confusionchart()混淆矩阵绘图函数介绍(MATLAB)
confusionchart()函数用于创建分类问题的混淆矩阵图
目录
confusionchart()函数用法:
描述:
示例1(通过trueLabels和predictedLabels创建混淆矩阵图):
示例2(通过现有的混淆矩阵创建混淆矩阵图):
示例3(按精度或召回率排序类):
confusionchart()函数用法:
confusionchart(trueLabels,predictedLabels)
confusionchart(m)
confusionchart(m,classLabels)
confusionchart(parent,___)
confusionchart(___,Name,Value)
cm = confusionchart(___)描述:
confusionchart(trueLabels,predictedLabels)
用真实标签trueLabel和预测标签predictedLabel创建一个混淆矩阵图,并返回一个ConfusionMatrixChart对象。混淆矩阵的行对应于真实类,列对应于预测类。对角线和非对角线单元格分别对应于正确和错误分类的观察结果。创建混淆矩阵图后,使用cm修改混淆矩阵图。有关属性列表,可以参阅ConfusionMatrixChart属性。
confusionchart(m)用数字混淆矩阵m创建混淆矩阵图。如果工作区中已经有了混淆矩阵,可以使用此语法。
confusionchart(m,classLabels)指定沿x轴和y轴出现的类标签。如果工作区中已有混淆矩阵和类标签,可以使用此语法。
confusionchart(parent,___)在指定的图形、面板或选项卡中创建混淆图。
confusionchart(___,Name,Value)使用一个或多个名称值对参数指定其他ConfusionMatrixChart属性。在所有其他输入参数之后指定属性。有关属性列表,可以参阅ConfusionMatrixChart属性。
cm=confusionchart(___)返回ConfusionMatrixChart对象。创建图表后,使用cm修改图表的属性。有关属性列表,可以参阅ConfusionMatrixChart属性。
示例1(通过trueLabels和predictedLabels创建混淆矩阵图):
创建混淆矩阵图,trueLabels是分类问题的真实标签,predictedLabels是预测标签
load('Cifar10Labels.mat','trueLabels','predictedLabels');
figure %创建混淆矩阵图
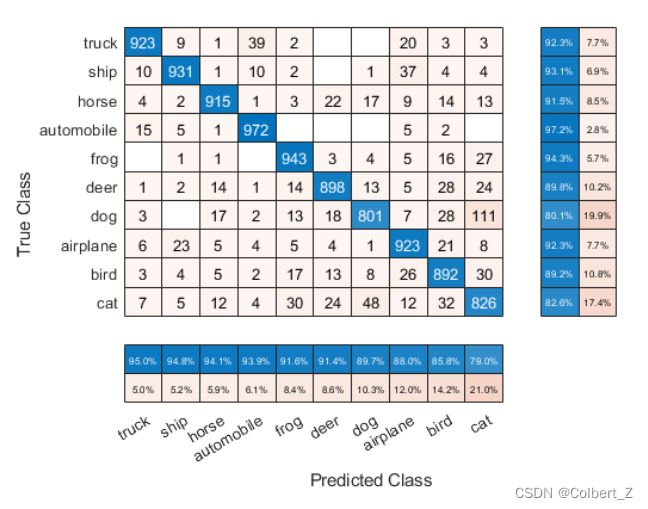
cm = confusionchart(trueLabels,predictedLabels);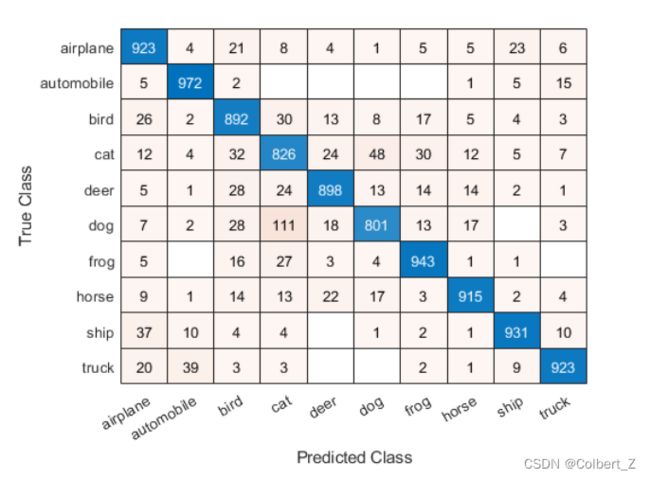
通过更改属性值或者添加列和行的摘要以及标题可以来修改混淆矩阵图的外观。
列规范化列摘要(column-normalized column summary)显示每个预测类别的正确和错误分类的观察值的数量,作为相应预测类别的观察值数量的百分比。
