《Lua程序设计》--学习7
数据结构
数组
矩阵和多维数组
不规则数组:数组的数组,也就是所有元素均是另一个表的表

将两个索引合并为一个:声明一个长数组,然后根据 行数*行所拥有的元素个数+列数来访问这样

链表
因为表是动态对象,所以在Lua语言中可以很容易地实现链表
可以把每个节点用一个表来表示,链接则为一个包含指向其他表地引用的简单表字段
单链表:每个结点包含两个字value和next,如下代码在表头插入了一个值为v的元素

遍历链表:

队列及双端队列
使用table标准库中的函数 insert 和 remove,更高效的使用两个索引,一个指向第一个元素,一个指向最后一个元素
示例一个双端队列:
---[==[
function listNew( )
return {first = 0,last = -1}
end
function pushFirst( list,value )
local first = list.fist - 1
last.first = first
list[first] = value
end
function pushLast( list,value )
local last = list.last + 1
list.last = last
list[last] = value
end
function popFirst( list )
local first = list.first
if first > list.last then error("list is empty") end
local value = list[first]
list[first] = nil
list.first = first + 1
return value
end
function popLast( list )
local last = list.last
if list.first > last then error("list is empty") end
local value = list[last]
list[last] = nillist.last = lsat - 10return value
end
--]==]反向表


构造反向表
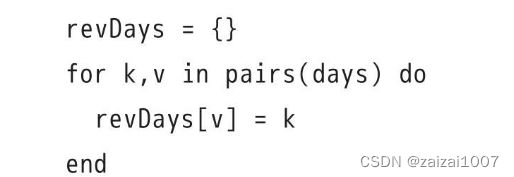
集合与包
假设我们想列出一个程序源代码中的所有标识符,同时过滤掉其中的保留字。一些C程序员可能倾向于使用字符串数组来表示保留字集合,然后搜索这个数组来决定某个单词是否属于该集合。为了提高搜索的速度,他们还可能会使用二叉树来表示该集合。
在Lua语言中,还可以用一种高效且简单的方式来表示这类集合,即将集合元素作为索引放入表中。那么,对于指定的元素无须再搜索表,只需用该元素检索表并检查结果是否为nil即可。以上述需求为例,代码形如:

我们可以借助一个辅助函数来构造集合,使得初始化过程更清晰:

包(bag),也被称为多重集合(multiset),与普通集合的不同之处在于其中的元素可以出现多次。在Lua语言中,包的简单表示类似于此前集合的表示,只不过其中的每一个键都有一个对应的计数器。如果要插入一个元素,可以递增其计数器:

如果要删除一个元素,可以递减其计数器:

只有当计数器存在且大于0时我们才会保留计数器。
字符串缓冲区
假设我们正在开发一段处理字符串的程序,比如逐行地读取一个文件。典型的代码可能形如

这种的运行起来非常慢,因为每读一行就需要重新写一个buff,将所有数据复制过去
推荐方式:

我们可以把一个表当作字符串缓冲区,其关键是使用函数table.concat,这个函数会将指定列表中的所有字符串连接起来并返回连接后的结果
图形
使用对象来表示节点(实际上是表)、将边(arc)表示为节点之间的引用。
我们使用一个由两个字段组成的表来表示每个节点,即name(节点的名称)和adj(与此节点邻接的节点的集合)。由于我们会从一个文本文件中加载图对应的数据,所以需要能够根据节点的名称来寻找指定节点的方法。因此,我们使用了一个额外的表来建立节点和节点名称之间的映射。函数name2node可以根据指定节点的名称返回对应的节点:


该函数逐行地读取一个文件,文件的每一行中有两个节点的名称,表示从第1个节点到第2个节点有一条边。对于每一行,调用函数string.match将一行中的两个节点的名称分开,然后根据名称找到对应的节点(如果需要的话则创建节点),最后将这些节点连接在一起。
寻找两个节点之间的路径的算法

函数findpath使用深度优先遍历搜索两个节点之间的路径。该函数的第1个参数是当前节点,第2个参数是目标节点,第3个参数用于保存从起点到当前节点的路径,最后一个参数为所有已被访问节点的集合(用于避免回路)
数据文件和序列化
数据文件
我们把每条数据记录表示为一个Lua构造器

Entry{code}与Entry({code})是相同的,后者以表作为唯一的参数来调用函数Entry
因此,上面这段数据也是一个Lua程序。当需要读取该文件时,我们只需要定义一个合法的Entry,然后运行这个程序即可。例如,以下的代码用于计算某个数据文件中数据条目的个数

当文件的大小并不是太大时,可以使用键值对的表示方法,这种格式是所谓的自描述数据(self-describing data)格式,其中数据的每个字段都具有一个对应其含义的简略描述,可读性会好一点


序列化
我们常常需要将某些数据序列化\串行化,即将数据转换为字节流或字符流,以便将其存储到文件中或者通过网络传输。我们也可以将序列化后的数据表示为Lua代码,当这个代码运行时,被序列化的数据就可以在读取程序中得到重建
