深度学习--优化器
深度学习-优化器
- 基本框架
- 非自适应学习率
-
- SGD
- Momentum
- Nesterov
- 自适应学习率
-
- Adagrad
- Adadelta
- Adam
- Adamax
- Nadam
- 小结
这里是引用https://blog.csdn.net/u012759136/article/details/52302426/?ops_request_misc=&request_id=&biz_id=102&utm_term=sgd%2520adam&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-7-52302426.first_rank_v2_pc_rank_v29
https://zhuanlan.zhihu.com/p/32230623?utm_source=qq&utm_medium=social&utm_oi=1054735681825386496
基本框架
首先定义:待优化参数: w w w ,目标函数: f ( w ) f(w) f(w) ,初始学习率 α \alpha α
而后,开始进行迭代优化。在每个epoch t t t :
- 计算目标函数关于当前参数的梯度: g t = ∇ f ( w t ) g_{t}=\nabla f\left(w_{t}\right) gt=∇f(wt)
- 根据历史梯度计算一阶动量和二阶动量: m t = ϕ ( g 1 , g 2 , ⋯ , g t ) ; V t = ψ ( g 1 , g 2 , ⋯ , g t ) m_{t}=\phi\left(g_{1}, g_{2}, \cdots, g_{t}\right) ; V_{t}=\psi\left(g_{1}, g_{2}, \cdots, g_{t}\right) mt=ϕ(g1,g2,⋯,gt);Vt=ψ(g1,g2,⋯,gt),
- 计算当前时刻的下降梯度: η t = α ⋅ m t / V t \eta_{t}=\alpha \cdot m_{t} / \sqrt{V_{t}} ηt=α⋅mt/Vt
- 根据下降梯度进行更新: w t + 1 = w t − η t w_{t+1}=w_{t}-\eta_{t} wt+1=wt−ηt
步骤3、4对于各个算法都是一致的,主要的差别就体现在1和2上。
非自适应学习率
SGD
SGD没有动量的概念
SGD为随机梯度下降,每一次迭代计算数据集的mini-batch的梯度,然后对参数进行更新,现在的SGD一般都指mini-batch gradient descent:
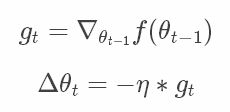
优点:
- 当训练数据太多时,利用整个数据集更新往往时间上不显示。batch的方法可以减少机器的压力,并且可以更快地收敛。
- 当训练集有很多冗余时(类似的样本出现多次),batch方法收敛更快。以一个极端情况为例,若训练集前一半和后一半梯度相同。那么如果前一半作为一个batch,后一半作为另一个batch,那么在一次遍历训练集时,batch的方法向最优解前进两个step,而整体的方法只前进一个step。
缺点:
- 选择合适的learning rate比较困难,对所有的参数更新使用同样的learning rate。对于稀疏数据或者特征,有时我们可能想更新快一些对于不经常出现的特征,对于常出现的特征更新慢一些,这时候SGD就不太能满足要求了
- SGD容易收敛到局部最优,在某些情况下可能被困在鞍点【但是在合适的初始化和学习率设置下,鞍点的影响其实没这么大】
Momentum
为了抑制SGD的震荡,SGDM认为梯度下降过程可以加入惯性。下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。SGDM全称是SGD with momentum,在SGD基础上引入了一阶动量:
Momentum参考了物理中动量的概念,前几次的梯度也会参与到当前的计算中,但是前几轮的梯度叠加在当前计算中会有一定的衰减。

优点:
下降初期时,使用上一次参数更新,下降方向一致,乘上较大的 μ μ μ能够进行很好的加速;下降中后期时,在局部最小值来回震荡的时候, g r a d i e n t → 0 gradient\to0 gradient→0, μ μ μ使得更新幅度增大,跳出陷阱;在梯度改变方向的时候, μ μ μ能够减少更新
总而言之,momentum项能够在相关方向加速SGD,抑制振荡,从而加快收敛
Nesterov
NAG全称Nesterov Accelerated Gradient,是在SGD、SGD-M的基础上的进一步改进,改进点在于步骤1。在时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。因此,NAG在步骤1,不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,那个时候的下降方向:
nesterov项在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。 Nesterov的改进就是让之前的动量直接影响当前的动量。
g t = ∇ θ t − 1 f ( θ t − 1 − η ∗ μ ∗ m t − 1 ) g_t=\nabla_{\theta_{t-1}}{f(\theta_{t-1}-\eta*\mu*m_{t-1})} gt=∇θt−1f(θt−1−η∗μ∗mt−1)
m t = μ ∗ m t − 1 + g t m_t=\mu*m_{t-1}+g_t mt=μ∗mt−1+gt
Δ θ t = − η ∗ m t \Delta{\theta_t}=-\eta*m_t Δθt=−η∗mt
所以,加上nesterov项后,梯度在大的跳跃后,进行计算对当前梯度进行校正。

momentum首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量),nesterov项首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),计算梯度然后进行校正(绿色梯向量)
其实,momentum项和nesterov项都是为了使梯度更新更加灵活,对不同情况有针对性。
自适应学习率
上面提到的方法对于所有参数都使用了同一个更新速率。但是同一个更新速率不一定适合所有参数。比如有的参数可能已经到了仅需要微调的阶段,但又有些参数由于对应样本少等原因,还需要较大幅度的调动。
