计算机视觉 | 目标检测与MMDetection
目 录
目标检测的基本范式
- 滑窗
- 使用卷积实现密集预测
- 锚框
- 多尺度检测与FPN
单阶段&无锚框检测器选讲
- RPN
- YOLO、SSD
- Focal loss 与 RetinaNet
- FCOS
- YOLO系列选讲
一、目标检测的基本范式
1、什么是目标检测
给定一张图片 ——》用矩形框框出所感兴趣的物体同时预测物体类别。
在智慧城市中的应用
目标检测技术的演进

边界框(Bounding Box)
框泛指图像上的矩形框,边界横平竖直
描述一个框需要 4 个像素值:
- 方式1:左上右下边界坐标 (t,r,b)
- 方式2:中心坐标和框的长宽 (x,y,w,h)
边界框通常指紧密包围感兴趣物体的框检测任务要求为图中出现的每个物体预测一个边界框。
交并比 Intersection Over Union
交并比(IoU)定义为两矩形框交集面积与并集面积之比,是矩形框重合程度的衡量指标

2、滑窗 Sliding Window
1)设定一个固定大小的窗口
- 一个好的检测器应满足不重、不漏的要求
- 滑窗是实现这个要求的一个朴素手段
2)遍历图像所有位置,所到之处用分类模型(假设已经训练好) 识别窗口中的内容
3)为了检测不同大小、不同形状的物体,可以使用不同大小、长宽比的窗口扫描图片
改进思路 1:使用启发式算法替换暴力遍历用相对低计算量的方式粗筛出可能包含物体的位置,再使用卷积网络预测早期二阶段方法使用,依赖外部算法,系统实现复杂
改进思路 2: 减少冗余计算,使用卷积网络实现密集预测目前普遍采用的方式,用卷积一次性计算所有特征,再取出对应位置的特征完成分类。
3、感受野(Receptive Field)
感受野:神经网络中,一个神经元能“看到”的原图的区域
换句话说:
- 为了计算出这个神经元的激活值,原图上哪些像素参与运算了?
再换句话说:
- 这个神经元表达了图像上哪个区域内的内容?
- 这个神经元是图像上哪个区域的特征?
4、边界框回归 (Bounding Box Regression)
问题
滑窗 (或其他方式产生的基准框)与物体精准边界通常有偏差
处理方法
让模型在预测物体类别同时预测边界框相对于滑窗的偏移量
多任务学习

5、基于锚框vs无锚框

6、非极大值抑制 NMS
滑窗类算法通常会在物体周围给出多个相近的检测框这些框实际指向同一物体,只需要保留其中置信度最高的
算法实现:

7、密集预测模型的训练
- 检测头在每个位置产生一个预测 (有无物体、类别、位置偏移量)
- 该预测值应与某个真值比较产生损失,进而才可以训练检测器但这个真值在数据标注中并不存在,标注只标出了有物体的地方
- 我们需要基于稀疏的标注框为密集预测的结果产生真值,这个过程称为匹配(Assignment)
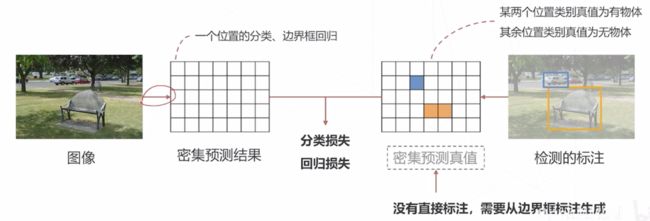
匹配的基本思路
- 对于每个标注框,在特征图上找到与其最接近的位置 (可以不止一个),该位置的分类真值设置为对应的物体
- 位置的接近程度,通常基于中心位置或者与基准框的 IoU 判断
- 其余位置真值为无物体
- 采样: 选取一部分正、负样本计算 Loss (例如可以不计算真值框边界位置的loss)
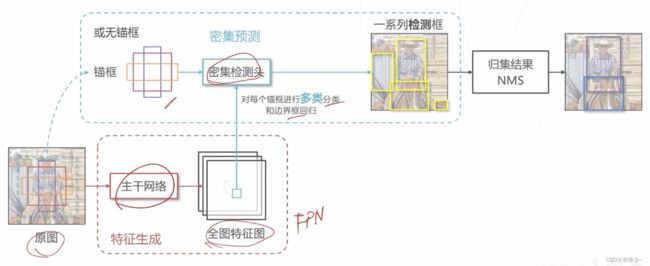
8、密集预测的基本范式

