NLP学习笔记 36-word2vec
一 序
本篇属于贪心NLP训练营学习笔记系列。
二 词向量
one-hot encoding
问题:
- 稀疏sparse representation
- similarity (无法表达单词相似度 => 导致无法表达语义) ,可以表达句子相似性。
word2vec - distributed representation(把词的信息分布到各个向量中)
- Dense 稠密的(好处是低维的,数据量没有那么大)
- meaning (semantic space ,我们希望词关系比较密切的,再空间里比较近)
- capacity 表达能力:(one-hot表示有限,而分布式则大很多或者理论上无限大)
- Global generation(泛化能力,深度学习使用了参数共享(parameter sharing),,one-hot 局部泛化)
Word2Vec的Intuition
离得越近的单词,相似度越高。(即中心词与其上下文单词的语义接近,就是上下文单词是中心词前后window size个单词的集合)

Skip-Gram Model
CBOW: 根据上下文单词(左边两个单词和右边两个单词), 去预测中间那个单词
Skip-Gram:通过中间那个单词, 去预测上下文单词(常用)。

对于Skip-Gram model,通过中间词去预测上下文单词,也就是对应的条件概率最大。
![]()
这里的![]() ,里面的
,里面的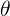 是加入的参数,含义跟
是加入的参数,含义跟![]() 一样。
一样。
- 其中w是中心词, c context(w)是上下文词
简化下,加log:
![]()
![]() ,其中u作为上下文的向量,V作为中心词的向量。参数维度是一样的,分开是因为同一个词在不同的角色(中心词、上下文词)的向量是不一样的。
,其中u作为上下文的向量,V作为中心词的向量。参数维度是一样的,分开是因为同一个词在不同的角色(中心词、上下文词)的向量是不一样的。
接下来看概率![]() 怎么求。
怎么求。
我们之前的假设是,中心词与它的上下文单词语义接近,也就是学得的向量相似度大。我们采用内积的方式表示相似度,我们用![]() 表示中心词的词向量,用
表示中心词的词向量,用![]() 表示上下文单词词向量。
表示上下文单词词向量。
 其中
其中 ![]() 词库
词库
其中分子是 内积(保证越近概率越大),分母是考虑所有词库的可能性。能保证概率p之合等于1. 式子就是一个简单的softmax。
苏剑林大神说过:
softmax 除了使概率分布合法(0-1),目的还是定义更合理的loss,最终的目的则是定义更合理的梯度;
为什么常用softmax,
是能将任意实数映射到非负实数的最简单的、单调的、光滑的初等函数.
softmax是sigmoid函数在多分类输出上的推广,对于
在二分类情况下与sigmoid函数等价,所以它是sigmoid函数在多分类上的扩展,有良好的物理意义。

因为要计算概率要遍历整个词典,见上面截图,计算复杂度过高。为了降低复杂度,引入了两个优化方式:层次Softmax(Hierarchical Softmax)和负采样(Negative Sampling)。
何为负采样?就是给定任意的两个![]() ,当它们出现时,
,当它们出现时,![]() 越大越好
越大越好
当它们不出现时,![]() 越大越好
越大越好
这就是类似于二分类的问题。可以套用公式:

负采样的目标函数
![]() 前面是正采样,后面是负采样
前面是正采样,后面是负采样
=![]()
=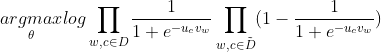
=
=![]()
这里把 看做
看做![]() ,后面怎么算的没看懂。
,后面怎么算的没看懂。

因为正样本的数量会远远少于负样本的数量,所以我们引入Nagetive Sampling,从正样本对应的负样本中随机采样来减少负样本的数量(不是所有的负样本)
![]()
解释如下:其中![]() 是针对中心词w的负样本采样后的集合。
是针对中心词w的负样本采样后的集合。

举例:

使用 梯度下降法对参数进行求解
![]()
这里用到了对于sigmoid函数求导结论,![]()
同理:
![]()
![\frac{ \partial L(\theta )}{ \partial v_w} =[1- \sigma (u_c\cdot v_w)]\cdot u_c +\sum _{c' \in N(w)} [\sigma (-u_{c'}\cdot v_w)-1 ]\cdot u_{c'}](http://img.e-com-net.com/image/info8/0007a131fbd84540bafcf081b2fa917d.gif)
上面知道后,求参数
![]()
![]()
![]()
伪代码如下:推荐去读源码,比如使用特定数据结构霍夫曼树

评估词向量:
1 TSNE 可视化词向量,对训练得到的词向量降维到二维空间进行观察
2 similarity:已有一个训练好的词向量和人工标记的单词相似度表。举例:football和basketball。
3类比(analogy):woman:man == boy:girl (如已知woman:man的相似性,给定boy来寻找girl)
词向量在推荐系统的应用
把词向量的训练,应用到产品的特性,学习出Embedding。认为用户浏览商品之间是连续类似的。
老师以Airbnb的论文为例介绍:
1 传统的内容推荐,
需要把房屋的属性,转换为向量的形式,也叫特征工程。
2 直接学出Embedding,房屋之间相似度用向量计算(与余弦相似度)。
接下来就是老师带领解析论文的改进之处了。我基础薄弱先跳过。

skipgram model 缺点
没有考虑到上下文;--->上下文的问题可以用Elmo和Bert解决;
窗口长度有限,无法考虑全局;--->考虑languagemodel,(RNN、LSTN)
未考虑全局:--》使用全局模型,(MF 矩阵分解)
无法有效学习低频词和未登录词OOV(out of vocabulary) --》subword embedding
其他怎么解决问题,TODO。再补充吧。