深度学习算法
深度学习
文章目录
- 深度学习
-
- 机器学习基础
- 计算机视觉:
-
- 基础补充:
- 计算机视觉
-
- 图片分类算法
- 目标检测算法
- 语义分割
- 生成式(Generative)
- 视觉追踪(目标追踪)
- 人体姿态识别
- 光学字符识别(OCR-Optical Character Recognition)
- 自然语言(NLP)
-
- 序列模型:
- word2vec
- 词嵌入(Word Embedding)
- 推荐算法
- BI方向:
-
- 预测全家桶:
- 时间序列:
- 矩阵分解与因子分解机
- PageRank、图论与推荐系统
- 知识图谱
- 风控模型(评分卡模型)
- 项目列表
-
- 唐宇迪
- 基础概念补充:
机器学习基础
k-means、距离计算、梯度下降
集成模型、决策树
线性回归和逻辑回归
softmax与cross-entropy
欠拟合与过拟合
正则化、corss-validation
贝叶斯定理、朴素贝叶斯、机器学习评价方法、生成模型与判别模型
计算机视觉:
基础补充:
卷积核大小(Kernel Size):
步长(Stride)
填充(Padding)
输入/输出管道(Input & Output Channels)
感受野
卷积分类:
标准卷积
分组卷积(Group convolution)
点卷积(Pointwise convolution)(1*1卷积核)
可分离卷积(Separable convolution)
深度可分离卷积(Depthwise convolution)
空洞卷积(Dilated convolution)
解决pixel-wise输出模型的一种常用的卷积方式(通常用于语意分割)
3D卷积
转置卷积(反卷积)
- 最近邻插值(Nearest neighbor interpolation)
- 双线性插值(Bi-Linear interpolation)
- 双立方插值(Bi-Cubic interpolation)
正则化:
- batch normalization、group normalization
- dropout
- L1、L2
常见损失:
- focal loss(何凯明)
- 交叉熵
- 对比损失(Contrastive Loss)
- 三元组损失(Triplet Loss)
优化算法:
优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam
- SGD
- AdaGrad
- Adam
- Momentum
- Nesterov Accelerated Gradient
concat 与 add的区别
注意力机制
边框回归:
Bounding Box Regression
非极大值抑制:
- NMS
- Soft NMS
激活函数
一般激活函数有如下一些性质:
- 非线性: 当激活函数是线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数的时候,即f(x)=x,就不满足这个性质,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
- 可微性: 当优化方法是基于梯度的时候,就体现了该性质;
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数;
- f(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值;
- 输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的Learning Rate。
- Sigmoid
- tanh
- Leaky-ReLU
- P-ReLU(Parametric ReLU 对于 Leaky ReLU 中的α)
- R-ReLU(Randomized Leaky ReLU 是 Leaky ReLU 的随机版本(α 是随机选取))
评价指标:
目标检测map
ar/ap/threshold
语义分割(PA、MPA、MIoU、FWIoU)
batch size的选择
- Gradient Descent:所有样本算出的梯度的平均值来更新每一步
- Stochastic Gradient Descent:一个样本算出的梯度来更新每一步
- Minibatch Gradient Descent:n个样本算出的梯度的平均值来更新每一步
个人习惯从 batch size 以 128 为分界线。向下 (x0.5) 和向上 (x2) 训练后比较测试结果。若向下更好则再 x0.5,直到结果不再提升。
大 batch size 限于空间-GPU/NPU显存,小 batch size 苦于时间(项目紧)
深度学习的跃进来源于不同技术的组合:层、梯度更新方式、初始化方式、非线性、目标函数、正规项等
梯度消失、爆炸原因及其解决方法
- 预训练加微调
- 梯度剪切、权重正则(针对梯度爆炸)
- 使用不同的激活函数
- 使用batchnorm
- 使用残差结构
- 使用LSTM网络
网络权重初始化
Graph Convolutional Network(GCN)
全卷积网络
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
