制从 16 增加到 21。
健康报告 API 现在指示分片容量
如果你的集群太接近其最大分片容量,重要的操作可能会停止。 如果不通过删除索引、添加节点或增加限制本身来解决分片容量问题,你将无法索引新数据、恢复快照、打开关闭的索引或升级 Elasticsearch。
为了帮助检测和防止这种情况,我们在新的 Health API 中添加了 Shards Capacity 指示器。 如果在当前配置的限制下可用分片少于 10 个,则该指示器将变为黄色,如果剩余分片少于 5 个,则该指示器将变为红色。
例如,如果你有一个包含 3 个数据节点的集群,并且每个非冻结数据节点的默认 cluster.max_shards_per_node 1,000 个分片,则总限制为 3,000 个分片。 如果你当前有 2,993 个分片打开,则运行状况报告将以黄色状态指示分片容量。
该指示器还将显示在 Elastic Cloud Deployments 控制台中。 与健康报告的其余部分一样,我们将指出可能的影响并包括指向相关故障排除指南的链接。
等待 。 . . 还有更多!
Elastic 8.8 包括许多其他增强功能! 你不仅可以从 Elasticsearch 8.8 中的新增功能中了解 Elasticsearch 的其他增强功能,还可以使用你的自定义徽标自定义 Kibana 体验,并在较大工作流中自然需要的地方访问机器学习,从 Discover 开始 —— 查看 Kibana 8.8 中新增功能了解更多详情。 发行说明将为你提供完整的增强功能列表。
试试看
现有的 Elastic Cloud 客户可以直接从 Elastic Cloud 控制台访问其中的许多功能。 还没有使用过 Elastic on Cloud? 开始免费试用。
本博文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。