9、如何处理尺度问题
图像中物体大小可能有很大差异(10 px ~ 500 px)
朴素的密集范式中,如果让模型基于主干网络最后一层或倒数第二层特征图进行预测:
- 受限于结构 (感受野),只擅长中等大小的物体
- 高层特征图经过多次采样,位置信息逐层丢失,小物体检测能力较弱,定位精度较低
解决:
- 基于锚框
- 图像金字塔
- 基于层次化特征
- 特征金字塔网络(FPN) 改进思路:高层次特征包含足够抽象语义信息。将高层特征融入低层特征,补充低层特征的语义信息
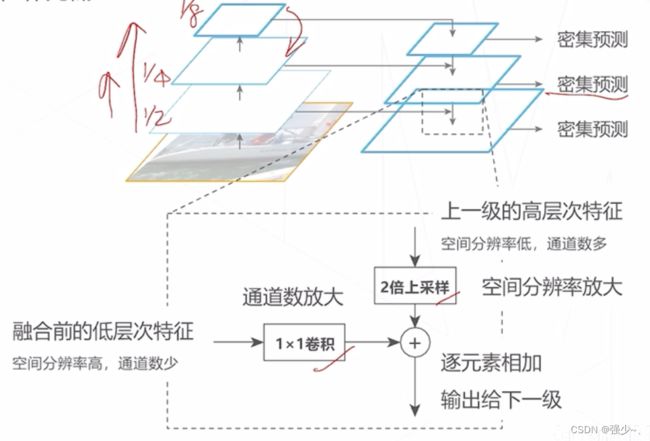
- 多尺度的密集预测
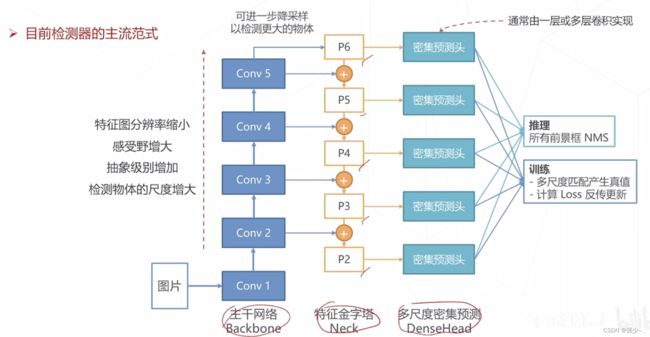
二、单阶段目标检测算法
单阶段算法直接通过密集预测产生检测框,相比于两阶段算法,模型结构简单、速度快,易于在设备上部署。
早期由于主干网络、多尺度技术等相关技术不成熟,单阶段算法在性能上不如两阶段算法,但因为速度和简洁的优势仍受到工业界青睐随着单阶段算法性能逐渐提升,成为目标检测的主流方法
1、YOLO:You Only Look Once(2015)
最早的单阶段检测器之一,激发了单阶段算法的研究潮流
主干网络: 自行设计的 DarkNet 结构,产生 7x7x1024 维的特征图
检测头: 2 层全连接层产生 7x7 组预测结果,对应图中 7x7 个空间位置上物体的类别和边界框的位置

2、SSD Single Shot MultiBox Detector(2016)
- 主干网络: 使用 VGG + 额外卷积层,产生 11 级特征图
- 检测头: 在 6 级特征图上进行密集预测,产生所有位置、不同尺度的预测结果