Spatial invariant、Pooling、Dropout与Batch Normalization
计算机视觉
核心知识点:
1、图像相似变化、仿射变换、图像锐化、模糊、形态学运算、灰度直方图、直方图均衡化
2、方向梯度直方图(Histogram of Driented Gradient ,HOG)、图像局部纹理特征(Local Binary Pattern,LBP)、Haar-Like特征提取
3、GPU/CPU架构、GPU线程的操作与调度、认识pycuda库、用Pycuda实现矩阵乘法
图片分类:AlexNet、VGG、Resnet、DenseNet、MobileNet、EfficientNet
目标检测:RCNN、NMS、Fast RCNN、ROI Pooling、Faster RCNN、RPN、Anchor、YOLO v1 ~ v4
图像分割:反卷积与上采样、全卷积网络(FCN)、UNet、ENet、Mask RCNN、TensorMask(分割模型的评价指标)
目标追踪:TLD、KCF、卡尔曼滤波、mean-shift、粒子滤波、siamese系列
图片分类算法
LeNet(1998)
AlexNet(2012)
- 更深的CNN能带来好的效果
- GPU训练
- dropout
- 数据增强
- 将激活函数sigmoid -> relu
VGG(2014)
提出通过重复简单的基础块来构建深度模型的思路
NiN
串联多个有卷积层和“全连接”层构成的小网络来构建一个深网络。改进:NiN使用1*1卷积层来替换全连接层,从而是空间信息能够自然的传递到后面层中。
GoogLeNet(2014)
主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3*3
最大池化层来减小输出高宽。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xm5XM5Vl-1637712218939)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20211122223233041.png)]
- 多尺度特征 然后再concate
- 1*1 卷积 降低计算量
- 去掉一个FC, 使用avgpooling
Inception 系列
ResNet(2015)
-
GPU
-
dropout(防止过拟合)
-
BatchNormal(梯度消失)
-
残差(解决层数边深精度退化问题)
基础模块:
基础结构(BasicBlock)
瓶颈结构(Bottleneck)
1 * 1 降维、 3 * 3、 1* 1 升维
Resnext(2017)
- ResNext = ResNet + inception
- 不需要人工设计复杂的inception结构细节,而是每个分支都采用相同的拓扑结构。
- 分组卷积(Group Convolution)
DenseNet(2017)
-
DenseBlock
作用:
- 缓解梯度消失
-
强化了特征的传播及重用
- 减少网络参数
Bottlenneck Layers
经过一个L层的神经网络,其中第i层的非线性变换记为:
H i ( ∗ ) , 可 以 为 多 种 函 数 操 作 的 累 加 如 B N 、 R e L U 、 P o o l i n g 或 c o n v H_i(*) \text,可以为多种函数操作的累加如 BN、ReLU、Pooling或conv Hi(∗),可以为多种函数操作的累加如BN、ReLU、Pooling或conv
第i层的输入不仅与i-1层的输出相关,还与所有之前层的输出有关:
X i = H i ( [ X 0 , X 1 , . . . , X i − 1 ] ) X_i = H_i([X_0, X_1,...,X_{i-1}]) Xi=Hi([X0,X1,...,Xi−1])
Growth rate每层输入为:
i n p u t i = K o + ( i − 1 ) k input_i = K_o + (i - 1)k inputi=Ko+(i−1)k -
transition layer
作用:
降低feature map(channels)的数量
BN
Conv(1 * 1)
2*2 average pooling
MobileNet
-
MobileNet v1
- 深度可分离卷积
- 1*1 卷积
-
MobileNet v2
- 具有线性瓶颈的倒残差结构
- shortcut
-
MobileNet v3(2019)
-
- 互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索。
- 网络结构改进:SE模块;将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish**函数。
-
MnasNet
-
基于squeeze and excitation就够的轻量级注意力模型
-
新的激活函数swish x改进模型精度:
-
s w i s h x = x ∗ δ ( x ) swish x = x * \delta(x) swishx=x∗δ(x)
-
由于计算量太大,作者对这个函数进行近似处理
-