行规范化的行摘要(row-normalized row summary)显示每个真实类的正确和错误分类的观察值的数量,作为相应真实类的观察值数量的百分比。
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
cm.Title = 'CIFAR-10 Confusion Matrix';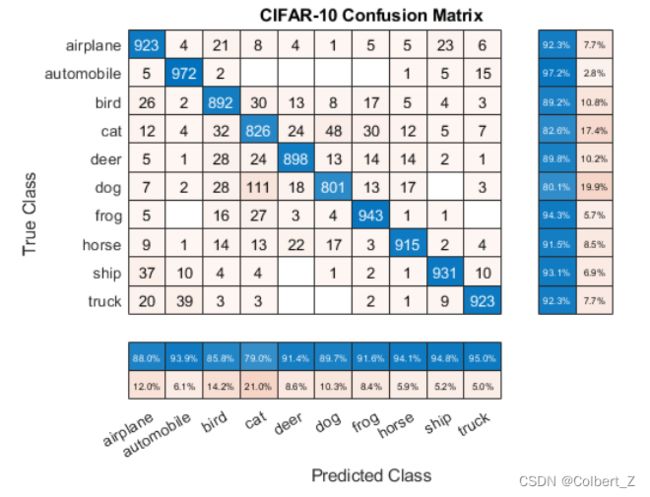
示例2(通过现有的混淆矩阵创建混淆矩阵图):
如果你的工作区里已经有了混淆矩阵m,你可以直接通过他创建混淆矩阵图。
加载示例混淆矩阵m和关联的类标签classLabels
load('Cifar10ConfusionMat.mat','m','classLabels');
m
classLabels是混淆矩阵侧面的标签名,需要是 categorical类型,可以通过以下方法转换为categorical类型。
classLabels
%%%%转换为categorical类型的演示代码
state ={'MA','ME','CT','VT','ME','NH','VT','MA','NH','CT','RI'};
state = categorical(state)这里使用了和混淆矩阵m阶数相同的classLabels。

建立混淆矩阵图
cm = confusionchart(m,classLabels);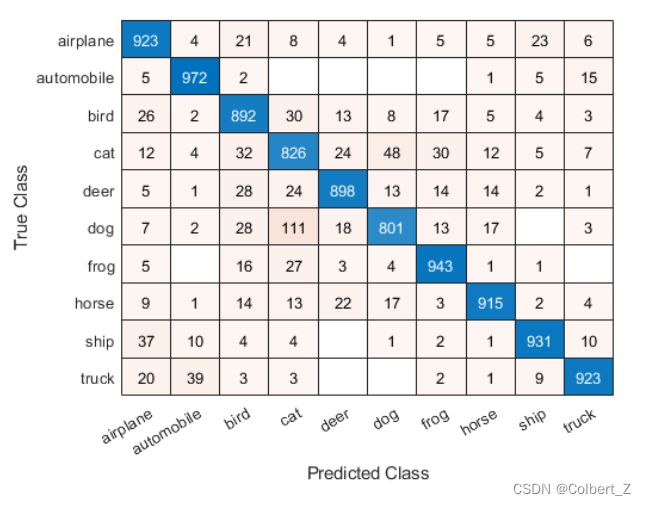
示例3(按精度或召回率排序类):
精度P(Precision) 召回率R(Recall)为评价指标
首先用示例1的方法创建混淆矩阵图
load('Cifar10Labels.mat','trueLabels','predictedLabels');
figure
cm = confusionchart(trueLabels,predictedLabels, ...
'ColumnSummary','column-normalized', ...
'RowSummary','row-normalized');
要按召回率R(Recall)对混淆矩阵的类进行排序,需要将每行中的单元格的值进行归一化,即按具有相同真实类(True Class)的观察值的数量进行归一化。根据相应的对角单元格值对类进行排序,并重置单元格值的标准化。现在对这些类进行排序,可以使右侧行摘要蓝色单元格中的数值按照百分比降序。
cm.Normalization = 'row-normalized';
sortClasses(cm,'descending-diagonal');
cm.Normalization = 'absolute';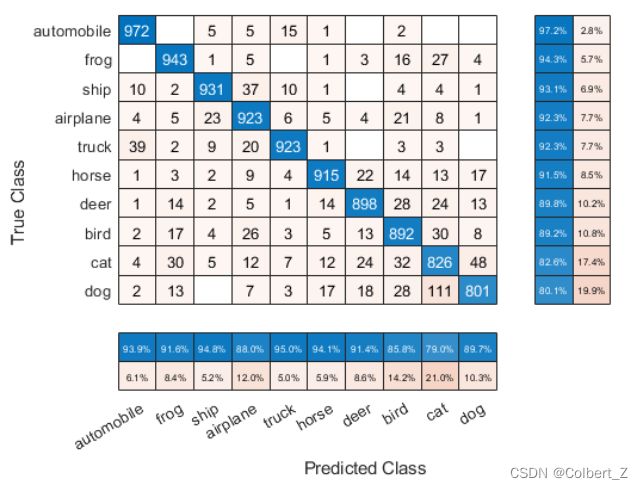
同样的,要按精度P(Precision)对混淆矩阵的类进行排序,需要将每列中的单元格值进行归一化,即按具有相同预测类(Predicted Class)的观察值的数量进行归一化。根据相应的对角单元格值对类进行排序,并重置单元格值的标准化。现在对这些类进行排序,可以使底侧行摘要蓝色单元格中的数值按照百分比降序。
cm.Normalization = 'column-normalized';
sortClasses(cm,'descending-diagonal');
cm.Normalization = 'absolute';