Instruct-UIE:信息抽取统一大模型

来自:FudanNLP
进NLP群—>加入NLP交流群
复旦大学自然语言处理实验室桂韬、张奇课题组发布信息抽取统一大模型 Instruct-UIE,在领域大模型上取得突破性进展。Instruct-UIE 在信息抽取精度上全面大幅度超越ChatGPT以及基于预训练微调的单一小模型。
自2022年11月 ChatGPT 横空出世以来,其在对话、阅读理解、对话、代码生成等方面优异性能,受到了极大的关注。大模型所展现出来的长文本建模能力以及多任务统一学习能力使得自然语言处理范式正在发生快速变革。
在对 GPT 系列工作进行了详细分析[1][2]后,我们发现虽然 ChatGPT 在很多任务上都展现出了良好的性能,但是在包括命名实体识别、关系抽取、事件抽取等在工业界有广泛应用的信息抽取任务上效果却亟待提升。ChatGPT 在某些命名实体识别数据集合上的的精度甚至只有不到20%。但是大模型所展示出来的多任务统一学习能力,驱使我们针对信息抽取领域的统一大模开展了深入研究。
访问 https://arxiv.org/abs/2304.08085
或点击 阅读原文 获取原文链接

实 验 结 果
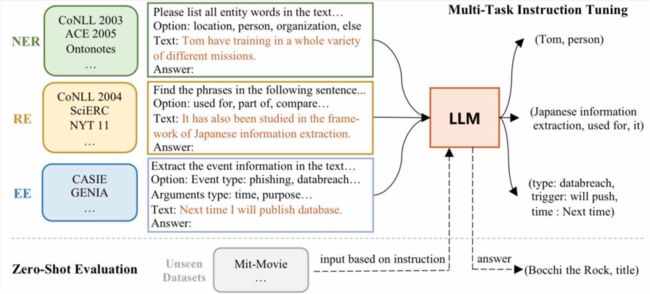
针对信息抽取任务,我们收集了包括 ACE 2005、ConLL 2003 等在内的41种评测集合,针对Flan-T5、Bloomz、LLama 等大模型进行了系统研究,构建了信息抽取统一大模型Instruct-UIE。该模型在绝大部分信息抽取任务中(85%以上)都超越了单个小模型的预训练微调结果。

Instruct-UIE 统一了信息抽取任务训练方法,可以融合不同类型任务以及不同的标注规范,统一进行训练。针对新的任务需求,仅需要少量的数据进行增量式学习,即可完成模型的升级。
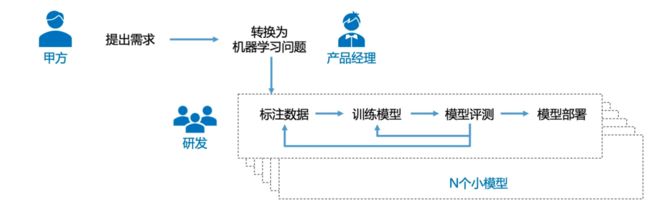
小模型时代任务,模型开发需要经过标注数据,训练模型,模型评测和模型部署等多个步骤。其显著缺点是成本高、时间周期长;相同任务的微小需求变化,需要30%-70%的重新开发成本;模型开发和维护成本高等问题都极大地制约了自然语言处理产品化。
而在大模型时代,我们可以将大量各类型任务,统一为生成式自然语言理解框架,并构造训练语料进行微调。由于大模型所展现出来的通用任务理解能力和未知任务泛化能力,使得未来自然语言处理的研究范式进一步发生变化。这样的研究范式使得小模型时代所面临的问题可以在一定程度上可以得到解决。针对新任务和需求,基于大模型的方法可以快速训练,并且不需要部署新的模型,从而实现自然语言处理的低成本产品化。

InstructUIE 工作验证了领域大模型的可行性,针对B端场景,百亿级领域模型具有高效、成本低、可私有化部署等优势,在行业应用中具有广阔前景。我们将近期开源相关代码和模型。
参考文献
[1] Junjie Ye, Xuanting Chen, Nuo Xu, Can Zu, Zekai Shao, Shichun Liu, Yuhan Cui, Zeyang Zhou, Chao Gong, Yang Shen, Jie Zhou, Siming Chen, Tao Gui, Qi Zhang, Xuanjing Huang. A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models, arXiv, March 18, 2023.
[2] Xuanting Chen, Junjie Ye, Can Zu, Nuo Xu, Rui Zheng, Minlong Peng, Jie Zhou, Tao Gui, Qi Zhang, Xuanjing Huang. How Robust is GPT-3.5 to Predecessors? A Comprehensive Study on Language Understanding Tasks, arXiv, March 1, 2023.
进NLP群—>加入NLP交流群(备注nips/emnlp/nlpcc进入对应投稿群)
加入星球,你将获得:
1. 每日更新3-5篇论文速读
2. 最新入门和进阶学习资料
3. 每日1-3个AI岗位招聘信息

责任编辑:窦士涵
▼点击"阅读原文"获取论文原文。