h − s w i s h [ x ] = x R e L U 6 ( x + 3 ) 6 h-swish[x] = x\frac{ReLU6(x + 3)}{6} h−swish[x]=x6ReLU6(x+3)
-
网络在分类、目标检测、语义分割三个任务中验证了MobileNetV3的优势
-
shuffleNet(移动端使用-矿世)
- group convolution
- channel shuffle 转置
squeezeNet(16)
减少模型大小,精度不下降
- fire
- squeeze
- expand
- 3*3 =》 1 * 1
- shortcut
squeezeNet + deepcompression
剪枝
权值量化、权值共享
哈夫曼编码
SENet(Squeeze and excitaion)
两个分支
- squeeze
- excitation
EfficientNet
目标检测算法
| two-stage:基于候选区域 | one-stage:单次检测器 | |
|---|---|---|
| R-CNN(region proposals) | YOLO | |
| spp | SSD | |
| Fast R-CNN | ||
| Faster R-CNN | retinaNet | |
| Mask R-CNN | ||
| F-RCN | FaceNet | |
one-stage anchor-free
目标检测backbone、Neck、head
backbone
作用:
-
每个被选择的特征图都有内在固有的语义表达能力。(感受野区域)
-
每个特征图提供了固有的下采样倍数,或者说特征图上的每个位置的感受野步长。
-
以满足对不同尺度和类别的目标检测。
分类:
- VGG
- ResNet
- ResNeXt
- EfficientNet(NAS做出)
- MobileNet
Neck:
作用:
将来自于backbone的多个层级的特征图进行融合加工,增强其表达能力的同时,输出加工后并具有相同的特征图以供head使用,这里的特征图可能多余或少于Backbone提供的特征图数量。
分类:
- NaiveNeck
- FPN
- BiFPN
- PANet
- NAS-FPN
head
区分:
- 有quality分支:
- 无quality分支:
作用:
分类:
-
RetinaNet-head
-
FCOS-Head
Bounding box(边界框)
-
矩形左上角的 和 轴坐标与右下角的 和 轴坐标确定,图中的坐标原点在图像的左上角,原点往右和往下分别为 轴和 轴的正方向
-
记录方式:
[左上角x, 左上角 y, 右下角x, 右下角 y]
Anchor box(锚框)
-
它以每个featuremap的点为中心生成多个大小 和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)
-
假设输入图像高为 ,宽为 。我们分别以图像的每个像素为中心生成不同形状的锚框。设缩放比为 (该数值描述基准锚框的大小信息,若取值为 ,那么基准锚框面积由原图宽和高分别缩小 倍所 得,也即 )且宽高比为 ,我们假设其宽为 ,高为 ,就有
{ w ‘ ∗ h ‘ = s 2 ∗ w ∗ h w 1 h ‘ = r = > { h ‘ = s ∗ w h r w ‘ = s ∗ r w h \left\{ \begin{array}{lr} w^` * h^` = s^2 * w * h \\ \frac{w^1}{h^`} = r \end{array} \right. => \left\{ \begin{array}{lr} h^` = s * \sqrt\frac{wh}{r} \\ w^` = s * \sqrt{rwh} \end{array} \right. {w‘∗h‘=s2∗w∗hh‘w1=r=>{h‘=s∗rwhw‘=s∗rwh
对图片的长宽分别做归一化处理,也即w = 1, h = 1, 此时:
h ‘ = s r , w ‘ = s r h^` = \frac{s}{\sqrt{r}}, w^`=s\sqrt{r} h‘=rs,w‘=sr
也即由 和 可以确定锚框的宽和高,当中心位置给定时,已知面积 和宽高比 的锚框是确定的。
mAP
mAP,目标检测中衡量识别精度的指标是mAP(mean average precision)。多个类别物体检测中,每一个类别都可以根据recall和precision绘制一条曲线,AP(通过调整不同的阈值,画出AP曲线)就是该曲线下的面积,mAP是多个类别AP的平均值
two-stage:基于候选区域
R-CNN(region proposals)
- select search -> region proposals 提议区域
- SVM判断是否属于某个类别
- 线性回归模型来预测真实边界框。
Fast R-CNN
-
提取特征的卷积神经网络的输入时整个图像
-
ROI(region of interest Pooling)-有两次取整,精度有影响
-
sotfmax回归预测类别
-
fc 预测边框
Faster R-CNN
-
tansformer
-
RPN(区域生成网络 region proposal network)(改进)
-
非极大值抑制
先计算与groud truth 的交并比 , 保留大于阈值的