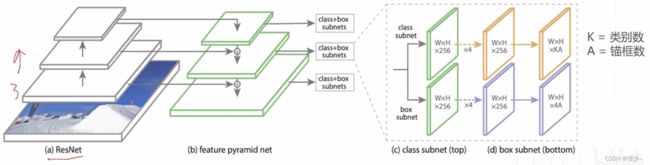
3、RetinaNet(2017)
- 特征生成: ResNet 主干网络 + FPN 产生 P3~P7,共 5 级特征图,对应降采样率 8~128 倍
- 多尺度锚框: 每级特征图上设置 3 种尺寸x3 种长宽比的锚框,覆盖 32~813 像素尺寸
- 密集预测头:两分支、5 层卷积构成的检测头,针对每个锚框产生K 个二类预测以及 4 个边界框偏移量
- 损失函数: Focal Loss
单阶段算法面临的正负样本不均衡问题
- 单阶段算法共产生尺度数x位置数x锚框数个预测
- 而这些预测之中,只有少量锚框的真值为物体(正样本),大部分锚框的真值为背景 (负样本)
- 使用类别不平衡的数据训练出的分类器倾向给出背景预测,导致漏检
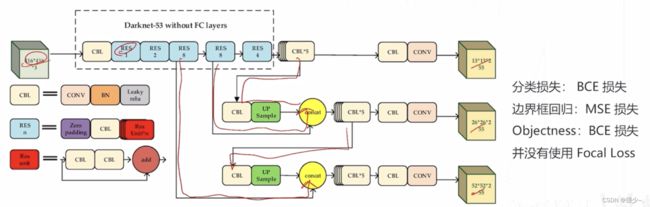
4、YOLOv3(2018)
- 自定义的 DarkNet-53 主千网络和类 FPN 结构,产生 1/8、1/16、1/32 降采样率的 3 级特征图
- 在每级特征图上设置 3 个尺寸的锚框,锚框尺寸通过对真值框聚类得到
- 两层卷积构成的密集预测头,在每个位置、针对每个锚框产生 80 个类别预测、4个边界框偏移量、1个 objectness 预测,每级特征图 3x(80+4+1)=255 通道的预测值
5、YOLOv5(2020)
- 模型结构进一步改进、使用 CSPDarkNet 主干网络
- PAFPN 多尺度模块等
- 训练时使用更多数据增强,如 Mosaic、MixUp 等使用自对抗训练技术 (SAT)提高检测器的鲁棒性
三、无锚框目标检测算法
基于锚框(Anchor-based)
- Faster R-CNN、YOLO v3 /v5、RetinaNet 都是基于锚框的检测算法
- 模型基于特征预测对应位置的锚框中是否有物体,以及精确位置相对于锚框的偏移量
- 实现复杂,需要手动设置锚框相关的超参数 (如大小、长宽比、数量等),设置不当影响检测精度 X
无锚框(Anchor-free)
- 不依赖锚框,模型基于特征直接预测对应位置是否有物体,以及边界框的位置
- 边界框预测完全基于模型学习,不需要人工调整超参数
1、FCOS,Fully Convolutional One-Stage(2019)
- 模型结构与 RetinaNet 基本相同: 主干网络 + FPN +两分支、5 层卷积构成的密集预测头
- 预测目标不同:对于每个点位,预测类别、边界框位置和中心度三组数值

FCOS的多尺度匹配
Anchor-based 算法根据锚框和真值框的 loU 为锚框匹配真值框通常,锚框会匹配到同尺度的真值框,小物体由低层特征预测,大物体由高层特征图预测
- 问题: Anchor-free 算法没有锚框,真值框如何匹配到不同尺度?
- 匹配方案: 每层特征图只负责预测特定大小的物体,例如右图中512像素以上的物体匹配到P7上
由于重叠的物体尺度通常不同,同一位置重叠的真值框会被分配到不后的特征层,从而避免同一个位置需要预测两个物体的情形
2、CenterNet(2019)
针对 2D 检测的算法,将传统检测算法中的“以框表示物体”变成“以中心点表示物体”,将 2D 检测建模为关键点检测和额外的回归任务,一个框架可以同时覆盖 2D 检测、3D 检测 、姿态估计等一系列任务。

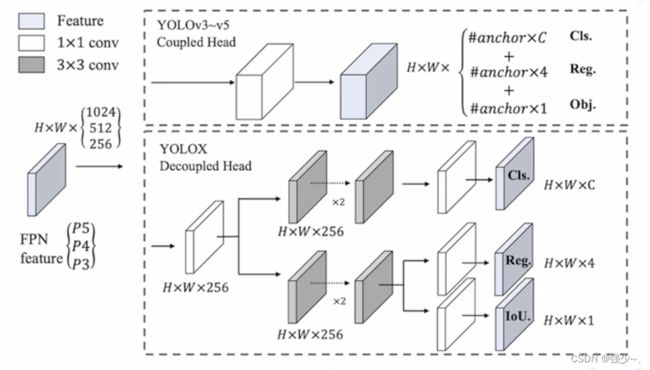
3、YOLOX(2021)
以 YOLO v3 为基准模型改进的无锚框检测器
- Decouple Head 结构
- 更多现代数据增强策略
- SimOTA 分配策略
- 从小到大的一系列模型
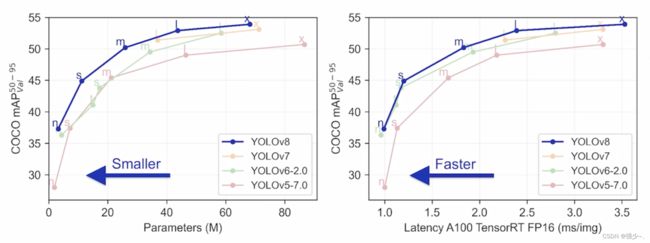
4、YOLOv8(2022)
单阶段与无锚框算法的总结