Adagrad
SGD及其变种以同样的学习率更新每个参数,但深度神经网络往往包含大量的参数,这些参数并不是总会用得到(想想大规模的embedding)。对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。
二阶动量出现了
Adagrad其实是对学习率进行了一个约束。Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与以往的参数模和的开方成反比。即:
n t = n t − 1 + g t 2 n_t=n_{t-1}+g_t^2 nt=nt−1+gt2
Δ θ t = − η n t + ϵ ∗ g t \Delta{\theta_t}=-\frac{\eta}{\sqrt{n_t+\epsilon}}*g_t Δθt=−nt+ϵη∗gt
此处,对 g t gt gt从1到t进行一个递推形成一个约束项regularizer,
− 1 ∑ r = 1 t ( g r ) 2 + ϵ -\frac{1}{\sqrt{\sum_{r=1}^t(g_r)^2+\epsilon}} −∑r=1t(gr)2+ϵ1, ϵ用来保证分母非0
优点:
- 前期gt较小的时候, regularizer较大,能够放大梯度
- 后期gt较大的时候,regularizer较小,能够约束梯度
- 适合处理稀疏梯度
缺点:
- 由公式可以看出,仍依赖于人工设置一个全局学习率
η设置过大的话,会使regularizer过于敏感,对梯度的调节太大;
中后期,分母上梯度平方的累加将会越来越大,使gradient→0,使得训练提前结束。其学习率是单调递减的,训练后期学习率非常小 - 更新时,左右两边的单位不同一
Adadelta
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。
Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。
n t = ν ∗ n t − 1 + ( 1 − ν ) ∗ g t 2 n_t=\nu*n_{t-1}+(1-\nu)*g_t^2 nt=ν∗nt−1+(1−ν)∗gt2
通过这个衰减系数,我们令每一个时刻的 随之时间按照 指数衰减,这样就相当于我们仅使用离当前时刻比较近的 信息,从而使得还很长时间之后,参数仍然可以得到更新。这就避免了二阶动量持续累积、导致训练过程提前结束的问题了
Δ θ t = − η n t + ϵ ∗ g t \Delta{\theta_t} = -\frac{\eta}{\sqrt{n_t+\epsilon}}*g_t Δθt=−nt+ϵη∗gt
特点:
训练初中期,加速效果不错,很快
训练后期,反复在局部最小值附近抖动
Adam
SGD-Momentum在SGD基础上增加了一阶动量,AdaGrad和AdaDelta在SGD基础上增加了二阶动量。把一阶动量和二阶动量都用起来,就是Adam了——Adaptive + Momentum。
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
一阶动量:
m t = μ ∗ m t − 1 + ( 1 − μ ) ∗ g t m_t=\mu*m_{t-1}+(1-\mu)*g_t mt=μ∗mt−1+(1−μ)∗gt
二阶动量:
n t = ν ∗ n t − 1 + ( 1 − ν ) ∗ g t 2 n_t=\nu*n_{t-1}+(1-\nu)*g_t^2 nt=ν∗nt−1+(1−ν)∗gt2
m t ^ = m t 1 − μ t \hat{m_t}=\frac{m_t}{1-\mu^t} mt^=1−μtmt
n t ^ = n t 1 − ν t \hat{n_t}=\frac{n_t}{1-\nu^t} nt^=1−νtnt
Δ θ t = − m t ^ n t ^ + ϵ ∗ η \Delta{\theta_t}=-\frac{\hat{m_t}}{\sqrt{\hat{n_t}}+\epsilon}*\eta Δθt=−nt^+ϵmt^∗η
其中, m t m_t mt, n t n_t nt分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望 E ∣ g t ∣ E|g_t| E∣gt∣, E ∣ g t 2 ∣ E|g_t^2| E∣gt2∣的估计; m t ^ \hat{m_t} mt^, n t ^ \hat{n_t} nt^是对 m t m_t mt, n t n_t nt的校正,这样可以近似为对期望的无偏估计。
可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,而 − m t ^ n t ^ + ϵ -\frac{\hat{m_t}}{\sqrt{\hat{n_t}}+\epsilon} −nt^+ϵmt^对学习率形成一个动态约束,而且有明确的范围。
特点:
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 对内存需求较小
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化
- 适用于大数据集和高维空间
Adamax
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。公式上的变化如下:
n t = m a x ( ν ∗ n t − 1 , ∣ g t ∣ ) n_t=max(\nu*n_{t-1},|g_t|) nt=max(ν∗nt−1,∣gt∣)
Δ x = − m t ^ n t + ϵ ∗ η \Delta{x}=-\frac{\hat{m_t}}{n_t+\epsilon}*\eta Δx=−nt+ϵmt^∗η
Nadam
Nadam类似于带有Nesterov动量项的Adam。加上:
![]()
小结
- 对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
- SGD通常训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
- 主流的观点认为:Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的SGD(+Momentum)往往能够取得更好的最终结果。