再计算与最大概率的box的交并比,保留小于阈值的
包含:
RPN
FPN
非极大值抑制
anchor box
roi pooling
Mask R-CNN
-
ROI -> 兴趣区域对齐层(双线性插值 bilinear interpolation)
-
适用于像素级预测
应用场景:
目标检测
语义分割
F-RCN
SPP(Spatial Pyramid Pooling) 空间金字塔池化
one-stage:单次检测器
YOLO
Yolo v1
- bounding box regression
- bounding box -》 [x1, y1, x2, y2]
Yolo v2
改进:
Batch Normalization(批量归一化)
High resolution classifier(高分辨率图像分类器)
Convolution with anchor boxes(使用先验框)
Yolo v3
改进:
多尺度预测(引入FPN)
更好的基础分类网络(darkNet-53, 类似于ResNet引入残差结构 short-cut)
分类器不在使用Softmax, 分类损失采样binary cross-entropy loss(二分类交叉损失商)
特征图金字塔网络FPN(Feature Pyramid Networks)是2017年提出的一种网络,FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。
Tiny YOLOv3
YOLOv3相比之前的版本确实精度提高了不少,但是相应的变慢了一些
Yolo v4
主要目的在于设计一个能够应用于实际工作环境中的快速目标检测系统,且能够被并行优化,并没有很刻意的去追求理论上的低计算量(BFLOP)
-
Weighted-Residual-Connections (WRC)
-
Cross-Stage-Partial-connections (CSP)
-
Cross mini-Batch Normalization (CmBN)
-
Self-adversarial-training (SAT)
-
Mish-activation
-
Mosaic data augmentation
-
CmBN
-
DropBlock regularization
-
CIoU loss
Yolov4框架:
BackBone:CSPDarknet53
Neck: SPP, PAN
Head:YOLOv3
YOLOv4 = CSPDarnNet53 + SPP + PAN + YOLOv3
Yolo v5
-
速度快
-
非常轻量级的模型大小
-
准确度与YOLOv4基准相当
FaceNet
- 人脸识别
SSD(Single-Shot MultiBox Detector)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LLHDJdO9-1637712218941)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20211123222033736.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uqcNI7JH-1637712218942)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20211123220829521.png)]
原理:
它主要由一个基础网络模块和若干个多尺度特征模块串联而成。其中基础网络模块用来从原始图像中抽取特征,因此一般都会选择常用的深度卷积神经网络(vgg/resnet/mobileNet)。完整的模型,单发多框检测模型一共包含5个模块,每个模块输出的特征图既用来生成锚框,又用来预测这些锚框的类别和偏移量。
-
类别预测层:使用卷积层的通道来输出类别预测的方法(anchr*(q+1))
-
边界框预测层:边界框预测层的设计与类别预测层的设计类似。唯一不同的是,这里需要为每个锚框预测4个偏移量,而不是q+1个类别。(anchr*4)
-
连结多尺度的预测:单发多框检测根据多个尺度下的特征图生成锚框并预测类别和偏移量。预测输出的格式为(批量大小, 通道数, 高, 宽)。将预测结果转成二维的(批量大小, 高宽通道数)的格式,以方便之后在维度1
上的连结。 -
高和宽减半块:它串联了两个填充为1的3*3卷积层和步幅为2的2*2最大池化层(NiN)
-
基础网络块:用来从原始图像中提取特征。
第一模块为基础网络块,第二模块至第四模块为高和宽减半块,第5模块使用全局最大池化层将高和宽降到1。因此第二至第五模块均为上图中的多尺度特征块。
-
一个基础模块
-
若干个多尺度特征块串联(每次特征图宽高减半)
-
NiN思想构建输出结构,替换FC,全局最大池化层将宽高降到1
损失函数:目标检测有两个损失函数:
1、有关锚框类别损失:交叉熵损失函数
2、有关正类锚框偏移量的损失:不使用平方损失》使用L1范数损失,即预测值域真实值之间的绝对值。掩码变量bbox_masks 令负类锚框和填充锚框不参与损失的计算。最后,我们将有关锚框类别和偏移量的损失相加得到模型的最终损失函数。
类别损失函数:交叉熵损失函数 -》
$$
-
\alpha (1-p_j)^{\gamma} \log p_j.
$$何凯明提出:focal-loss:增大γ可以有效减小正类预测概率较大时的损失
边框损失函数:L1范数损失——预测值与真实值之间差的绝对值
-》 可以替换成:smooth_l1
f ( x ) = { ( σ x ) 2 / 2 , if ∣ x ∣ < 1 / σ 2 ∣ x ∣ − 0.5 / σ 2 , otherwise f(x) = \begin{cases} (\sigma x)^2/2,& \text{if }|x| < 1/\sigma^2\\ |x|-0.5/\sigma^2,& \text{otherwise} \end{cases} f(x)={(σx)2/2,∣x∣−0.5/σ2,if ∣x∣<1/σ2otherwise- 当目标在图像中占比较小时,模型通常会采用比较大的输入图像尺寸。
- 为锚框标注类别时,通常会产生大量的负类锚框。可以对负类锚框进行采样,从而使数据类别更加平衡。这个可以通过设置
MultiBoxTarget函数的negative_mining_ratio参数来完成。 - 在损失函数中为有关锚框类别和有关正类锚框偏移量的损失分别赋予不同的权重超参数。
RetinaNet
-
resnet + fpn(backbone)
-
Focal Loss
语义分割
| FCN | |
|---|---|
| ENet | |
| UNet | |
| Mask RCNN | |
| TensorMask |
FCN(fully convolutional network)
- 不含全连接(fc)的全卷积网络。可适应任意尺寸输入。
- 增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和准确性。
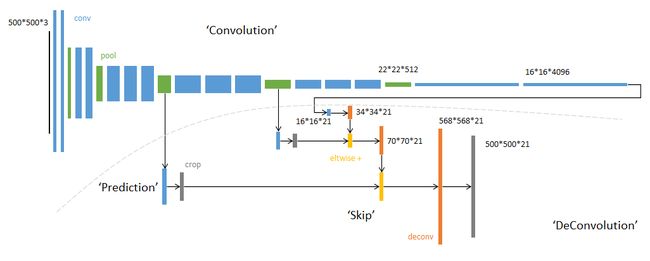
U-Net(2015)
=> FPN
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s5ttpbEe-1637712218944)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210405174033029.png)]
组成:
- encode-decoder
- 下采样(Max pooling)
- 上采样(upsample)
- skip-connection(多尺度特征融合)
- 全部使用3*3卷积
ENet
Msk RCNN
TensorMask
生成式(Generative)
DeepDream
DCCGAN
Pix2Pix
CycleGAN
StarGan
Adversaarial FGSM
GitGan
视觉追踪(目标追踪)
人体姿态识别
openpose
光学字符识别(OCR-Optical Character Recognition)
1基于传统算法的ocr技术
传统的ocr技术通常使用opencv算法库,通过图像处理和统计机器学习方法从图像中提取文本信息。
包括:二值化、噪声滤波、相关域分析、AdaBoost等。
传统方法分为三个阶段:
-
图像准备预处理
文字区域定位:连通区域分析、MSER
文字矫正:旋转、仿射变换
文字分割:二值化、过滤噪声
-
文本识别
分类器识别:逻辑回归、SVM、Adaboost
-
后处理:规则、语言模型(HMM等)
2、基于深度学习的OCR技术
目前,基于深度学习的场景文字识别主要包括两种方法,第一种是分为文字检测和文字识别两个阶段;第二种则是通过端对端的模型一次性完成文字的检测和识别。
阶段一:文字检测
CTPN
TextBoxes/TextBoxes++
EAST
阶段二:文字识别
通过文字检测对图片中的文字区域进行定位后,还需要对区域内的文字进行识别。
1、CNN + softmax
2、CNN + RNN + attention
-
模型首先在输入图片上运行滑动CNN以提取特征;
-
将所得特征序列输入到推叠在CNN顶部的LSTM进行特征序列的编码;
-
使用注意力模型进行解码,并输出标签序列。
3、CNN + stacked CNN + CTC
CNN + RNN + attention方法不可避免的使用到RNN架构,RNN可以有效的学习上下文信息并捕获长期依赖关系,但其庞大的递归网络计算量和梯度消失/爆炸的问题导致RNN很难训练。基于此,有研究人员提出使用CNN与CTC结合的卷积网络生成标签序列,没有任何重复连接。
这种方法的整个网络架构如下图所示,分为三个部分:
- 注意特征编码器:提取图片中文字区域的特征向量,并生成特征序列;
- 卷积序列建模:将特征序列转换为二维特征图输入CNN,获取序列中的上下文关系;
- CTC:获得最后的标签序列。
4、特定的弯曲文本识别
Robust Scene Text Recognition with Automatic Rectification(2016)
对于弯曲不规则文本,如果按照之前的识别方法,直接将整个文本区域图像强行送入CNN+RNN,由于有大量的无效区域会导致识别效果很差。所以这篇文章提出一种通过STN网络学习变换参数,将Rectified Image对应的特征送入后续RNN中识别。
端到端文字识别
使用文字检测加文字识别两步法虽然可以实现场景文字的识别,但融合两个步骤的结果时仍需使用大量的手工知识,且会增加时间的消耗,而端对端文字识别能够同时完成检测和识别任务,极大的提高了文字识别的实时性。
STN-ORC
定位网络:针对输入图像预测N个变换矩阵,相应的输出N个文本区域,最后借助双线性差值提取相应区域;
识别网络:使用N个提取的文本图像进行文本识别
FOTS
FOTS是一个快速的端对端的文字检测与识别框架,通过共享训练特征、互补监督的方法减少了特征提取所需的时间,从而加快了整体的速度。其整体结构如图所示:
-
卷积共享:从输入图象中提取特征,并将底层和高层的特征进行融合;
-
文本检测:通过转化共享特征,输出每像素的文本预测
-
ROIRotate:将有角度的文本块,通过仿射变换转化为正常的轴对齐的本文块
-
文本识别:使用ROIRotate转换的区域特征来得到文本标签
ocr检测流程:
CTPN文字检测
序列网络的作用
CTPN细节
CRNN
CTC模块的作用
自然语言(NLP)
核心知识点汇总:
1、NLP基本过程,预料获取、爬虫、语料处理、特征工程、模型训练与评估
2、向量空间模型(vector Space Model,VSM)、skip-Gram、CBOW(continuous Bag of Words)、欧式距离、余弦距离、主成分分析(Principal Component Analysis,PCA)、T-SNE
3、tf-idf(Term Frequency Inverse Document Frequency)、TextRank、实体识别(Entity Recognition,ER)、依存分析、主题模型、隐含语义分析(Latent Semantic Analysis,LSA)、狄利克雷分布(Latent Dirichlet Allocation,LDA)、Expecation-Maximum算法
4、贝叶斯网络、马尔科夫链、语言模型(Language Model)、N-Gram语法、困惑度(Perplexity)、平滑(Smoothing)、隐马尔可夫模型(Hidden Markov Model,HMM)、维特比算法(Viterbi)、条件随机场(Conditional Random Field,CRF)
5、Word2Vec、哈夫曼树、层次Softmax(Hierarchical Softmax)、负采样(Negative Sampling)、Glove、CoVe、ElMo、句子向量(Sentence Vector)、局部敏感哈希(Local Hash Sensitive,LHS)
6、Seq2Seq、机器翻译(Machine Traslation)、注意力机制(Attention Mechanism)、Layer Normalization、Transformer、BERT、Masked Language Model、RoBERT、ALBERT、矩阵分解(Matrix Decomposition)
7、集束搜索(Beam Search)、Softmax温度(Softmax Temperature)、复制机制(Copy Mechanisms)、重复问题(Repetition preblem)、BLEU、ROUGE、METEOR
8、强化学习(Reinforcement Learning)、图神经网络(Graph Neural Network)、低资源学习(Machine Reading Comprehension)
序列模型:
RNN
GRU:
- 相关性门:
- 更新门:
LSTM:
三个门:
- 更新门:
- 遗忘门:
- 输出门:
word2vec
词嵌入(Word Embedding)
词汇表征:
- One-Hot Encoder
- word Embeddings (skip gam/ cbow)
词嵌入的特性:
-
能实现类比
例如:man -> woman
king -> queen?
嵌入矩阵:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zAx6nQ1E-1637712218947)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210304221346997.png)]
学习词嵌入:
算法:
Word2Vec:
CBOW
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XCr6L5Z9-1637712218948)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210304221519149.png)]
Skip-Gram
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bBImObPL-1637712218950)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210304221525864.png)]
Trick:
Hierarchical softmax
本质是把N分类问题变成log(N)次二分类
Negative sampling
本质是预测总体类别的一个子集
构造一个新的监督学习问题,给定一对单词,我们需要预测这是否是一对上下文词-目标词(context-target)
GloVe(global vectors for word representation)
假 定 X i j 是 单 词 i 在 单 词 J 上 下 文 出 现 的 次 数 假定X_{ij}是单词i在单词J上下文出现的次数 假定Xij是单词i在单词J上下文出现的次数
情感分类(Sentiment Classification)
词嵌入除偏(Debiasing word Embeddings)
python第三发库:
Gensim 、NLTK
算法:
seq2seq(基础结构lstm/gru)
transformer(基础结构self-attention)
elmo
Bert(Bidirectional Encode Representations from Transformers)
网络结构:
- 使用transformer算法的encoder部分
训练任务:
-
Mask Language Mode(MLM)
15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,80%的时候会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的时候会保留原始Token
-
Next Stentence Prediction(NSP)
判断句子B是否是句子A的下文(根据输入的句子对)
包含结构:
-
multi head attention
-
short cut
-
add& layer normalize
预训练:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DnJm5Jfc-1637712218951)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210331220606033.png)]
输入数据:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vgje1jlc-1637712218953)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210331220715211.png)]
三个向量相加
Token Embeddings:
词嵌入方式 =》768维向量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Di64Sm1X-1637712218954)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210331222736822.png)]
Segment Embeddings:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jwp5qYrC-1637712218955)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210331222827014.png)]
Position Embeddings:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cQAGxwjL-1637712218956)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210331221838628.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oTSCdAyi-1637712218957)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210331222002391.png)]
评估指标:
- GLUE
- SQuAD v1.1
- SQuAD v2.0
- SWAG
Gpt3
attention
- base attention
- self attention
- mutl attention
GNMT-谷歌的神经网络翻译系统
推荐算法
LR
FM
在LR + 两两交叉特征
FFM
新加入Field(域)
域表示特征所属的类型
域和特征之间是一种1:n的关系,多个特征可以同属一个域,是一种抽象的概念比如一些one-hot生成的列名 性别=男 和性别=女,也属于同一性别field
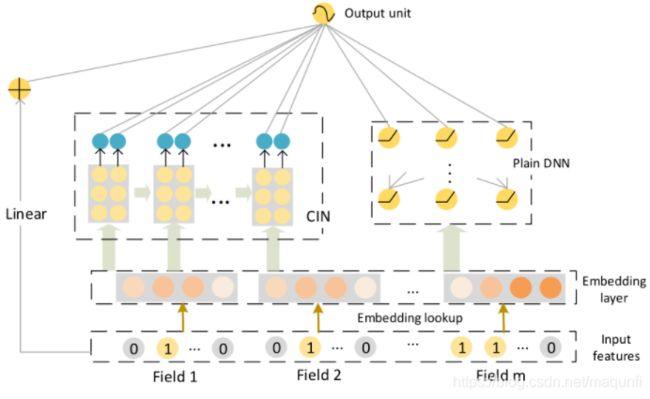
DeepFM
(1) 不需要预训练 FM 得到隐向量;
(2) 不需要人工特征工程;
(3)能同时学习低阶和高阶的组合特征;
(4)FM 模块和 Deep 模块共享 Feature Embedding 部分,可以更快的训练,以及更精确的训练学习。
wide&deep(2016)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mEDt1WWZ-1637712218958)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210318231225169.png)]
交叉特征(dot prodcut transfomation)
wide: 记忆
优化器:在线学习+L1正则化
deep:泛化
优化器:adaGrad
Deep&Cross
XdeepFM
BI方向:
预测全家桶:
LR、NB、SVM、KNN、GBDT、XGBoost、LightGBM、CatBoost、NGBoost
树模型以机器学习四大神器
任务:
使用XGBoost、LightGBM、CatBoost中的任意一种对男女声音进行识别
时间序列:
Auto Regressive、Moving Average、Auto Regressive Moving Average、auto Regressive integrated Moving Average、Prophet
任务:
使用ARMA/ARIMA/LSTM中任意一种对股票价格进行预测
矩阵分解与因子分解机
SVD、FunkSVD、BiasSVD、SVD++、FFM、deepFM、NFM、AFM
任务:
选择任意一张图片,对齐进行灰度化,然后使用SVD进行图像的重构,当奇异值数量为原有的1%,10%,50%时,输出重构后的图像
PageRank、图论与推荐系统
PageRank、TextRank、EdgeRank、PersonalRank、LPA、推荐系统
任务:
使用python模拟图上的PageRank计算过程,求每个节点的影响力
使用TextRank对新闻进行关键词提取,及文章摘要输出
强化学习与AlphaGo实战
强化学习(Reinforcement Learing)、马尔科夫、策略价值网络、蒙特卡罗法、AlphaGo、五子棋AI
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WXT0ahNH-1637712218959)(C:\Users\76437\AppData\Roaming\Typora\typora-user-images\image-20210729211810584.png)]
知识图谱
推荐资料
主要内容
知识提取
知识表示
知识存储
知识检索
项目实战:
基于知识图谱的问答
kgriculture Knowledge Graph
风控模型(评分卡模型)
推荐书籍
评分卡模型建模过程
项目列表
唐宇迪
新闻数据集文本分类
基于CycleGan开源项目实战图像合成
OCR文字识别项目
基于3D卷积的视频分析与动作识别
龙曲良
情感分类
吴恩达:
车辆识别
人脸识别和神经风格转换
词向量的运算与Emoji生成器
基础概念补充:
张量:
有序的标量形成向量,有序的向量形成矩阵,有序的矩阵形成3D张量,有序的3D张量形成4D张量。以此类推。关键在于顺序。在python中就是list中还有list
RMSE:均方根误差(Root-mean-square error)
MAE:平均绝对误差(Mean Absolute Error)
SD:常用的标准差(Standard Deviation)